Grafana10.x新版本图形使用二
#紧接上文,我们继续学习其他的常用图形
一、Grafana使用Prometheus
1.1 跟着官网学变量
#template variables改动还是挺多的跟着官网学习一下
Use query variables:
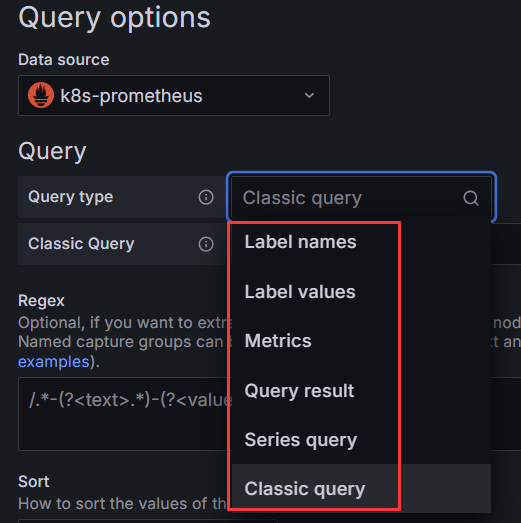
以选择使用几种不同的变量类型,但是Query类型的变量将向Prometheus查询metrics, labels, label values, a query result or a series(指标、标签、标签值、查询结果或一系列)的列表。选择Prometheus数据源查询类型并输入所需的输入:
#Query Type Input(* required) Description Used API endpoints #这是要介绍的四段内容 Label names:metric 返回与指定度量正则表达式匹配的所有标签名称的列表。 /api/v1/labels Label values:label*, metric 返回所有指标或可选指标中标签的标签值列表。/api/v1/label/label/values or /api/v1/series Metrics:metric 返回与指定度量正则表达式匹配的度量列表。 /api/v1/label/__name__/values Query result:query 返回查询的Prometheus查询结果列表。 /api/v1/query Series query:metric, label or both 返回与输入数据关联的时间序列列表。 /api/v1/series Classic query:classic query string 已弃用,变量查询编辑器的经典版本。使用如下语法输入具有查询类型的字符串:label_values(<metric>, <label>) all
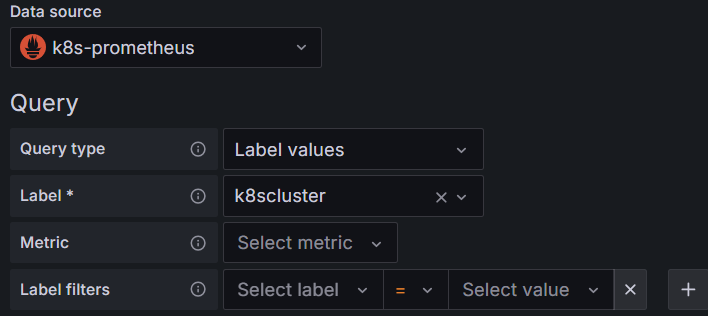
比如原来我们的变量:获取k8s集群列表的变量为Query:label_values(k8scluster)
现在变为下图:
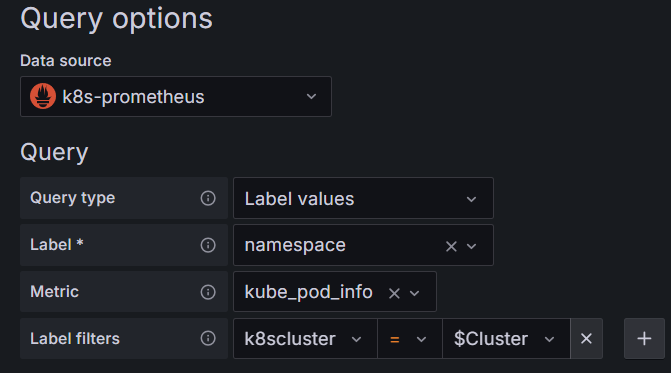
再复杂一点,借助获取到的k8s cluster集群拿到每个集群的namespace,原来是:label_values(kube_pod_info{k8scluster="$Cluster"}, namespace)
现在变为下图的:
#当然如果你还是喜欢使用PromQL语句,Query type可以选择Series query类型
1.2 先跟着官网简单了解下Stat
stat可视化以单个感兴趣的值显示数据,例如一个系列的最新值或当前值。
Use a stat visualization when you need to:
一目了然地监视关键指标,例如应用程序的最新运行状况、应用程序中高优先级错误的数量或总销售额。 显示聚合数据,例如服务的平均响应时间。 突出显示高于正常阈值的值,以快速识别是否有任何指标超出了预期范围。
统计可视化支持多种显示数据的格式。支持的格式包括:
Single values - 最常见的格式,可以是数值、字符串或布尔值。 Time-series data - 可以将计算类型应用于时间序列数据,以显示指定时间范围内的单个值。
Stat styles
Orientation(取向)
选择堆叠方向。
Auto:Grafana选择它认为最好的方向。 Horizontal:水平拉伸,从左到右。 Vertical:垂直拉伸,从上到下。
Text mode(文本模式)
可以使用Text模式选项来控制可视化呈现的文本。如果值不重要,只有名称和颜色重要,则将“Text mode”更改为“Name”。该值仍将用于确定颜色,并显示在工具提示中。
Auto:如果数据包含多个系列或字段,则同时显示名称和值。 Value:只显示值,不显示名称。名称将显示在悬停工具提示中。 Value and name:始终显示值和名称。 Name:显示名称而不是值。值显示在悬停工具提示中。 None:不显示任何内容(空)。名称和值将显示在悬停工具提示中。
Color mode(颜色模式)
None #不给值应用颜色 Value #给值和应用区域应用颜色 Background Gradient #背景颜色渐变,将颜色应用于值、图形区域和背景,并带有轻微的背景渐变。 Background Solid #将颜色应用于值、图形区域和背景,背景色为纯色。
Graph mode(图模式)
选择graph and sparkline得模式
None #隐藏的图形,只显示值 Area #显示值下方的面积图。这要求你的查询返回一个时间列。
Text alignment(文本对齐方式)
选择一种对齐方式。
Auto #如果只显示一个值(不重复),则该值居中。如果显示多个序列或行,则该值为左对齐。 Center #统计值居中
Show percent change(显示百分比变化)
设置是否显示更改百分比。默认为关闭。
Text size
Title #输入仪表标题大小的数值 Value #输入仪表值大小的数值
Standard options(规格的选择)
面板编辑器窗格中的标准选项允许你更改字段数据在可视化中的显示方式。当你设置标准选项时,更改将应用于所有字段或系列。可以自定义以下标准选项:
Unit #选择字段应该使用的单位 Min/Max #设置百分比阈值计算中使用的最小和最大值,或者将这些字段保留为空,以便自动计算 Field min/max #启用Field min/max让Grafana根据字段的最小值或最大值单独计算每个字段的最小值或最大值 Decimals #指定Grafana在渲染值中包含的小数位数 Display name #设置所有字段的显示标题。可以在字段标题中使用变量 Color scheme #为整个可视化设置单个或多个颜色 No value #如果字段值为空或为null,请输入Grafana应显示的内容。默认值为连字符(-)
Data links(数据链接)
数据链接允许你链接到其他面板、面板和外部资源,同时维护源面板的上下文。你可以创建包含系列名称甚至光标下的值的链接。对于每个数据链接,设置以下选项:
Title URL Open in new tab
Value mappings(值的映射)
值映射是一种可以用于更改数据在可视化中的显示方式的技术。对于每个值映射,设置以下选项:
Condition #选择映射到显示文本和(可选的)颜色的内容:Value、Range、Regex、Special(特殊值如 Null, NaN (not a number), or布尔值如true或false) Display text Color (可选) Icon (仅限Canvas)
Thresholds(阈值)
阈值是你为指标设置的值或限制,当达到或超过该值时,会在视觉上反映出来。阈值是一种可以根据查询结果有条件地设置可视化样式和颜色的方法。设置以下选项:
Value #设置每个阀值的值 Thresholds mode(阀值的模式选择):Absolute(绝对值)和Percentage(百分比)
Field overrides(字段覆盖)
覆盖允许你自定义特定字段或系列的可视化设置。当你添加覆盖规则时,它针对一组特定的字段,并允许你为该字段的显示方式定义多个选项。选择以下覆盖选项之一:
Fields with name #从所有可用字段的列表中选择一个字段 Fields with name matching regex #指定要用正则表达式覆盖的字段 Fields with type #按类型选择字段,如字符串、数字或时间 Fields returned by query #选择查询返回的所有字段,如A、B或C Fields with values #选择由定义的reducer条件返回的所有字段,例如Min, Max, Count, Total
1.3 创建一个Stat图形
#下面是一个出图例子:
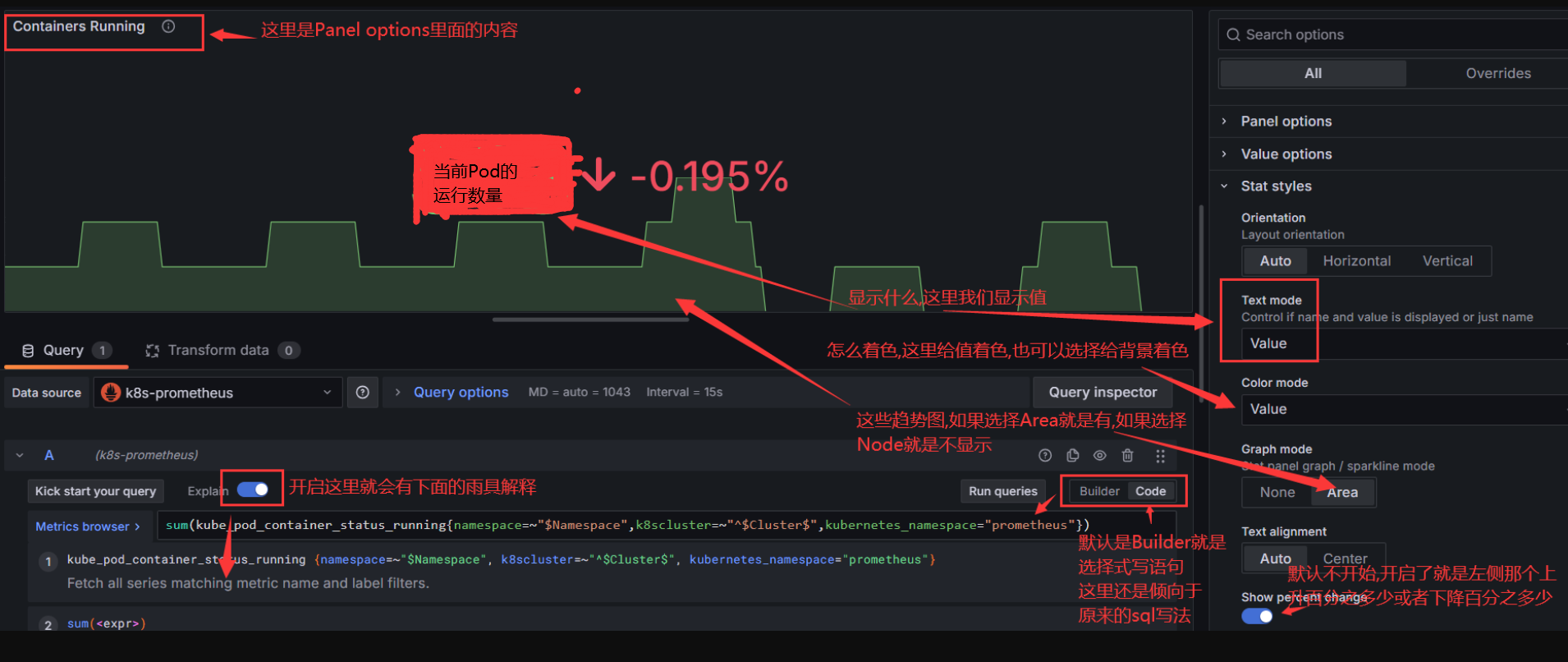
#Color scheme选择Classic palette或者去Thresholds里面去掉阀值上限只留Base,图中的value颜色就不会随着阀值而改变了,看用途。
#下面是一个关于pod运行状态的出图展示(通过图形可以一目了然了解当然pod得运行状态)
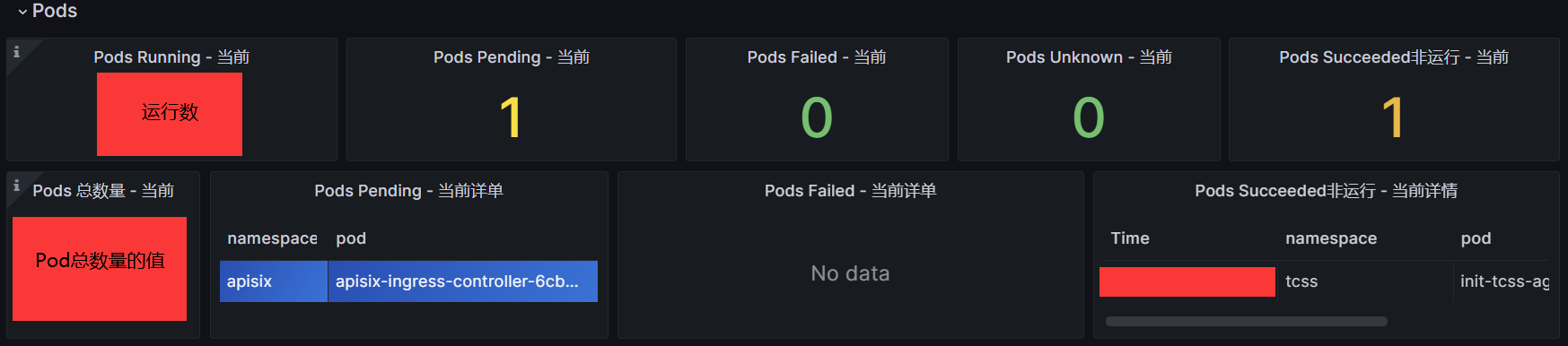
博文来自:www.51niux.com
1.4 创建一个Text 图形
#比方说你想在dashboard面板中添加一个介绍,点击就能跳转到你制定的URL,就可以用这个:
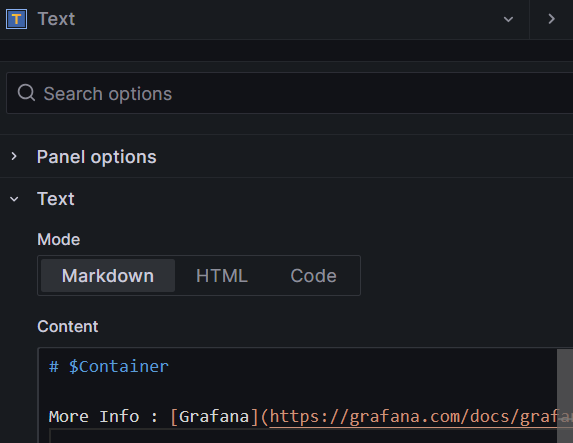
Mode(决定嵌入内容的显示方式):
Markdown #此选项将内容格式化为markdown HTML #该设置将内容呈现为经过处理的HTML Code #此设置在只读代码编辑器中呈现内容。选择适当的语言对嵌入文本应用语法高亮显示。
二、使用Table图形
#这是一个很重要的图标还是单开一个章节进行介绍吧
2.1 跟着官网了解一下都有哪些选项
表格非常灵活,支持时间序列、表、注释和原始JSON数据的多种模式。table中目前不支持注释和警报。
列排序:单击列标题可将排序顺序从默认的降序更改为升序。每次单击时,排序顺序将更改为循环中的下一个选项。按住shift键并单击列名,可以对多个列进行排序。
Table options(表格选项)
Show header:显示或隐藏从数据源导入的列名。
Cell height: 单元格高度(Small/Medium/Large)
Enable pagination:启用分页,默认是关闭状态
Column width:列宽,默认情况下,Grafana根据表大小和最小列宽度自动计算列宽度。输入数字比如100那么列就被设置为100像素宽。
Minimum column width:最小列宽,默认是150像素。
Column alignment:列对齐,Auto (default)/Left/Center/Right
Column filter:列过滤器,可以临时更改列数据的显示方式。例如,可以将值从高到低排序或隐藏特定值。
Table footer(表页脚)
Show table footer: 选择要计算的字段,如果不选择字段,系统会将计算应用于所有数字字段。
Fields: 选择要计算的字段,去计算total总数
Cell options(单元格选项)
Cell type: 单元格类型,默认情况下,Grafana自动选择显示设置
Sparkline #显示渲染为迷你图的值 Color text #颜色的文本,如果设置了阈值,则字段文本将以适当的阈值颜色显示 Color background (gradient or solid) #背景色(渐变或纯色)如果设置了阈值,则字段背景将以适当的阈值颜色显示 Gauge #单元格可以显示为图形度量 Data links #数据链接 JSON view #JSON视图 Image #如果字段值是图像URL或base64编码的图像,则可以配置表以将其显示为图像。
Cell value inspect:启用表单元格中的值检查。原始值显示在模式窗口中。
#后面得选项参照上个图形的介绍吧,一样。
2.2 跟着官网学习Transform data(非常重要建议看完)
转换是在系统应用可视化之前处理查询返回的数据的一种强大方法。使用转换,你可以:
重命名字段 加入时间序列数据 跨查询执行数学运算 将一个变换的输出用作另一个变换中的输入
对于依赖同一数据集的多个视图的用户来说,转换提供了一种创建和维护大量仪表板的有效方法。还可以使用一个转换的输出作为另一个变换的输入,这样可以提高性能。有时系统无法绘制转换后的数据。发生这种情况时,单击可视化上方的"Table view"切换,切换到数据的表视图。这可以帮助你了解转换的最终结果。
Order of transformations(转换顺序)
当存在多个转换时,Grafana会按照列出的顺序应用它们。每个转换都会创建一个结果集,然后将其传递给处理管道中的下一个转换。
Grafana应用转换的顺序直接影响结果。例如,如果使用Reduce转换将一列的所有结果压缩为单个值,则只能将转换应用于该单个值。
Debug a transformation(调试转换)
要查看转换的输入和输出结果集,请单击转换行右侧的bug(常见的爬虫)图标。输入和输出结果集可以帮助你调试转换。
Disable a transformation(禁用转换)
通过单击变换行右上角的眼睛图标,可以禁用或隐藏一个或多个变换。这将禁用该特定转换的应用操作,并有助于在相继更改多个转换时识别问题。
#下面是Transformation functions(转换函数)的介绍
官方链接:https://grafana.com/docs/grafana/latest/panels-visualizations/query-transform-data/transform-data/
Add field from calculation(从计算中添加字段)
Mode(模式)-选择下面的一种类型:
Reduce row:对选定字段的每一行独立应用选定的计算。
Binary operation:二进制运算,对两个选定字段中的单行值应用基本二进制运算(例如求和或乘法)
Unary operation:对选定字段中的单行值应用基本一元运算。可用的操作包括:
Absolute value (abs): 返回给定表达式的绝对值。它将其与零的距离表示为正数 Natural exponential (exp):自然指数,返回e的幂 Natural logarithm (ln): 返回给定表达式的自然对数 Floor (floor): 返回小于或等于给定表达式的最大整数 Ceiling (ceil):返回大于或等于给定表达式的最小整数
Cumulative functions:累积函数,将函数应用于当前行和之前的所有行。
Total:计算截至当前行(包括当前行)的累计总计 Mean:计算当前行(包括当前行的平均值。
Window functions:应用窗口函数。窗口可以是尾部的,也可以是居中的。对于尾随窗口,当前行将是窗口中的最后一行。使用居中窗口时,窗口将位于当前行的中心。对于偶数窗口大小,窗口将位于当前行和前一行之间的中心。
Mean:计算移动平均值或运行平均值 Stddev:计算移动的标准偏差 Variance: 计算移动方差
Row index:插入具有行索引的字段
Field name: 选择要在新字段的计算中使用的字段名称
Calculation(计算): 如果选择减少行模式,则显示计算字段。在字段中单击以查看可用于创建新字段的计算选项列表。
Operation(操作): 如果选择二进制操作或一元操作模式,则出现操作字段。这些字段允许您对选定字段中的单行值应用基本的数学运算。
As percentile(百分位数): 如果选择行索引模式,则显示As百分位数开关。此开关允许将行索引转换为行总数的百分比。
Alias(别名):(可选)输入新字段的名称。如果你将此留空,则将命名该字段以匹配计算结果。
Replace all fields(替换所有字段):(可选)如果您想隐藏所有其他字段,并在可视化中仅显示计算的字段,请选择此选项。
Concatenate fields(连接字段)
使用此转换将所有帧中的所有字段合并为一个结果。这种转换简化了合并来自不同来源的数据的过程,为分析和可视化提供了一个全面的视图。
Config from query results(查询结果配置)
使用此转换来选择查询并提取标准选项,例如Min、Max、Unit和Thresholds,并将它们应用于其他查询结果。此特性支持基于特定查询返回的数据进行动态可视化配置。
Config query(配置查询):选择返回要用作配置的数据的查询
Apply to(应用到):选择配置应用到的字段或系列
Apply to options(应用到选项): 根据你在应用于中的选择,指定字段类型或使用字段名称正则表达式
Convert field type(转换字段类型)
使用此转换来修改指定字段的字段类型。这个转换有以下选项:
Field:从可用字段中选择
as:选择要转换为的FieldType
Numeric: 尝试将值变为数字 String: 将值变成字符串 Time: 尝试将值解析为时间,将显示一个选项,指定一个日期格式输入的字符串,如yyyy-mm-dd or DD MM YYYY hh:mm:ss Boolean:将值变为布尔值 Enum:将值设为枚举 Other:尝试将值解析为JSON
Extract fields(提取字段)
使用此转换可以选择数据源并从中提取不同格式的内容。此转换具有以下字段:
Source:选择数据来源的字段
Format:选择下列之一
JSON:从源解析JSON内容 Key+value pairs:分析源中格式为“a=b”或“c:d”的内容 Auto:自动发现字段
Replace All Fields(替换所有字段): (可选)选择此选项可隐藏所有其他字段,并在可视化中仅显示计算字段。
Keep Time: (可选)仅当“替换所有字段”为true时可用。在输出中保留时间字段。
Lookup fields from resource(资源中查找字段)
使用此转换可以通过从外部源查找其他字段来丰富字段值。此转换具有以下字段:
Field:从数据集中选择一个文本字段 Lookup:从国家/地区、美国各州和机场中进行选择。此转换当前支持空间数据。
Filter data by query refId
使用此转换可以在具有多个查询的面板中隐藏一个或多个查询。Grafana以深灰色文本显示查询标识字母。单击查询标识符可切换过滤。如果查询字母为白色,则显示查询结果。如果查询字母是暗的,那么结果是隐藏的。
注意:此转换不适用于Graphite,因为该数据源不支持将返回的数据与查询关联起来。
Filter data by values(按值筛选数据)
使用此转换可以直接在可视化中选择性地过滤数据点。此转换提供了基于应用于选定字段的一个或多个条件来包括或排除数据的选项。
如果数据源不按值进行本机筛选,则此转换非常有用。如果使用共享查询,也可以使用此选项来缩小要显示的值。
所有字段的可用条件为:
Regex:匹配一个正则表达式 Is Null:如果值为空,则匹配 Is Not Null:如果值不为空,则匹配 Equal:如果值与指定值相等,则匹配 Different:如果值与指定值不同,则匹配
字符串字段的可用条件有:
Contains substring:包含指定的子字符串时匹配(不区分大小写) Does not contain substring:如果值不包含指定的子字符串,则匹配(不区分大小写)
数字字段的可用条件为:
Greater:如果值大于指定值,则匹配 Lower:如果值低于指定值,则匹配 Greater or equal:如果值大于或等于,则匹配 Lower or equal:小于等于时匹配 Range:匹配指定的最小值和最大值之间的范围,包括最小值和最大值
Filter fields by name(按名称筛选字段)
使用此转换可以选择性地删除部分查询结果。有三种方法可以过滤字段名称:
使用正则表达式 手动选择包含的字段 使用仪表板变量
Format string(设置字符串格式)
使用此转换可以自定义字符串字段的输出。此转换具有以下字段:
Upper case:用大写字符格式化整个字符串 Lower case:用小写字符格式化整个字符串 Sentence case:将字符串的第一个字符格式化为大写 Title case:以大写形式格式化字符串中每个单词的第一个字符 Pascal case:将字符串中每个单词的第一个字符格式化为大写,并且不包括单词之间的空格 Camel case:将字符串中每个单词的第一个字符(第一个单词除外)设置为大写,并且不包括单词之间的空格 Snake case:将字符串中的所有字符格式化为小写,并使用下划线而不是单词之间的空格 Kebab case:将字符串中的所有字符格式化为小写,并在单词之间使用破折号而不是空格 Trim:从字符串中删除所有前导空格和尾部空格 Substring:使用指定的开始和结束位置返回字符串的子字符串
Format time(时间格式)
使用此转换自定义时间字段的输出。输出可以使用Moment.js格式字符串进行格式化。
Group by
使用此转换按指定字段(列)值对数据进行分组,并对每个组进行计算。这种转变分为两个步骤。首先,指定一个或多个字段进行数据分组。这将把这些字段的所有相同值分组在一起,就像对它们进行排序一样。
Grouping to matrix(分组到矩阵)
使用此转换可以组合三个字段(用作查询输出中Column、Row和Cell值字段的输入),并生成一个矩阵。
Group to nested table(分组到嵌套表)
使用此转换可以按指定的字段(列)值对数据进行分组,并处理每个组的计算。将生成共享相同分组字段值的记录,这些记录将显示在嵌套表中。
Create heatmap(创建热图)
使用此转换来准备直方图数据,以便随着时间的推移可视化趋势。与热图可视化类似,这种转换将直方图度量转换为时间桶。
X Bucket
这个设置决定了如何将x轴分割成桶。
Size:在输入字段中指定一个时间间隔。例如,时间范围'1h'在x轴上创建一个小时宽的单元格。 Count:对于非时间相关的序列,使用此选项定义bucket中的元素数量。
Y Bucket
该设置决定如何将y轴划分为桶。
Linear Logarithmic:选择以2为底的对数或以10为底的对数 Symlog:使用对称的对数刻度。选择以2为底的对数或以10为底的对数,允许负值。
Histogram(直方图)
使用此转换生成基于输入数据的直方图,使你能够可视化值的分布。
Bucket size:桶中最小和最大项之间的范围(xMin到xMax) Bucket offset:非从零开始的桶的偏移量 Combine series:使用所有可用的系列创建统一的直方图
Join by field(按字段加入)
使用此转换可以将多个结果合并到一个表中,从而可以合并来自不同查询的数据。这对于将多个时间序列结果转换为具有共享时间字段的单个宽表特别有用。
Inner join
内部连接合并来自多个表的数据,其中所有表共享所选字段的相同值。这种类型的连接排除了值在每个结果中都不匹配的数据。
使用此转换将来自多个查询的结果(在传递的连接字段或第一个时间列上进行组合)合并为一个结果,并删除无法成功连接的行。
Outer join
外部连接包括来自内部连接的所有数据以及在每个输入中值不匹配的行。虽然内部连接在时间字段上连接查询A和查询B,但外部连接包括在时间字段上不匹配的所有行。
Join by labels
使用此转换将多个结果连接到单个表中。这对于将多个时间序列结果转换为具有共享Label字段的单个宽表特别有用。
Join: 选择要在所有时间序列中可用或通用的标签之间连接的标签 Value: 输出结果的名称
Labels to fields(字段标签)
使用此转换将带有标签或标记的时间序列结果转换为表,包括结果中每个标签的键和值。将标签显示为列值或行值,以增强数据可视化。
Mode:分为Columns(列模式)和Rows(行模式)
Value field name:如果选择了标签名,此标签的每一个值都会获得一个字段
Merging behavior:标签到字段转换器在内部是两个独立的转换。第一个作用于单个序列并提取字段的标签。第二种是合并转换,将所有结果连接到一个表中。合并转换尝试对所有匹配的字段进行联接。此合并步骤是必需的,不能关闭。
Limit
使用此转换来限制显示的行数,从而提供更集中的数据视图。这在处理大型数据集时特别有用。
Merge series/tables
使用此转换将多个查询的结果合并为单个结果,这在使用表面板可视化时特别有用。如果共享字段包含相同的数据,则此转换将值合并到同一行中。
Organize fields by name(按名称组织字段)
使用此转换可以灵活地重命名、重新排序或隐藏面板中单个查询返回的字段。此转换仅适用于具有单个查询的面板。
Transforming fields:
Grafana显示查询返回的字段列表,允许你执行以下操作:
Change field order:更改字段顺序,将鼠标悬停在字段上,当光标变为手形时,将字段拖动到其新位置 Hide or show a field:隐藏或显示字段,使用字段名称旁边的眼睛图标来切换特定字段的可见性 Rename fields:重命名字段,在“Rename”框中键入新名称以自定义字段名称。
Partition by values(按值划分)
使用此转换可以简化绘制多个序列的过程,而不需要使用不同的' WHERE '子句进行多个查询。这在处理度量SQL表时特别有用。
Prepare time series(配置时间序列)
当数据源以与所需可视化不兼容的格式返回时间序列数据时,使用此转换可以解决问题。这种转换允许你在长/宽格式之间转换时间序列数据,从而提供数据帧结构的灵活性。
Format可用选项
Multi-frame time series:使用此选项可将时间序列数据帧从宽格式转换为长格式。 Wide time series:选择此选项可将时间序列数据帧从长格式转换为宽格式
Reduce
使用此转换可以对数据帧中的每个字段应用计算并返回单个值。这种转换对于将多个时间序列数据合并为更紧凑、汇总的格式特别有用。
Mode:
Series to rows:为每个字段创建一行,为每个计算创建一列 Reduce fields: 保留现有的帧结构,但将每个字段折叠为一个值。
Rename fields by regex(按正则表达式重命名)
使用此转换使用正则表达式和替换模式重命名查询结果的部分。
Rows to fields
使用此转换可以将行转换为单独的字段。默认情况下,转换使用第一个字符串字段作为源。可以通过选择要使用的字段的"Use as column"列中的值覆盖默认值。
将额外的字段映射到标签,如果一个字段没有映射到配置属性,Grafana将自动使用它作为输出字段-标签的源。
Series to rows
使用此转换将多个时间序列数据查询的结果合并为一个结果。此转换的结果将包含三列:Time、Metric和Value。
Sort by
使用此转换可以根据指定字段对查询结果中的每个帧进行排序,使数据更易于理解和分析。通过配置所需的排序字段,可以控制数据在表或可视化中的显示顺序。
Time series to table
使用此转换可将时间序列结果转换为表,将时间序列数据帧转换为趋势字段,然后该字段可用于sparkline单元格类型。如果有多个时间序列查询,每个查询都将产生一个单独的表数据帧。可以使用联接或合并转换来联接这些表,以生成每行具有多个迷你图的单个表。
Regression analysis(回规分析)
使用此转换创建包含统计模型预测值的新数据框架。这对于在混沌数据中寻找趋势是有用的。它通过使用线性或多项式回归将数学函数拟合到数据中来工作。然后可以在可视化中使用数据框架来显示趋势线。
有两种不同的模式:
Linear regression: 线性回归,拟合数据的线性函数 Polynomial regression:多项式回归,将多项式函数拟合到数据中
2.3 用2个例子说明一下Transform data
博文来自:www.51niux.com
#理论确实是枯燥的,但是是实践的基础,下面用一些例子展示几个常用的用法
例子1:我们想展示容器重启的详情(promtheus数据源)
没使用transform函数前的效果展示(这显然不是我们想要的效果,我们希望展示每个pod重启的次数):
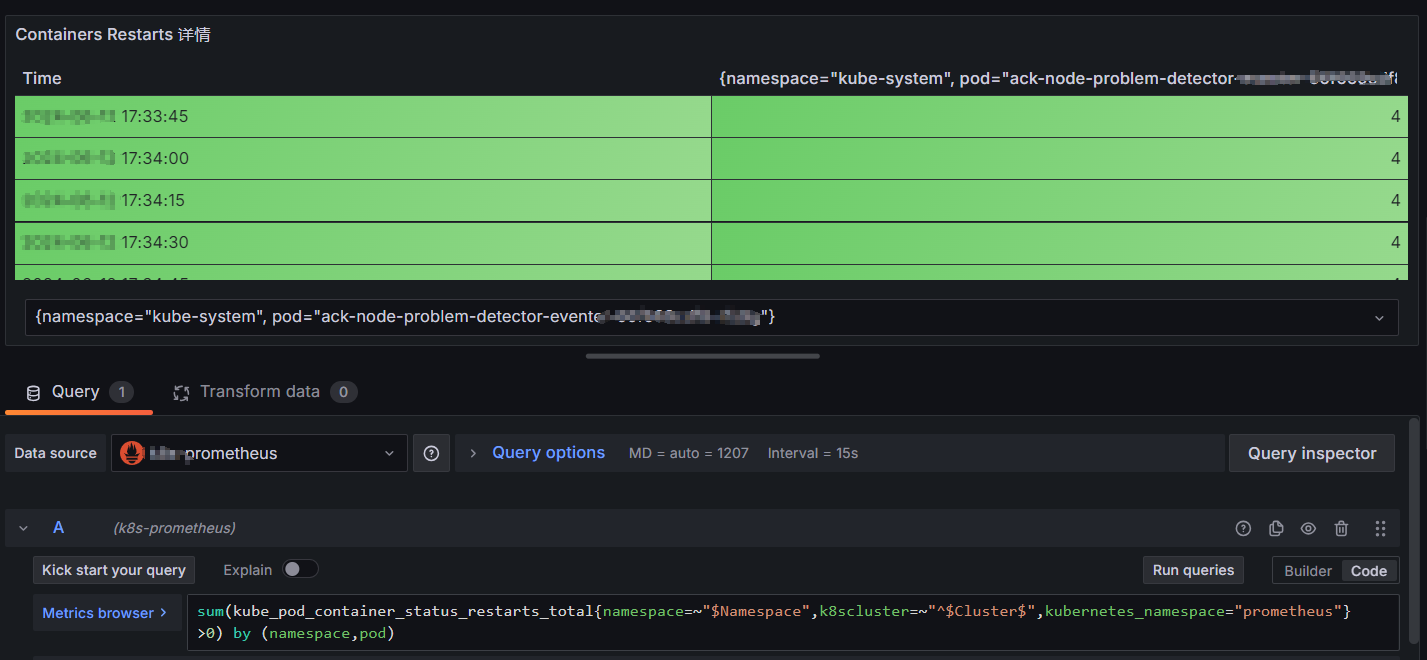
使用transform函数后的效果展示:
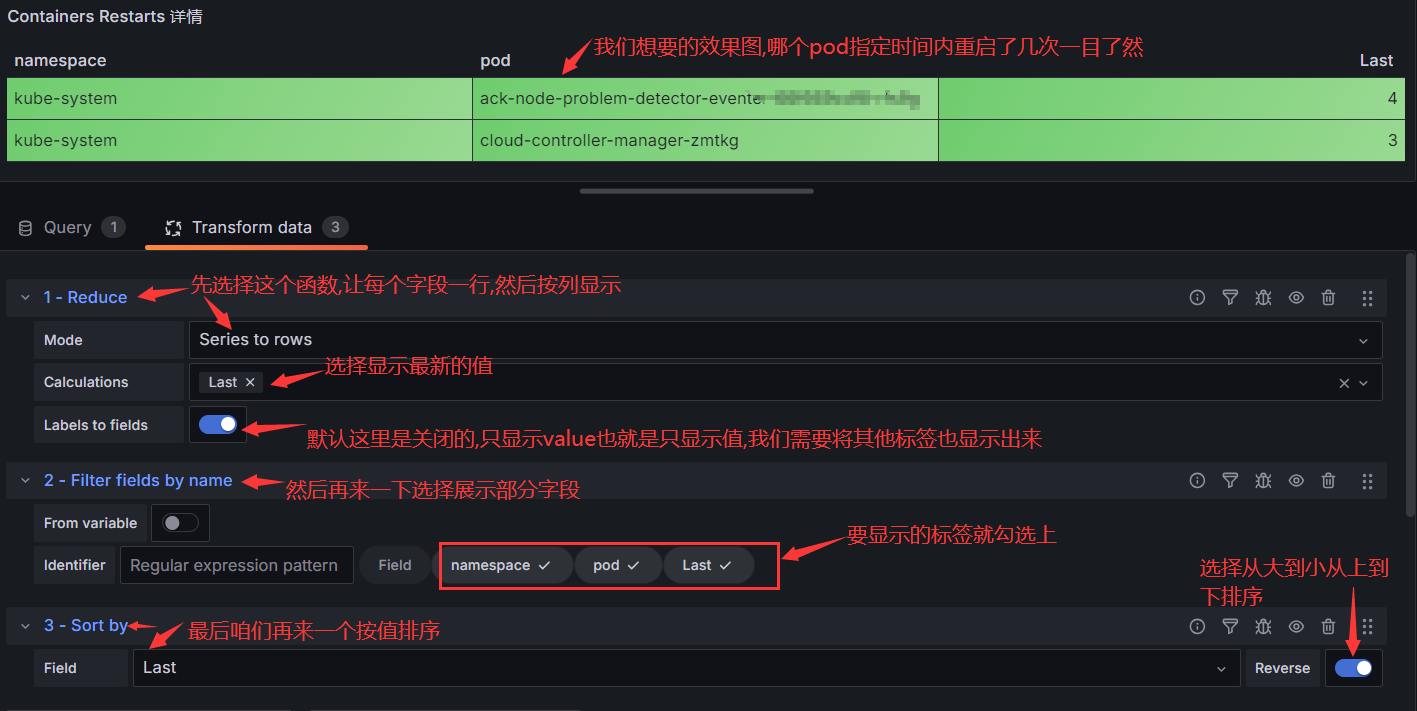
#上图中我们一下子用了三个函数的组合:Reduce/Filter fields by name/Sort by 这也是很常用的转换函数
#你说我想换成方式,想看看能实现吗?当然可以,各种组合白。请看下图:
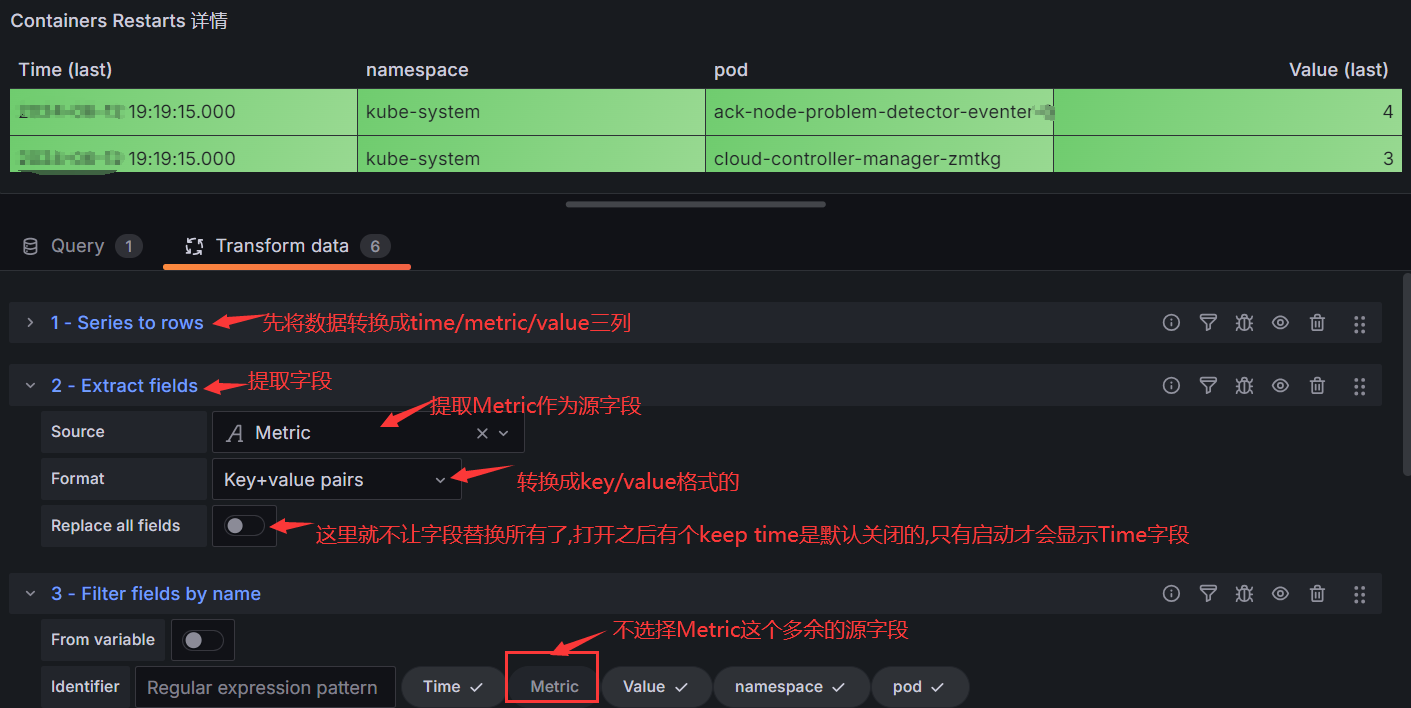
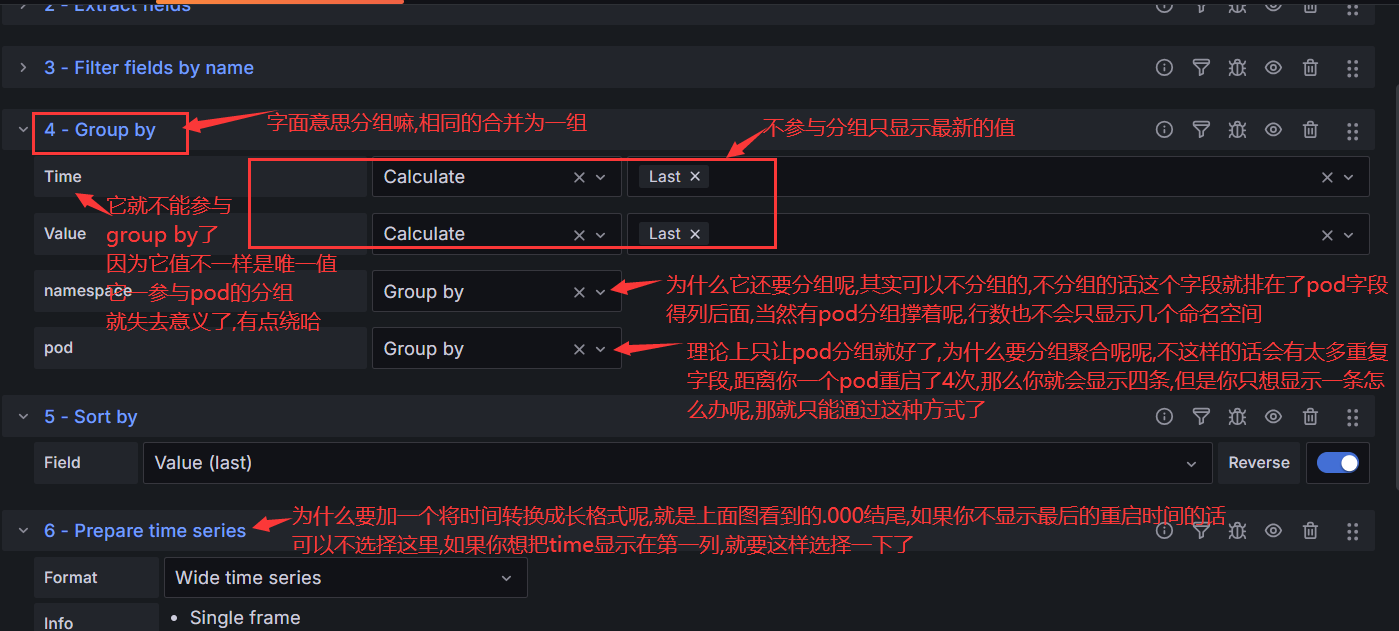
2.4 用1个例子说明一下正确用法
#看到这里是不是发现有点不对了,之前用grafana出图的时候也没这么费劲啊,怎么现在出一个表格要这么多函数。而且如果如果有多个query结果的时候你会发现没办法合并到一个表格上面展示了。所以忘记上面的使用方法,只是单纯的了解下转换函数的使用。
我们再来一个实际场景的例子,我想要把某一类型的主机都体现在一个表格上面,比如50台机器,我想一眼就能看到他们的CPU使用率,内存使用率是否异常等等,这不就是grafana出图聚合可视化的实际场景嘛。
先来几个query:
#node节点的基础指标一般是使用node_exports采集的
sum(time() - node_boot_time_seconds)by(instance) #机器的运行时间
node_memory_MemTotal_bytes - 0 #机器的内存大小
count(node_cpu_seconds_total{mode='system'}) by (instance) #机器的cpu数量
(1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100 #机器的内存使用率query如何处理:
#不做对比了,直接上正确用法了
博文来自:www.51niux.com
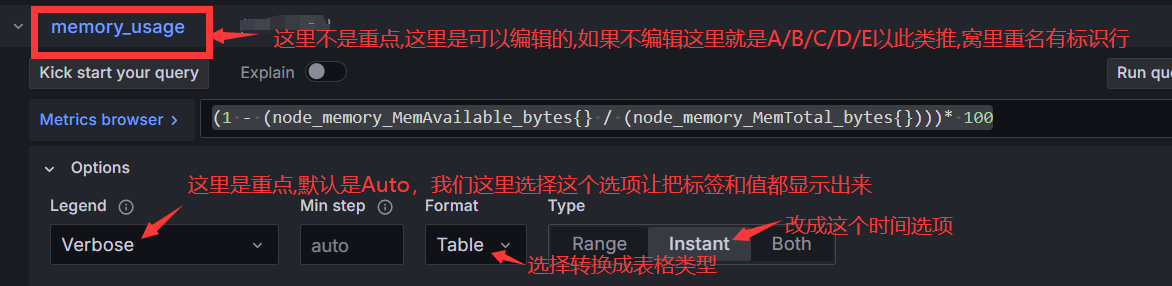
tramsform函数如何使用
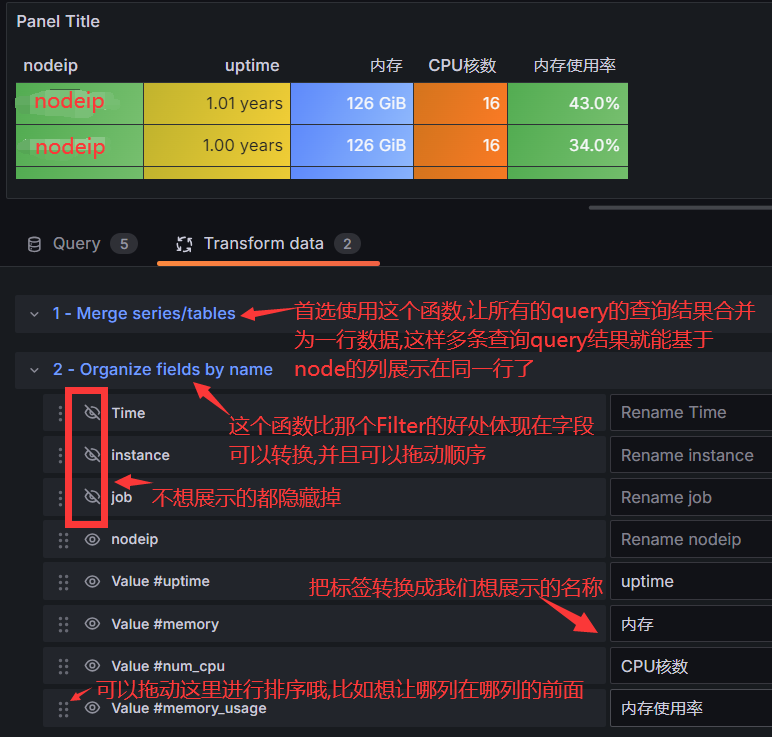
Override针对指定项单独设置
#比如你想让内存使用率超过多少进行不同的颜色展示,体现在这个单元表中,可以如下设置:
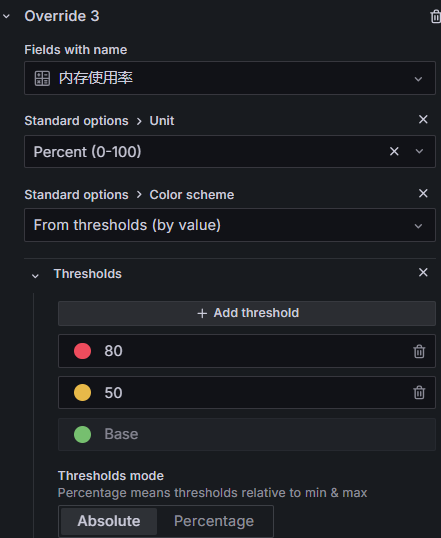
#剩下的比如磁盘空间啊,网卡流量啊等等按照这个方式累加就可以了,意思一致。
三、grafana做同环比
3.1 grafana使用ES源做同比
#好我们来个需求,我想看到我一些指标比如完单数今天和昨天同时段的对比情况。
#先设置AB两个相同的metric查询语句,然后再B第二个查询语句进行一些设置:
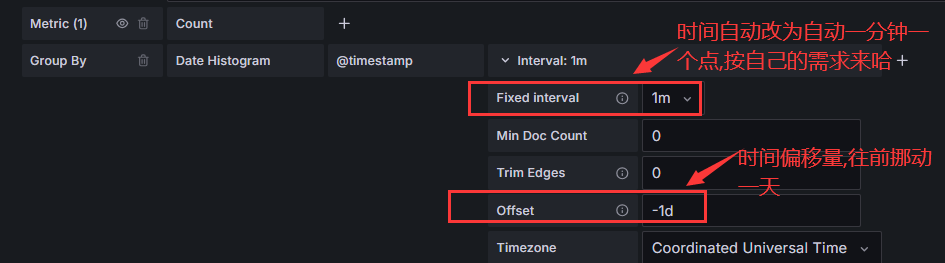
#做了时间偏移量之后你会发现当前的指标图中也只显示当天的指标数据,昨天的指标数据并未在X轴上面显示

#其他grafana上面的细节点就不做介绍了,自己点击的调整吧,让我们最后看下效果
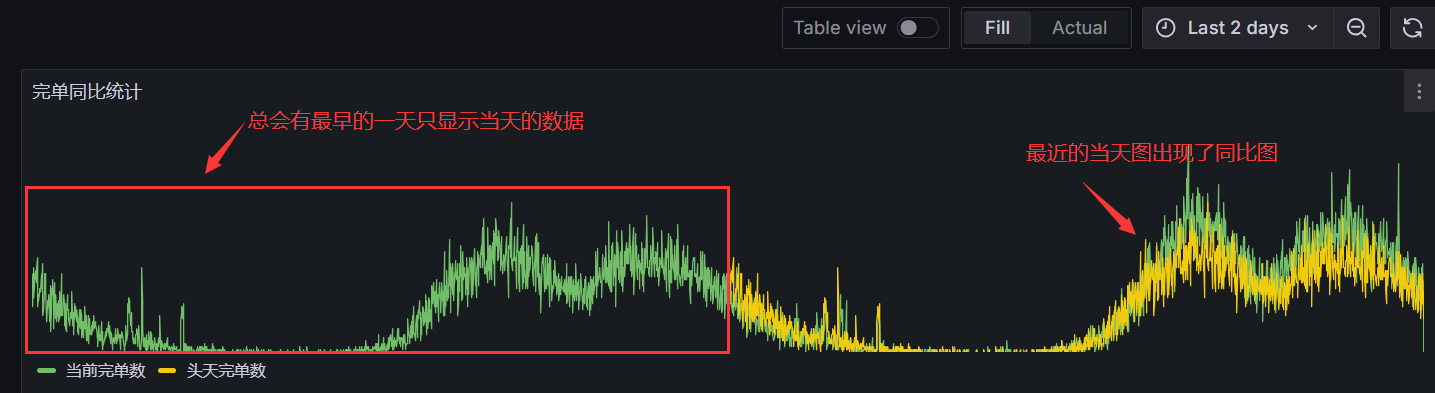
#好可以看到同比效果图出现了,但是有一些不完美的地方就是最会有一天不是同比图,另外如果你选择24小时或者当天的时间的话,也只会显示当天的指标图不会有同比效果。为什么会这样呢?因为我们昨天的数据是通过偏移量-1d,也就是比如你选择7d,那么正常的就是7天的数据,但是B昨日的数据是7d-1d=6d,因为少一天数据。
3.2 grafana使用prometheus源做同比
#好这次说用户下单数,我们先是程序将没分钟的下单数做了一个sum计算后,插入到了prometheus中,也就是一个点就是一分钟的数据。
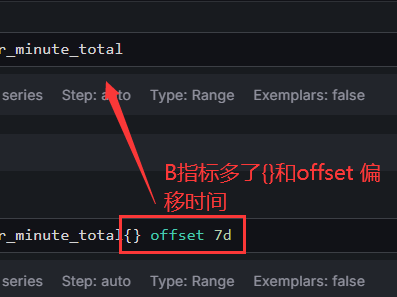
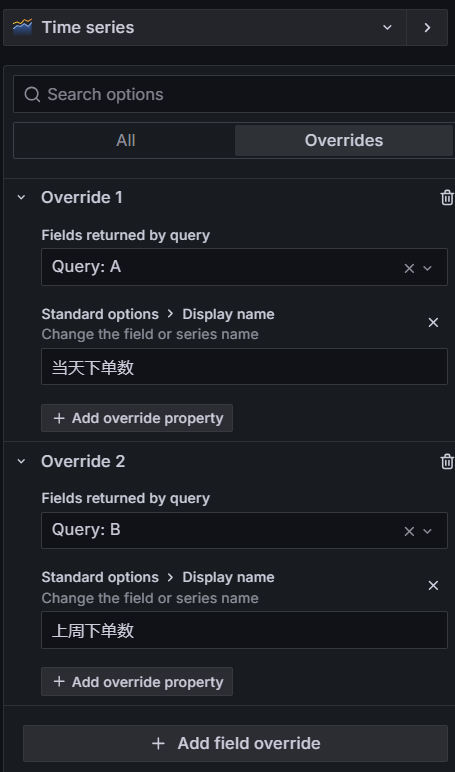
#你会发现很直接,上周和当前的数据指标直接体现在了指标图中了,还有个小问题哈,指标标题显示的是是一个长串的结果,我们想改成我们指定的名称。你还不能基于字段名称进行替换,因为这两个字段名称一样,所以使用by query.
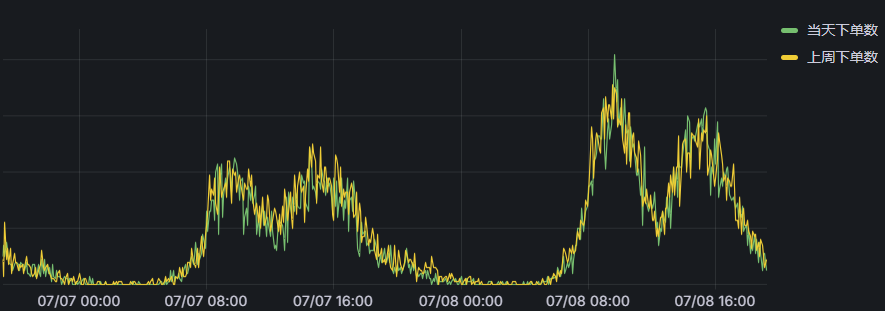
#下面让我们看看最终的效果图(可以发现之前说的es的显示问题不存在了):
3.3 grafana使用clickhouse源做同比
https://www.51niux.com/?id=318 #已经介绍了clickhouse如何搭建和如何采集nginx日志,这里我们利用采集的nginx做下出图展示
#添加数据源就不截图介绍了,server address就是ck的地址,server port是端口默认是8123端口,有账号密码的话在username和password那里设置。
官网文档:https://clickhouse.com/docs/en/integrations/grafana
我们先做一个按时间访问的趋势图:
SELECT TimeLocal as "time", count() as "当前访问次数" FROM "nginxdb"."access_logs_view" WHERE ( time >= $__fromTime AND time<= $__toTime ) AND Status='200' GROUP BY time
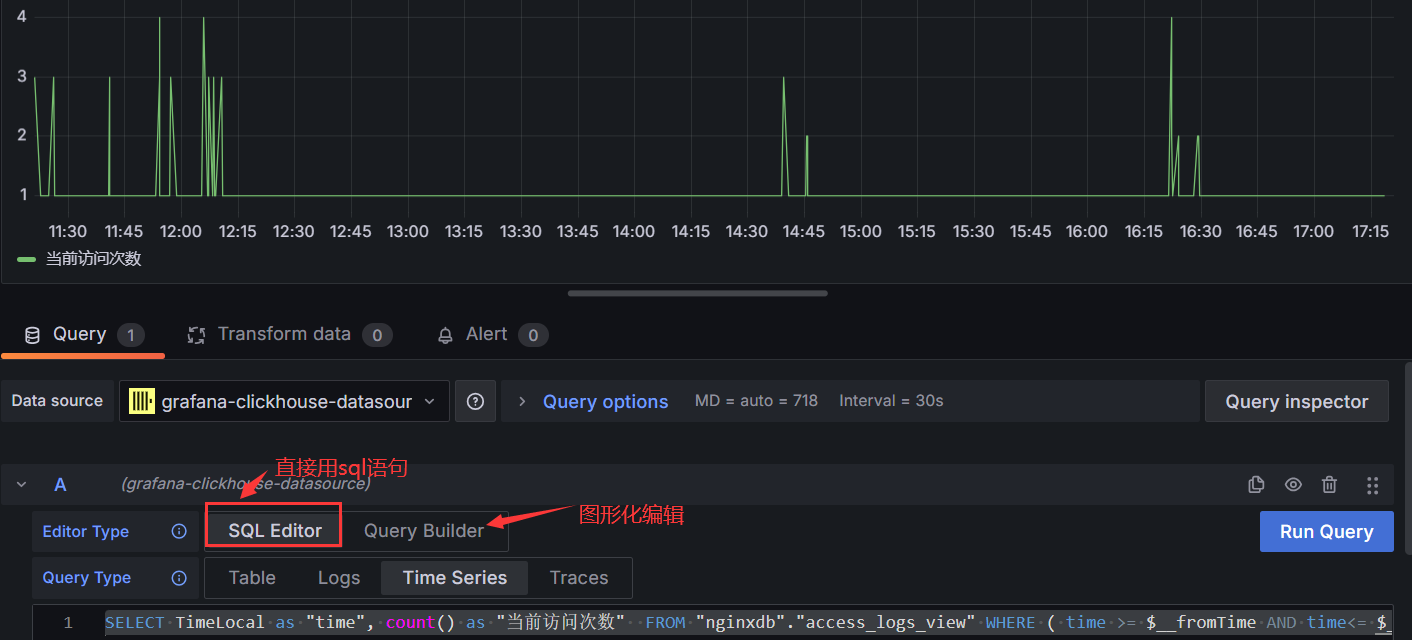
#$__fromTime和$__toTime就是dashboard上面的开始时间和结束时间,这时候就可以通过拖动时间来显示指定时间的nginx访问日志的次数。但是这里有个问题,可以自己尝试,你会发现Interval也就是我们常说的步长失去作用了,只会显示time分组的次数,比如你的time精确到秒,就是时间秒的访问次数。但是我们一旦时间拉大可能是想显示某分钟或者某小时的聚合次数,下面是我的方法,如果有更好的麻烦告知一下。
SELECT toStartOfHour(TimeLocal) as Hour, count(*) as "当前访问次数" FROM "nginxdb"."access_logs_view" WHERE (TimeLocal >= $__fromTime AND TimeLocal < $__toTime) and Status='200' GROUP BY Hour ORDER BY Hour;
#直接用clickhouse的时间转换函数,转换出一个小时维度的时间Hour,然后再去Group分组,下面是效果图
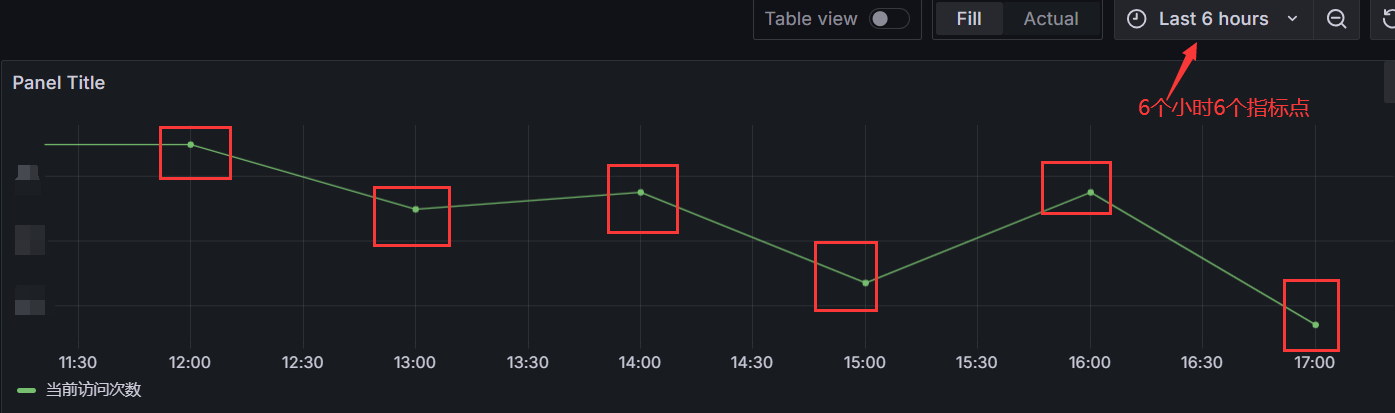
关于函数的官网文档:https://clickhouse.com/docs/en/sql-reference/functions/date-time-functions#tostartofhour
这里有一个注意点:
一般你可能遇不到这个情况或者没有注意到,因为一般都是统计流量大的域名日志,所以基本每分钟都是有日志,一般重要的域名都是有探活的,所以基本每分钟也会有请求,如果你不做同比展示,这个问题也对你不会有影响的。这个问题就是,如果你采集的是一个流量比较小的域名日志,那么它不能保证每分钟都会请求,如果你按照分钟分组的时候呢,就可能有的分钟是没有数据的,这体现在grafana上面就是没有数据点位。比如下面(一个测试域名量比较小能体现这个问题)的示例:
下面是clickhouse里面针对某个时刻的次数统计:
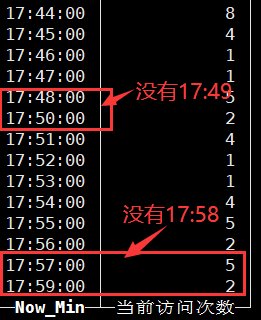

#直接文字描述了,如果是单纯的当天日志展示,没有数据点位也是没关系的,但是如果一旦同比展示的话,就会出现时间点的错位/补位,你就会发现有的时刻指标是对的,有的图上的数据点位指标是不对的。你说我把为空的置0行不行(COALESCE(count(), 0) 或者 IFNULL(count(), 0)),也是不行的,因为是本身就没有这个时间而不是这个时间点数据为空。
做昨日/上周同比
#我们一般都是做分钟级的同比,秒级的太细毛刺太多,小时级的粒度又太粗反映太滞后了。下面分别做ABC三条sql语句:
A:
SELECT toStartOfMinute(TimeLocal) as Now_Min, IFNULL(count(*),0) as "当前访问次数" FROM "nginxdb"."access_logs_view" WHERE (TimeLocal >= $__fromTime AND TimeLocal < $__toTime) and Status='200' GROUP BY Now_Min ORDER BY Now_Min;
B(这里重点是让TimeLocal让右偏移,让查询时间范围往左偏移)这样才能达到同比效果:
SELECT toStartOfMinute(toDateTime(toUnixTimestamp(TimeLocal)+86400)) as Yes_Min, count(*) as "昨日访问次数" FROM "nginxdb"."access_logs_view" WHERE TimeLocal >= toDateTime(toUnixTimestamp($__fromTime)-86400) AND TimeLocal< toDateTime(toUnixTimestamp($__toTime)-86400) GROUP BY Yes_Min ORDER BY Yes_Min;
#因为我们这个B的查询时间范围是不在grafana的搜索时间框里面的,如果想单独的Time series得panel显示的话会有下面报错(可以用table格式看数据是否正确),这里说的报错是在没有+86400也就是sql语句不是toUnixTimestamp(TimeLocal)+86400)[这个是把在grafana上面的显示时间往右边错位1天,这时候你看到的时间比如本来是5月21号的数据在图上显示的是5月22的日期]而是正常的TimeLocal的时候(是为了检查取值的准确性):
报错信息:Data outside time range Zoom to data(字面意思也很好理解啊超过了时间范围)

C查询:
SELECT toStartOfMinute(toDateTime(toUnixTimestamp(TimeLocal)+86400*7)) as Last_Min, count(*) as "上周访问次数" FROM "nginxdb"."access_logs_view" WHERE TimeLocal >= toDateTime(toUnixTimestamp($__fromTime)-86400*7) AND TimeLocal< toDateTime(toUnixTimestamp($__toTime)-86400*7) GROUP BY Last_Min ORDER BY Last_Min;
下面让我们看下效果图:

#至此关于grafana的简单同比图介绍完毕
