ELK收集mysql慢查询日志(八)
#这个mysql日志也没有收集,我们就是收集web日志来着,正好大家一起来学习下。
#https://www.51niux.com/?id=203 了解了可以在Logstash那里用在filter区域用各种插件将message转换。
#https://www.51niux.com/?id=207 了解了可以在filebeat端直接对事件进行转换然后直接就是让logstash转发一下就可以了。
一、正则表达式支持
#前面已经有nginx log日志的例子了,所以我们知道过滤其实就是把一串字符串转换成正则的形式,那么这里咱们先把正则捋一遍。
官网链接:https://www.elastic.co/guide/en/beats/filebeat/6.0/regexp-support.html
Filebeat正则表达式支持基于RE2。Filebeat有几个接受正则表达式的配置选项。 例如,multiline.pattern,include_lines,exclude_lines和exclude_files都接受正则表达式。 但是,某些选项(例如探测器路径选项)只接受基于glob的路径。在配置文件中使用正则表达式之前,请参阅文档以验证正在设置的选项是否接受正则表达式。
建议使用单引号包装正则表达式来解决YAML的字符串转义规则。 例如,'^\[?[0-9][0-9]:?[0-9][0-9]|^[[:graph:]]+'。
有关支持的正则表达式模式的更多示例,请参阅管理多行消息(https://www.elastic.co/guide/en/beats/filebeat/6.0/multiline-examples.html)。 虽然这些示例与Filebeat有关,但是正则表达式模式适用于其他用例。
支持以下模式:
单个字符 复合材料 重复 分组 空的字符串 转义序列 ASCII字符类 Perl字符类
单个字符
x #单个字符
. #任何字符
[xyz] #字符类
[^xyz] #否定字符类
[[:alpha:]] #ASCII字符类
[[:^alpha:]] #否定ASCII字符类
\d #Perl字符类
\D #否定Perl字符类
\pN #Unicode字符类(一个字母的名称)
\p{Greek} #Unicode字符类
\PN #否定Unicode字符类(一个字母的名称)
\P{Greek} #否定Unicode字符类Composites
xy #x之后是y x|y #x或y
Repetitions
x* #零或多个x
x+ #一个或多个x
x? #零或一个x
x{n,m} #n或n + 1或...或m x
x{n,} #n或更多x
x{n} #正好n个x
x*? #零或更多x
x+? #一个或多个x
x?? #零或一个x
x{n,m}? #n或n + 1个x或...或m x
x{n,}? #n或更多x
x{n}? #0或者nxGrouping
(re) #编号捕获组(submatch) (?P<name>re) #命名和编号捕获组(submatch) (?:re) #非捕获组 (?i)abc #在当前组内设置标志,不捕捉 (?i:re) #重新设置标志,不捕捉 (?i)PaTTeRN #不区分大小写(默认为false) (?m)multiline #多行模式:除了开始/结束文本之外,^和$匹配开始/结束行(默认为false) (?s)pattern. #让.匹配\ n(默认为false) (?U)x*abc #ungreedy:交换x*和x*?,x+和x+?等的含义(默认为false)
空的字符串
^ #在文本或行的开头(m = true) $ #在文本末尾(如\z不是\Z)或行(m = true) \A #在文本的开始 \b #在ASCII字边界(\w在一边,\W,\A或\z在另一边) \B #不在ASCII字边界 \z #在文本结尾
转义序列
\a #bell(与\007相同)
\f #换页(与\014相同)
\t #tab(与\011相同)
\n #换行符(与\012相同)
\r #回车(与\015相同)
\v #垂直制表符(与\013相同)
\* #文字*,用于任何标点符号*
\123 #八进制字符代码(最多三位数字)
\x7F #两位十六进制字符代码
\x{10FFFF} #十六进制字符码
\Q...\E #字面文字...即使...有标点符号ASCII字符类
[[:alnum:]] #字母数字(与[0-9A-Za-z]相同)
[[:alpha:]] #字母(与[A-Za-z]相同)
[[:ascii:]] #ASCII(与\ x00- \ x7F相同))
[[:blank:]] #空白(与[\t]相同)
[[:cntrl:]] #control(与[\x00-\x1F\x7F]相同)
[[:digit:]] #数字(与[0-9]相同)
[[:graph:]] #图形(与[!-~] == [A-Za-z0-9!"#$%&'()*+,\-./:;<=>?@[\\\]^_` {|}~])
[[:lower:]] #小写(与[a-z]相同)
[[:print:]] #可打印(与[ -~] == [ [:graph:]]相同)
[[:punct:]] #标点符号(与[!-/:-@[-`{-~]相同)
[[:space:]] #空格(与[\t\n\v\f\r ]相同)
[[:upper:]] #大写(与[A-Z]相同)
[[:word:]] #单词字符(与[0-9A-Za-z_]相同)
[[:xdigit:]] #十六进制数字(与[0-9A-Fa-f]相同支持的Perl字符类
\d #数字(与[0-9]相同) \D #不是数字(与[^0-9]相同) \s #空格(与[\t\n\f\r ]相同) \S #不是空格(与[^\t\n\f\r ]相同) \w #单词字符(与[0-9A-Za-z_]相同) \W #不是单词字符(与[^ 0-9A-Za-z_]相同
博文来自:www.51niux.com
二、利用Logstash推送mysql慢查询日志
#mysql慢查询日志开启就不说了,这里在openstack的控制节点上面造一点慢查询日志然后来采集一下。
#下面是mysql查询日志的格式:
# User@Host: nova[nova] @ controller [192.168.1.13] # Thread_id: 32 Schema: nova QC_hit: No # Query_time: 0.000241 Lock_time: 0.000084 Rows_sent: 1 Rows_examined: 1 # Rows_affected: 0 SET timestamp=1513060041; SELECT services.created_at AS services_created_at, services.updated_at AS services_updated_at, services.deleted_at AS services_delet ed_at, services.deleted AS services_deleted, services.id AS services_id, services.host AS services_host, services.`binary` AS servic es_binary, services.topic AS services_topic, services.report_count AS services_report_count, services.disabled AS services_disabled, services.disabled_reason AS services_disabled_reason, services.last_seen_up AS services_last_seen_up, services.forced_down AS servi ces_forced_down, services.version AS services_version FROM services WHERE services.deleted = 0 AND services.id = 2 LIMIT 1; # User@Host: nova[nova] @ controller [192.168.1.13] # Thread_id: 35 Schema: nova QC_hit: No # Query_time: 0.000240 Lock_time: 0.000100 Rows_sent: 1 Rows_examined: 1 # Rows_affected: 0 SET timestamp=1513060041; SELECT services.created_at AS services_created_at, services.updated_at AS services_updated_at, services.deleted_at AS services_delet ed_at, services.deleted AS services_deleted, services.id AS services_id, services.host AS services_host, services.`binary` AS servic es_binary, services.topic AS services_topic, services.report_count AS services_report_count, services.disabled AS services_disabled, services.disabled_reason AS services_disabled_reason, services.last_seen_up AS services_last_seen_up, services.forced_down AS servi ces_forced_down, services.version AS services_version FROM services WHERE services.deleted = 0 AND services.id = 2 LIMIT 1;
#这里还是用Logstash开启 stdout { codec => rubydebug },看看采集慢查询日志都会输出些啥。
https://www.elastic.co/guide/en/kibana/6.0/devtools-kibana.html #来测试正则写的对不对
2.1 编写边测试
#https://www.51niux.com/?id=210 #注意这里我做了个X-Pack,就是为了方便些grok正则。
先写第一条测试:
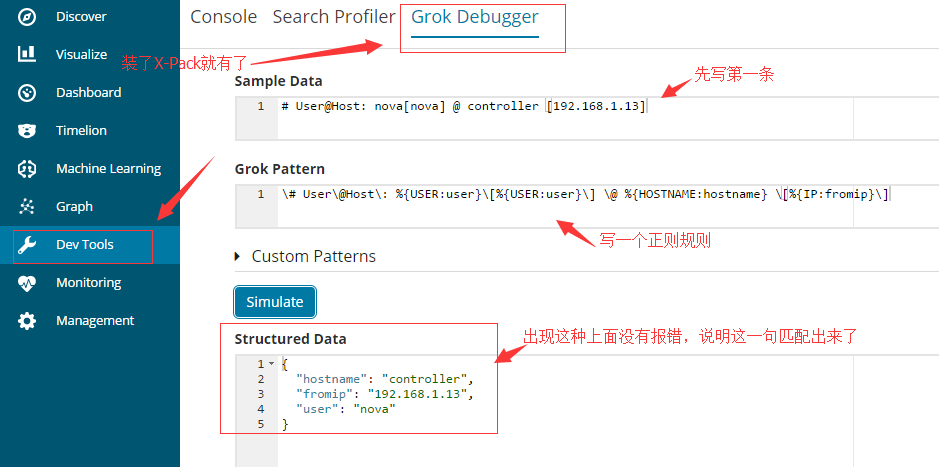
\# User\@Host\: %{USER:user}\[%{USER:user}\] \@ %{HOSTNAME:hostname} \[%{IP:fromip}\]#最开始就是纯死字符串匹配没啥好说的%{USER:user}这里面就是USER一些内置的正则表达式,user就是把USER获得的值交给user这个变量字段。
再写第二条测试:
#这里就不截图了啊,就是上图那个意思,在第一栏贴要匹配的字段,在下面一栏是写正则规则,最后一栏如果有输出说明匹配成功。
测试语句:# Thread_id: 35 Schema: nova QC_hit: No
编写正则表达式:\# Thread_id\: (?<Thread_id>[0-9]+) Schema\: %{USER:user} QC_hit\: (?<hit>[a-zA-Z]+)
#这里主要是(?<自定义字段变量>正则表达式),如(?<Thread_id>[0-9]+) ,就是定义了一个自定义的字段变量Thread_id,然后对应的是正则表达式式数字,也就是将[0-9]+匹配的内容赋值给Thread_id。
结构化数据结果:
{
"hit": "No",
"Thread_id": "35",
"user": "nova"
}再写第三条测试:
测试语句: # Query_time: 0.000240 Lock_time: 0.000100 Rows_sent: 1 Rows_examined: 1
编写正则表达式:\# Query_time\: %{NUMBER:query_time}\s*Lock_time\: %{NUMBER:lock_time}\s*Rows_sent: %{NUMBER:rows_sent}\s*Rows_examined: %{NUMBER:rows_examined}
#这里主要解释一下\s*,这里因为没有截图可能看不出来,字段之间有的是一个空格有的是两个空格或者多个空格,用\s*就直接不用像第一条似得去手工去多个空格了,显然这是一个很好的办法。
下面是结果:
{
"lock_time": "0.000100",
"rows_sent": "1",
"rows_examined": "1",
"query_time": "0.000240"
}再写第四条测试:
测试语句:# Rows_affected: 0
正则语句:\# Rows_affected\: (?<Rows_affected>[0-9]+)
结果:
{
"Rows_affected": "0"
}再写第五条测试:
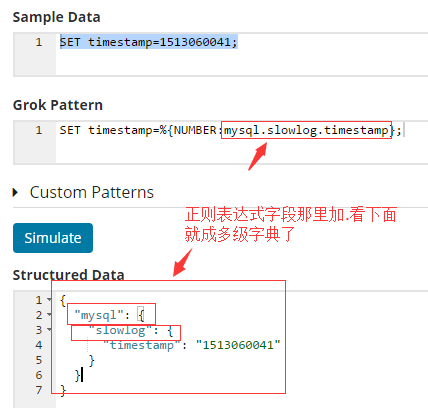
#SET timestamp=%{NUMBER:mysql.slowlog.timestamp}; #这样mysql.slowlog.timestamp是多级字典。
再写第六条测试:
#这个就得测试测试了:
测试语句:
SELECT services.created_at AS services_created_at, services.updated_at AS services_updated_at, services.deleted_at AS services_delet ed_at, services.deleted AS services_deleted, services.id AS services_id, services.host AS services_host, services.`binary` AS servic es_binary, services.topic AS services_topic, services.report_count AS services_report_count, services.disabled AS services_disabled, services.disabled_reason AS services_disabled_reason, services.last_seen_up AS services_last_seen_up, services.forced_down AS servi ces_forced_down, services.version AS services_version FROM services WHERE services.deleted = 0 AND services.id = 2 LIMIT 1; # User@Host: nova[nova] @ controller [192.168.1.13] # User@Host: nova[nova] @ controller [192.168.1.13] # User@Host: nova[nova] @ controller [192.168.1.13]
正则表达式:
# \SELECT (?<message>(.*\n){0,}) #这种多行的挺好写的,这行是注释的,所以不能用这一句,有点问题,这样你连下面那些无关的语句也都匹配上了
\SELECT (?<message>(.*\n){0,}.*)\; #所以要这样来一下,让以是;结尾的。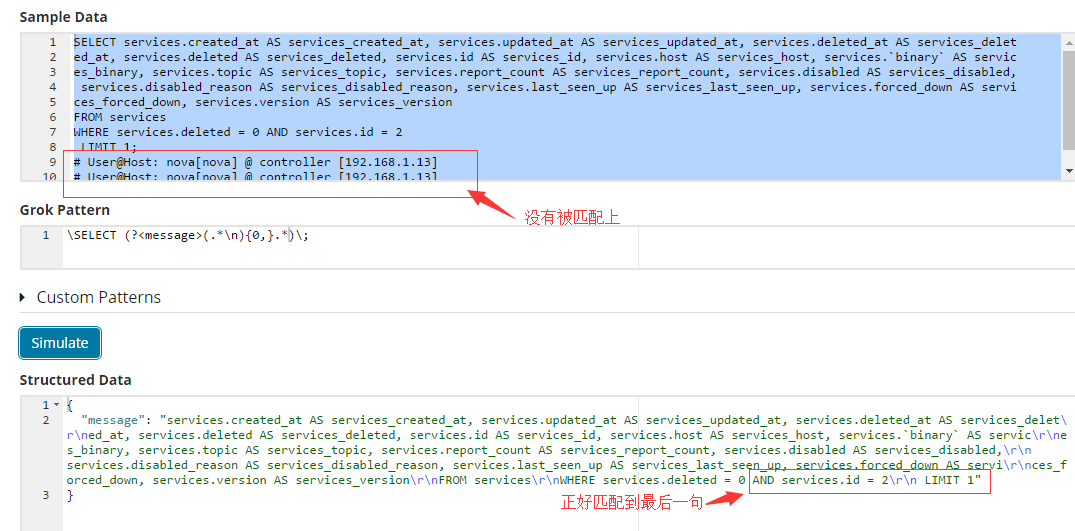
2.2 多行合并为一行
#这个慢查询日志跟nginx日志还不一样,你看nginx就一行,但是这个日志呢是好多行日志信息。
#不写一步步怎么合了,只贴最后结果了。
\# User\@Host\: %{USER:user}\[%{USER:user}\] \@ %{HOSTNAME:hostname} \[%{IP:fromip}\]\s*
\# Thread_id\: (?<Thread_id>[0-9]+) Schema\: %{USER:user} QC_hit\: (?<hit>[a-zA-Z]+)\s*
\# Query_time\: %{NUMBER:query_time}\s*Lock_time\: %{NUMBER:lock_time}\s*Rows_sent: %{NUMBER:rows_sent}\s*Rows_examined: %{NUMBER:rows_examined}\s*
\# Rows_affected\: (?<Rows_affected>[0-9]+)\s*
SET timestamp=%{NUMBER:mysql.slowlog.timestamp}\;\s*
\SELECT (?<message>(.*\n){0,}.*)\;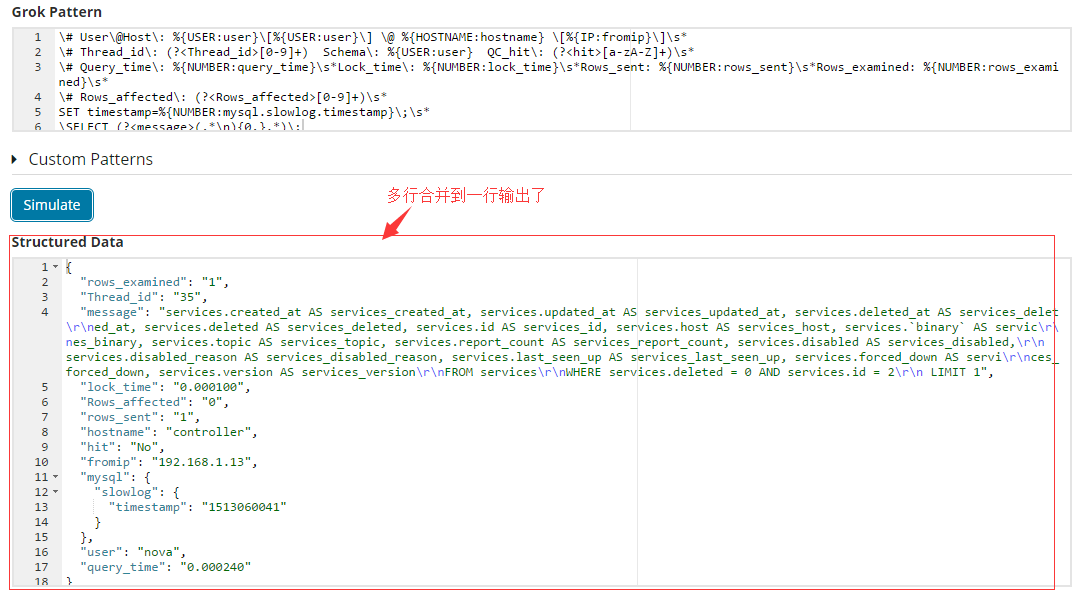
#注意上面语句最后,每一行正则匹配后面都用\s*匹配上了,这样保证直接把换行也匹配上了。
#然后就是这些常规正则不会写啊,能不能提供点思路啊,可以的。例如参考:/home/elk/filebeat/module/mysql/slowlog/ingest/pipeline.json
#上面写了那么多也并不是并没有什么卵用,就是放到logstash里面还是要调整,对这种多行......比如这样放到logstash肯定不行一班就是多行正则合并成一行的时候可能会出现问题,所以还是要略微调整的。
#你可以这样试试,将你测试好的语句放到linux里面的一个临时文件中,然后用dos2unix命令将文件转换一下,然后将里面的语句再搞出来,你用上面页面测试成功了就是OK了,但是就是格式得调整调整,耐心一点放到logstash里面微调微调。
2.3 用Logstash方式采集上传至elasticsearch
#注意这种方式是直接在mysql端安装logstash然后采用本地file的方式将信息传到Elasticsearch上面
#参考:http://blog.csdn.net/shuxiang1990/article/details/53415473
$ cat /home/elk/logstash/conf/mysqltest.conf
input {
file {
path => "/var/lib/mysql/slow.log"
type => "slow-log"
codec => multiline { #主要是这里使用多行模式,因为慢查询日志是多行的
pattern => "^# User@Host:" #以# User@Host:开头的行
negate => true
what => previous
}
}
}
filter {
grok {
match => { "message" => "# User@Host: (?<user>[a-zA-Z0-9._-]*)\[(?:.*)\]\s+@\s+(?<client-domain>\S*)\s+\[%{IP:client-ip}*\]\s.*# Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent: %{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:int}\s.*(?<db>use \S*)?.*SET timestamp=%{NUMBER:ts};\s+(?<query>(?<action>\w+)\s+.*)\s+#?\s*.*" }
}
}
output {
#stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.14.62"]
index => "mysql-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
}
}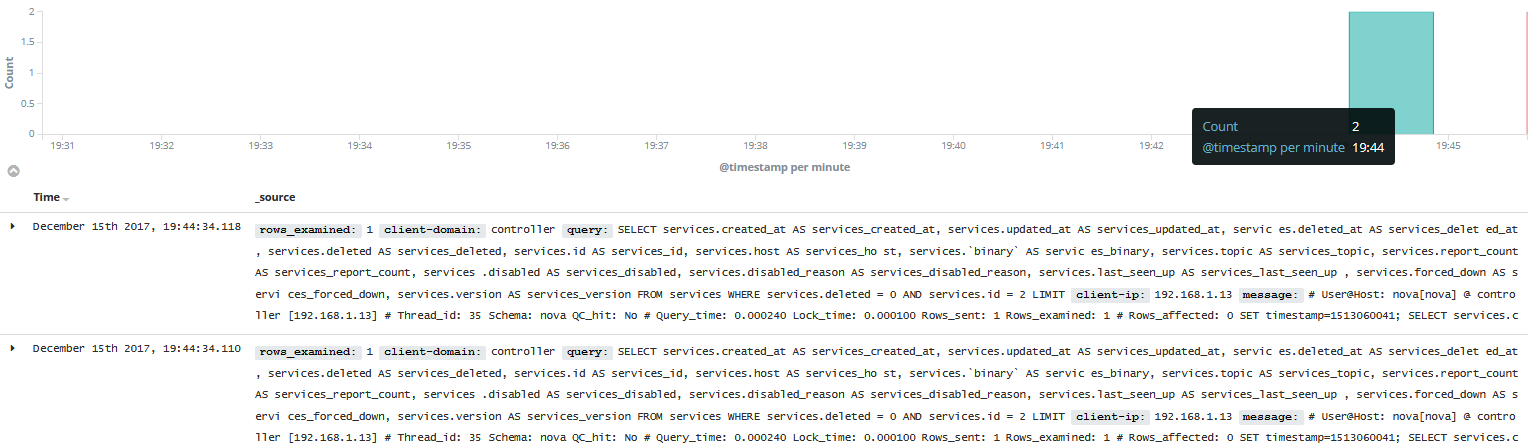
#往慢查询日志里面插入数据测试一下,可以看到数据已经传上来了。
#试着采用filebeat方式多行传输的方式,但是没有成功,就采取了logstash的input插件类型是file方式。
博文来自:www.51niux.com
2.4 跟着官网翻译一下file INPUT插件也是经常用到的插件类型
官网链接:https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html
描述
通过文件流式传输事件,通常以类似于tail -0F的方式拖尾处理,但可以从头开始读取。
默认情况下,每个事件被假定为一行,并且一行被认为是换行符之前的文本。通常情况下,日志记录将在每行的末尾添加一个换行符。 如果您想将多个日志行加入一个事件,则需要使用多行编解码器或过滤器。
该插件旨在跟踪变化的文件,并发布新的内容,因为它附加到每个文件。 它不适合从头到尾读取文件,并将其全部存储在单个事件中(即使使用多行编解码器或过滤器也不行)。
从远程网络卷读取
文件输入不在远程文件系统(如NFS,Samba,s3fs-fuse等)上进行测试。这些远程文件系统通常具有与本地文件系统非常不同的行为,因此在与文件输入一起使用时不太可能正常工作。
跟踪观看文件中的当前位置
该插件通过将其记录在一个名为sincedb的单独文件中来跟踪每个文件中的当前位置。 这样就可以停止并重新启动Logstash,并在停止Logstash时忽略掉添加到文件中的行。
默认情况下,sincedb文件被放置在运行Logstash的用户的主目录中,其文件名基于正在监视的文件名模式(即路径选项)。 因此,更改文件名模式将导致使用新的sincedb文件,并且任何现有的当前位置状态都将丢失。 如果你用任何频率改变模式,用sincedb_path选项明确地选择sincedb路径可能是有意义的。
每个输入必须使用不同的sincedb_path。 使用相同的路径会导致问题。 每个输入的读取检查点必须存储在不同的路径中,以免信息覆盖。
Sincedb文件是包含四列的文本文件:
inode号码(或等价物)。 文件系统的主要设备号(或等同的)。 文件系统的次要设备号(或同等)。 文件内当前的字节偏移量。
#在非Windows系统上,您可以使用例如 ls -li。
文件轮询
无论文件是通过重命名还是复制操作旋转,都会检测并处理文件旋转。 为了支持旋转之后一段时间写入旋转文件的程序,在文件名模式中包括原始文件名和旋转的文件名(例如. /var/log/syslog and /var/log/syslog.1) 观看(路径选项)。 请注意,旋转的文件名将被视为一个新的文件,所以如果start_position设置为开始旋转的文件将被重新处理。
文件输入配置选项
该插件支持以下配置选项和稍后介绍的通用选项。

close_older #值类型是数字,默认值是3600。文件输入将关闭上次在指定时间范围内读取的所有文件(以秒为单位)。这有不同的含义,取决于文件是否被加尾或读取。 如果tailing,并且传入数据中存在大的时间间隔,则可以关闭该文件(允许打开其他文件),但在检测到新数据时将排队重新打开。 如果读取,文件将在读取最后一个字节后的closed_older秒后关闭。 默认值是1小时 delimiter #值类型是字符串,默认值是“\ n”。设置新的行分隔符,默认为“\ n”。 discover_interval #值类型是数字,默认值是15。我们多长时间(以秒为单位)在路径选项中展开文件名模式,以发现要观看的新文件。 exclude #值类型是数组,这个设置没有默认值。排除(与文件名匹配,不是完整路径)。文件名模式在这里也是有效的。 例如,如果你有path => "/var/log/*"您可能想要排除gzip文件:exclude => "*.gz" ignore_older #值类型是数字,这个设置没有默认值。当文件输入发现在指定的时间范围之前上次修改的文件(秒)时,该文件将被忽略。 发现后,如果忽略的文件被修改,则不再被忽略,并且读取任何新的数据。 默认情况下,此选项被禁用。 注意这个单位是在几秒钟内。 max_open_files #值类型是数字,这个设置没有默认值。这个输入在任何时候消耗的file_handle的最大数量是多少。如果您需要处理比此编号更多的文件,请使用close_older关闭一些文件。这不应该设置为操作系统可以执行的最大操作,因为其他LS插件和操作系统进程需要文件句柄。filewatch中设置了4095的默认值。 path #这是一个必需的设置。值类型是数组,这个设置没有默认值。用作输入的文件的路径。 你可以在这里使用文件名模式,比如/var/log/*.log。 如果使用类似/var/log/**/*.log的模式,则将为所有* .log文件执行/var/log的递归搜索。路径必须是绝对的,不能是相对的。可以用数组配置多路径。 sincedb_path #值类型是字符串,这个设置没有默认值。sincedb数据库文件的路径(记录受监视的日志文件的当前位置)将写入磁盘的路径。 默认会将sincedb文件写入<path.data>/plugins/inputs/file注意:它必须是文件路径而不是目录路径 sincedb_write_interval #值类型是数字,默认值是15.使用受监控日志文件的当前位置多长时间(以秒为单位)编写自数据库。 start_position #值可以是任何:开始,结束,默认值是“结束”。选择Logstash开始读取文件的位置:开始或结束。 默认行为像直播流一样处理文件,因此从头开始。如果您想要导入旧数据,请将其设置为开头。 #这个选项只修改文件是新的并且以前没有看到的“first”情况,即没有记录在由Logstash读取的sincedb文件中的当前位置的文件。 如果之前已经看过一个文件,这个选项没有任何作用,并且会使用记录在sincedb文件中的位置。 stat_interval #值类型是数字,默认值是1。多久(以秒为单位)我们的统计文件,看看他们是否已被修改。 增加此间隔会减少我们所做的系统调用的次数,但会增加检测新日志行的时间。
通用选项
所有输入插件都支持以下配置选项:
add_field #值类型是hash,默认值是{}.添加一个字段到一个事件
codec #值类型是codec,默认值是“plain”。用于输入数据的编解码器。 输入编解码器是在数据进入输入之前解码数据的一种便捷方法,无需在Logstash管道中使用单独的筛选器。
enable_metric #值类型是布尔值,默认值为true。为特定的插件实例禁用或启用度量标准日志记录,我们默认记录所有的度量标准,但是您可以禁用特定插件的度量标准收集。
id #值类型是字符串,这个设置没有默认值。为插件配置添加一个唯一的ID。 如果没有指定ID,Logstash将会生成一个。 强烈建议在您的配置中设置此ID。 当你有两个或多个相同类型的插件时,这是非常有用的,例如,如果你有两个文件输入。 在这种情况下添加一个命名的ID将有助于在使用监视API时监视Logstash。
tags #值类型是数组,这个设置没有默认值。添加任意数量的任意标签到您的事件。
type #值类型是字符串,这个设置没有默认值。将类型字段添加到由此输入处理的所有事件。类型主要用于过滤器激活。类型存储为事件本身的一部分,因此您也可以使用类型在Kibana中进行搜索。
#如果您尝试在已经有一个事件的事件上设置类型(例如,当您将事件从发货方发送到索引器时),则新输入将不会覆盖现有类型。 托运人设置的类型即使在发送到另一个Logstash服务器时也会一直保留在该事件中。2.5 删除message消息
问题修复:
#感觉完事了,其实还是有点问题的,比如说如下图:
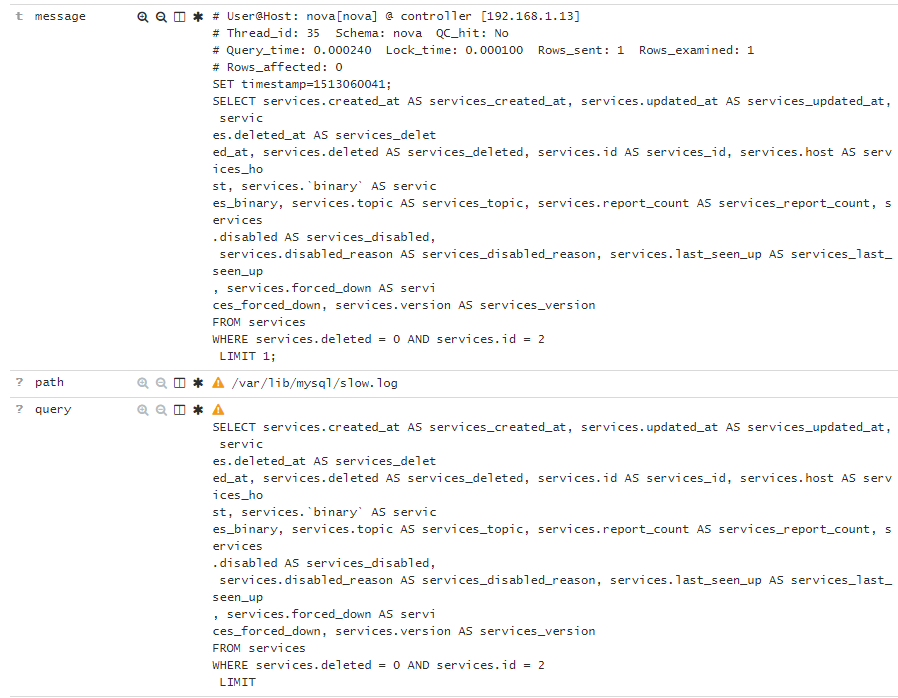
#虽然我们把多行合并成了一条message,但是插入es中呢,message也会插入,我擦这么多字段插双份,太浪费。
#从上图可以看到两个位置 ,第一个问题就是要把message去掉不然太占空间了,第二个query字段取得值并不全LIMIT后面的数字没有了。针对上述两个问题我们再改一改。
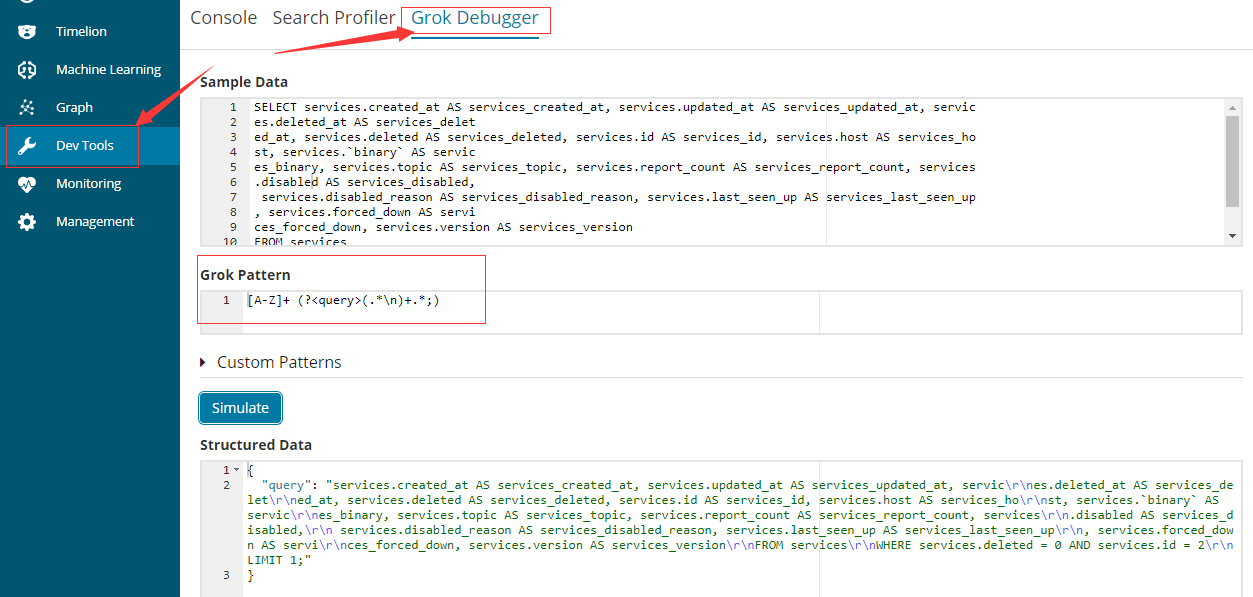
#还是得用X-Pack提供的工具来测试啊(可以单独搞一个单独的机器来装X-Pack,这样就可以使用这个功能而又不影响生产集群了),通过这种方式可以将公式的骨架写出来然后再放到logstash中用stdout { codec => rubydebug }去测试。
#好的通过上面的例子我们将最后一段取查询语句给匹配出来了,是完整的。
博文来自:www.51niux.com
更改Logstash文件:
$ vim /home/elk/logstash/conf/mysqltest.conf
input {
file {
path => "/var/lib/mysql/slow.log"
type => "slow-log"
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => previous
}
tags => ["slow-mysql","mysqllog"]
}
}
filter {
grok {
match => { "message" => "# User@Host: (?<user>[a-zA-Z0-9._-]*)\[(?:.*)\]\s+@\s+(?<client-domain>\S*)\s+\[%{IP:client-ip}*\]\s.*#
Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent: %{NUMBER:rows_sent:int}\s+Rows_examined:
%{NUMBER:rows_examined:int}\s.*(?<db>use \S*)?.*SET timestamp=%{NUMBER:ts};\s+[A-Z]+ (?<query>(.*\n)+.*;)" } #尾部这段稍微变化了下
remove_field => ["message"] #加了这句话将message字段给删除掉
#可以看到删除的其实是一个列表,既然是列表就可以再往里面加元素,例如:remove_field => ["host","path","@version","message"]
}
}
output {
#stdout { codec => rubydebug } #测试的时候可以用这个查看输出格式是否对
elasticsearch {
hosts => ["192.168.14.60","192.168.14.61","192.168.14.62","192.168.14.63","192.168.14.64"]
index => "mysql-%{type}-%{+YYYY.MM.dd}"
document_type => "%{type}"
}
}$ /home/elk/logstash/bin/logstash -f /home/elk/logstash/conf/mysqltest.conf
kibana界面查看:
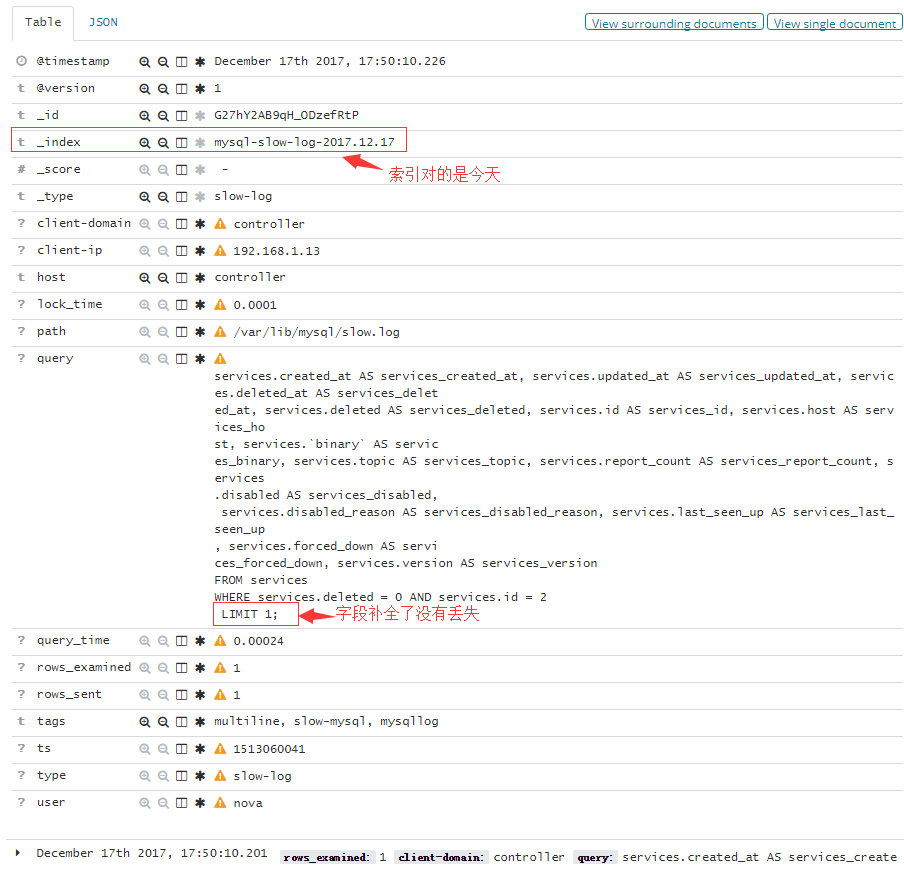
#从上图可以看出message消息没有再写进来,然后query这个字段也吧慢查询的操作取全了LIMIT后面没有丢失了。
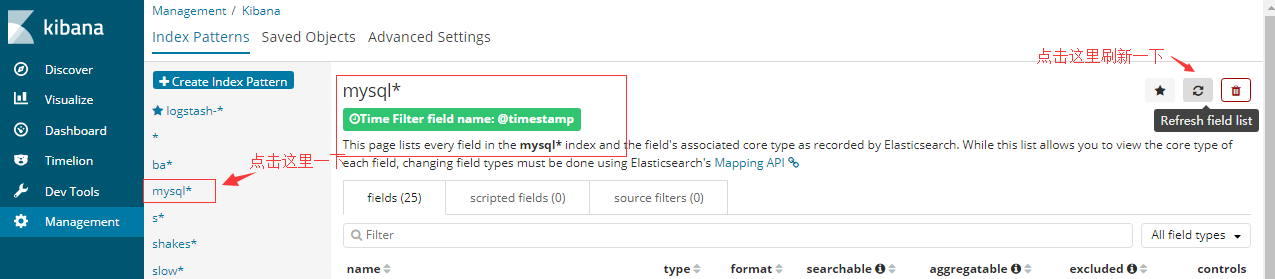
#我擦上面一堆黄色叹号啊,鼠标移到黄色叹号可以看到提示:
No cached mapping for this field. Refresh field list from the Settings >Indices page
#下面解释解决办法:
#然后再次查看:
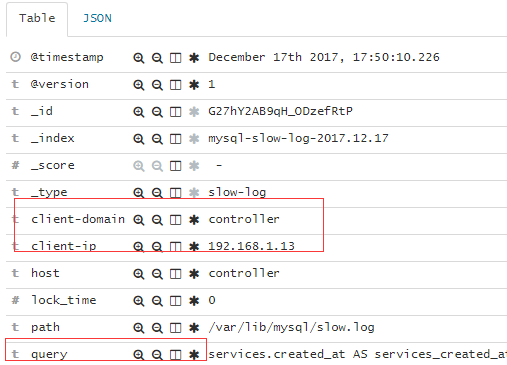
#从图上的结果可以看出,黄色的叹号已经消失了,字段列表更新了,字段都已经映射到缓存中了。
2.6 管理多行事件(官网翻译可直接忽略对多行字段有帮助)
几个用例生成跨越多行文本的事件。 为了正确处理这些多行事件,Logstash需要知道如何判断哪些行是单个事件的一部分。多线事件处理是复杂的,并依赖于适当的事件排序。 保证有序日志处理的最好方法就是尽可能早地实现处理。多行编解码器是处理Logstash流水线中多行事件的首选工具。 多行编解码器使用一组简单的规则合并来自单个输入的行。
如果正在使用支持多个主机的Logstash输入插件(如beats输入插件),则不应使用多行编解码器来处理多行事件。 这样做可能会导致混合的流和损坏的事件数据。 在这种情况下,您需要在将事件数据发送到Logstash之前处理多行事件。
配置多线编解码器最重要的方面如下:
pattern选项指定一个正则表达式。与指定的正则表达式匹配的行被认为是前一行的延续或新的多行事件的开始。可以使用grok正则表达式模板与此配置选项。 什么选项有两个值:previous or next。previous的值指定与pattern选项中的值匹配的行是上一行的一部分。 next值指定与pattern选项中的值匹配的行是以下行的一部分*negate选项将多行编解码器应用于与pattern选项中指定的正则表达式不匹配的行。
#有关配置选项的更多信息,请参阅多线编解码器插件的完整文档(https://www.elastic.co/guide/en/logstash/current/plugins-codecs-multiline.html)。
多线编解码器配置示例
本节中的示例涵盖以下用例:
将Java堆栈跟踪组合成一个事件 将C风格的线条连续组合成一个单独的事件 结合时间戳事件的多行
Java stack traces:
Java堆栈跟踪由多行组成,每行以最后一行开头,如下例所示:
Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
要将这些行整合到Logstash中的单个事件中,请对多行编解码器使用以下配置:
input {
stdin {
codec => multiline {
pattern => "^\s"
what => "previous"
}
}
}#此配置将以空格开头的所有行合并到上一行。
线路延续
几种编程语言使用行尾的\字符来表示该行继续,如下例所示:
printf ("%10.10ld \t %10.10ld \t %s\
%f", w, x, y, z );要将这些行整合到Logstash中的单个事件中,请对多行编解码器使用以下配置:
input {
stdin {
codec => multiline {
pattern => "\\$"
what => "next"
}
}
}#此配置将以\字符结尾的任何行与以下行合并。
Timestamps(时间戳)
来自Elasticsearch等服务的活动日志通常以时间戳开始,然后是关于特定活动的信息,如下例所示:
[2015-08-24 11:49:14,389][INFO ][env ] [Letha] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [34.5gb], net total_space [118.9gb], types [hfs]
要将这些行整合到Logstash中的单个事件中,请对多行编解码器使用以下配置:
input {
file {
path => "/var/log/someapp.log"
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601}"
negate => true
what => previous
}
}
}#此配置使用negate选项来指定任何不以时间戳开头的行都属于previous。
