大数据(十一)flume介绍
flume要好好总结一下,15年接触flume的时候真的是资料太少了,基本就是抱着官网啃然后就一个flume群人多点进去问问题,然后网上的博客很少,现在好多了。
当时学习源于美团的一片文章:https://tech.meituan.com/mt-log-system-arch.html #棒的飞起,也可以看看其他的技术分享。
flume官网:http://flume.apache.org/
一、flume介绍(还是照着官网来)
1.1 什么是flume?
可以理解flume是日志收集系统,Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分,经过架构重构后,Flume NG更像是一个轻量级的小工具,适应各种方式的日志收集,并支持failover和负载均衡。改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Apache Flume是一个分布式,可靠且可用的系统,用于高效地收集,汇总和将来自多个不同源的大量日志数据移动到集中式数据存储区。Apache Flume的使用不仅限于日志数据聚合。 由于数据源是可定制的,Flume可用于传输大量的事件数据,包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎所有可能的数据源。Apache Flume是Apache软件基金会的顶级项目。
1.2 flume的结构
数据流模型:
Flume事件被定义为具有字节有效载荷和一组可选字符串属性的数据流单元。 Flume代理是一个(JVM)进程,它承载事件从外部源流向下一个目标(跳)的组件。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。
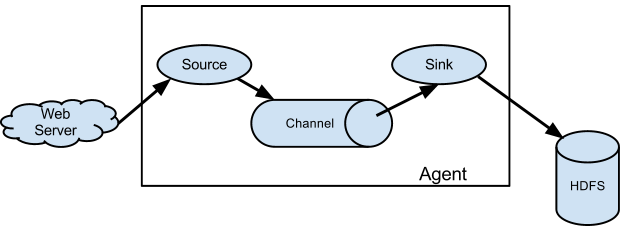
Flume源消耗由外部源(如Web服务器)传递给它的事件。外部源以Flume源识别的格式向Flume发送事件。例如,Avro Flume源可用于从Avro客户端或其他Flume客户端接收从Avro接收器发送事件的流中的Avro事件。使用Thrift Flume Source可以定义类似的流程,以接收来自Thrift Sink或Flume Thrift Rpc客户端的事件或使用Flume thrift协议生成的任何语言编写的Thrift客户端。当Flume源接收事件时,将其存储到一个或多个频道。渠道是一个被动的商店,保持事件,直到它被一个水槽水槽消耗。文件通道就是一个例子 - 它由本地文件系统支持。接收器从通道中删除事件并将其放入HDFS(通过Flume HDFS接收器)之类的外部存储库,或者将其转发到流中下一个Flume代理(下一个跃点)的Flume源。给定代理中的源和宿与运行在通道中的事件异步运行。
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source,比如上图中的Web Server生成。当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。 很直白的设计,其中值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。
复杂的流:
Flume允许用户在到达最终目的地之前通过多个代理程序建立多跳流。 它还允许扇入(fan-in)和扇出(fan-out)流,上下文路由和备份路由(故障转移),以用于失败的跳数。
需要注意的是:同一个Source可以将数据存储到多个Channel,实际上是Replication。一个sink只能从一个Channel中读取数据Channel和Sink是一一对应的。一个Channel只能对应一个Sink,一个Sink也只能对应一个Channel。
可靠性:
这些事件(events)在每个代理人(channel)的频道上进行。 然后将事件传递到流中的下一个代理或终端存储库(如HDFS)。 这些事件只有在存储在下一个代理通道或终端存储库中后才会从通道中删除。 这是Flume中单跳消息传递语义如何提供流的端到端可靠性。
Flume使用事务方式来保证事件的可靠传送。 sources和sinks分别在事务中封装由信道提供的事务中放置或提供的事件的存储/检索,这确保了该组事件在流程中可靠地传递(Source和Sink被封装进一个事务。事件被存放在Channel中直到该事件被处理,Channel中的事件才会被移除。这是Flume提供的点到点的可靠机制。)。 在多跳流的情况下,来自前一跳的接收器和来自下一跳的源两者的事务都在运行,以确保数据安全地存储在下一跳的信道中。
可恢复:
事件在Channel中进行,管理从故障恢复。 Flume支持由本地文件系统支持的持久文件通道。 还有一个内存通道,它将事件简单地存储在内存队列中,这个速度更快,但是当代理进程死亡时仍然留在内存通道中的任何事件都不能被恢复。
1.3 Flume名词解释
Flume(简单介绍):
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。并且,Flume直接各种格式的输入。
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前使用exec方式进行日志采集。
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。
Event:
Event是Flume数据传输的基本单元。Flume以事件的形式将数据从源头传送到最终的目的。Event由可选的header和载有数据的一个byte array 构成。可以是日志记录、 avro 对象等
Client:
Client 是一个将原始log包装成events并且发送他们到一个或多个agent的实体目的是从数据源系统中解耦Flume,在flume的拓扑结构中不是必须的。Client实例:flume log4j Appender,可以使用Client SDK(org.apache.flume.api)定制特定的Client。生产数据,运行在一个独立的线程。
Agent:
使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。一个Agent包含 source ,channel,sink 和其他组件。它利用这些组件将events从一个节点传输到另一个节点或最终目的地,agent是flume流的基础部分。flume为这些组件提供了配置,声明周期管理,监控支持。
Source:
从Client收集数据,传递给Channel。Source 负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel,包含event驱动和轮询两种类型。必须至少和一个channel关联。
Channel:
连接 sources 和 sinks ,这个有点像一个队列,Channel有多种方式:有MemoryChannel, JDBC Channel, MemoryRecoverChannel, FileChannel。MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整。MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。FileChannel保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。中转Event的一个临时存储,保存有source组件传递过来的Event,当sink成功的将event发送到下一个channel或最终目的,event从Channel移除,不同的channel提供的持久化水平是不一样的。
Sink:
从Channel收集数据,运行在一个独立线程,Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。负责将event传输到下一跳或最终目的,成功后将event从channel移除,必须作用一个确切的channel。
Iterator:
作用于Source,按照预设的顺序在必要地方装饰和过滤events。
channel selector:
允许Source基于预设的标准,从所有channel中,选择一个或者多个channel。
sink processor:
多个sink 可以构成一个sink group,sink processor 可以通过组中所有sink实现负载均衡,也可以在一个sink失败时转移到另一个。
1.4 Flume一些组件说明:
flume Source:
Source类型 说明 Avro Source #支持Avro协议(实际上是Avro RPC),内置支持 Thrift Source #支持Thrift协议,内置支持 Exec Source #基于Unix的command在标准输出上生产数据 JMS Source #从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 Spooling Directory Source #监控指定目录内数据变更 Twitter 1% firehose Source #通过API持续下载Twitter数据,试验性质 Netcat Source #监控某个端口,将流经端口的每一个文本行数据作为Event输入 Sequence Generator Source #序列生成器数据源,生产序列数据 Syslog Sources #读取syslog数据,产生Event,支持UDP和TCP两种协议 HTTP Source #基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 Legacy Sources #兼容老的Flume OG中Source(0.9.x版本)
flume Channel:
Channel类型 说明 Memory Channel #Event数据存储在内存中 JDBC Channel #Event数据存储在持久化存储中,当前Flume Channel内置支持Derby File Channel #Event数据存储在磁盘文件中 Spillable Memory Channel #Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) Pseudo Transaction Channel #测试用途 Custom Channel #自定义Channel实现
flume Sink:
Sink类型 说明 HDFS Sink #数据写入HDFS Logger Sink #数据写入日志文件 Avro Sink #数据被转换成Avro Event,然后发送到配置的RPC端口上 Thrift Sink #数据被转换成Thrift Event,然后发送到配置的RPC端口上 IRC Sink #数据在IRC上进行回放 File Roll Sink #存储数据到本地文件系统 Null Sink #丢弃到所有数据 HBase Sink #数据写入HBase数据库 Morphline Solr Sink #数据发送到Solr搜索服务器(集群) ElasticSearch Sink #数据发送到Elastic Search搜索服务器(集群) Kite Dataset Sink #写数据到Kite Dataset,试验性质的 Custom Sink #自定义Sink实现
一张图总结Flume支持各种各样的sources,sinks,channels,它们支持的类型如下:

#此图来自:http://www.cnblogs.com/gongxijun/p/5661037.html
博文来自:www.51niux.com
二、跟着官网搭建一下flume
现在最新版已经是flume1.8了,最软件是有些要求的,要求jdk是1.8或者以上。一般不追新,我线上用的是1.6。配置上应该变动不大,这里用1.8来操作。
2.1 配置一个简单的flume agent
#这里先搞一台,然后再一点点扩展。我这里先搞一台干净的Centos7.2系统的机器:192.168.14.60来做flume的agent端。
#首先需要安装jdk,这里就不记录jdk的安装了。
安装flume:
# useradd flume
# wget mirrors.hust.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
# tar zxf apache-flume-1.8.0-bin.tar.gz -C /home/flume/
# ln -s /home/flume/apache-flume-1.8.0-bin /home/flume/flume
配置环境变量:
# vim /etc/profile
####flume java path#### export JAVA_HOME=/usr/java/jdk export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export FLUME_HOME=/home/flume/flume export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$FLUME_HOME/bin:$PATH
# source /etc/profile
# java -version
java version "1.8.0_74" Java(TM) SE Runtime Environment (build 1.8.0_74-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.74-b02, mixed mode)
# flume-ng version
Flume 1.8.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: 99f591994468633fc6f8701c5fc53e0214b6da4f Compiled by denes on Fri Sep 15 14:58:00 CEST 2017 From source with checksum fbb44c8c8fb63a49be0a59e27316833d
flume-ng的命令参数简单了解下:
# flume-ng --help
Usage: /home/flume/flume/bin/flume-ng <command> [options]... commands: help #帮助显示这个帮助文本 agent #代理运行Flume代理 avro-client #运行一个avro Flume客户端 version #版本显示Flume版本信息 全局 options: --conf,-c <conf> #使用<conf>目录中的配置 --classpath,-C <cp> #附加类路径 --dryrun,-d #实际上不启动Flume,只是打印命令 --plugins-path <dirs> #以冒号分隔的plugins.d目录列表。请参阅用户指南中的plugins.d部分以获取更多详细信息。默认:$FLUME_HOME/plugins.d -Dproperty=value #设置Java系统属性值 -Xproperty=value #设置一个Java -X选项 agent options: --name,-n <name> #这个agent的名字(必填) --conf-file,-f <file> #指定一个配置文件(如果缺少-z则需要) --zkConnString,-z <str> #指定要使用的ZooKeeper连接(如果缺少-f,则需要) --zkBasePath,-p <path> #在ZooKeeper中为代理配置指定基本路径 --no-reload-conf #如果更改,不要重新加载配置文件 --help,-h #显示帮助文本 avro-client options: --rpcProps,-P <file> #带有服务器连接参数的RPC客户端属性文件 --host,-H <host> #将要发送events(事件)的主机名 --port,-p <port> #avro源的端口 --dirname <dir> #流到avro源流到的目标目录 --filename,-F <file> #文本文件流到avro源(默认:标准输入) --headerFile,-R <file> #包含事件标题作为每个新行上的键/值对的文件 --help,-h #显示帮助文本 #--rpcProps或者--host和--port都必须指定。 #请注意,如果指定了<conf>目录,则始终将其包含在类路径中。
相关配置文件的修改:
# cp /home/flume/flume/conf/flume-env.sh.template /home/flume/flume/conf/flume-env.sh
# vim /home/flume/flume/conf/flume-env.sh
# export JAVA_HOME=/usr/lib/jvm/java-8-oracle export JAVA_HOME=/usr/java/jdk
# vim /home/flume/flume/conf/flume-conf #下面是一个官网第一个example的例子
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 #定义sources源的名称 a1.sinks = k1 #定义存储介质的名称 a1.channels = c1 #定义channels通道的名称 # Describe/configure the source a1.sources.r1.type = netcat #source类型,监控某个端口,将流经端口的每一个文本行数据作为Event输入 a1.sources.r1.bind = localhost #监听IP地址 a1.sources.r1.port = 44444 #监听端口 # Describe the sink a1.sinks.k1.type = logger #Sink类型是logger,也就是数据是日志类型 # Use a channel which buffers events in memory a1.channels.c1.type = memory #channel通道c1类型是内存类型,也就是event数据存储在内存中,然后发送events a1.channels.c1.capacity = 1000 #存储在通道c1中的事件的最大数量 a1.channels.c1.transactionCapacity = 100 #channel将从一个channel获得的最大事件数量或每次传输给予一个sink的事件数量 # Bind the source and sink to the channel a1.sources.r1.channels = c1 #选择从channels通道c1来发送events a1.sinks.k1.channel = c1 #选择从channels通道c1来接收events
#该配置定义了一个名为a1的agent。 a1有一个侦听端口44444上的数据的源,一个缓存内存中事件数据的通道,以及一个将事件数据记录到控制台的接收器。 配置文件命名各个组件,然后描述它们的类型和配置参数。 给定的配置文件可能会定义几个有名的agent 当一个给定的Flume进程启动时,会传递一个标志,告诉它哪个指定的agent要显示。
启动flume进程:
$ bin/flume-ng agent --conf conf --conf-file conf/flume-conf --name a1 -Dflume.root.logger=INFO,console
#请注意,在完整部署中,我们通常会包含一个选项:--conf = <conf-dir>。 <conf-dir>目录将包含一个shell脚本flume-env.sh和一个log4j属性文件。 在这个例子中,我们通过一个Java选项强制Flume登录到控制台,我们没有一个自定义的环境脚本。这里就是启动了一个叫做a1的agent端,使用的是conf/flume-conf文件,然后输出信息级别是INFO级别,因为没有指向日志保存位置所以现在是将日志打印到屏幕
打开两一个终端进行测试:
# telnet localhost 44444
Hello World! #输入这个按回车 OK flume test input #输入这行按回车 OK
再切回刚才的信息打印界面查看当前窗口:
2017-11-29 15:41:10,309 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 48 65 6C 6C 6F 20 57 6F 72 6C 64 21 0D Hello World!. }
2017-11-29 15:49:48,337 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 66 6C 75 6D 65 20 74 65 73 74 20 69 6E 70 75 74 flume test input }#再信息的底部有两条新的输出。event事件被显示在了屏幕上。这样一个最简单的flume代理已经配置完成了。
2.2 在配置文件中使用环境变量
Flume能够在配置中替换环境变量。 例如:
下面是继续使用上面的配置文件,然后稍微修改了部分:
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = ${NC_PORT} #主要是这里引用了一个变量,注意:它目前仅适用于数值,不适用于按键。$ NC_PORT=44444 bin/flume-ng agent --conf conf --conf-file conf/flume-conf --name a1 -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
#通过设置propertiesImplementation = org.apache.flume.node.EnvVarResolverProperties,可以通过代理调用上的Java系统属性启用此功能。
#注意以上只是一个例子,环境变量可以用其他方式配置,包括在conf/flume-env.sh中设置。
Info: Sourcing environment configuration script /home/flume/flume/conf/flume-env.sh
Info: Including Hive libraries found via () for Hive access
+ exec /usr/java/jdk/bin/java -Xms100m -Xmx2000m -Dcom.sun.management.jmxremote -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties -cp '/home/flume/flume/conf:/home/flume/flume/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application --conf-file conf/flume-conf --name a1
2017-11-29 16:12:52,708 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2017-11-29 16:12:52,717 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:134)] Reloading configuration file:conf/flume-conf
2017-11-29 16:12:52,724 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:930)] Added sinks: k1 Agent: a1
2017-11-29 16:12:52,724 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:k1
2017-11-29 16:12:52,724 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:k1
2017-11-29 16:12:52,744 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:140)] Post-validation flume configuration contains configuration for agents: [a1]
2017-11-29 16:12:52,744 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:147)] Creating channels
2017-11-29 16:12:52,755 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory
2017-11-29 16:12:52,762 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:201)] Created channel c1
2017-11-29 16:12:52,764 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type netcat
2017-11-29 16:12:52,781 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2017-11-29 16:12:52,786 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:116)] Channel c1 connected to [r1, k1]
2017-11-29 16:12:52,806 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:137)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@3022197f counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
2017-11-29 16:12:52,821 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:144)] Starting Channel c1
2017-11-29 16:12:52,824 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
2017-11-29 16:12:52,824 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started
2017-11-29 16:12:52,827 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:171)] Starting Sink k1
2017-11-29 16:12:52,828 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:182)] Starting Source r1
2017-11-29 16:12:52,830 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting
2017-11-29 16:12:52,839 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:44444]
2017-11-29 16:15:06,845 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 0D . }
2017-11-29 16:15:08,972 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 45 4E 56 20 73 65 74 20 4F 4B 0D ENV set OK. }
2017-11-29 16:15:15,948 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 48 41 48 41 20 4F 4B 20 6C 61 0D HAHA OK la. }#通过最后的结果输出可以看到是变量传参是OK的,因为我另一个终端已经可以连接上44444端口进行event输入了。
2.3 记录原始数据
#记录流经摄取管道的原始数据流在许多生产环境中不是期望的行为,因为这可能导致泄漏敏感数据或安全相关配置,诸如secret keys,到Flume日志文件。 默认情况下,Flume不会记录这些信息。 另一方面,如果数据管道被破坏,Flume将尝试提供调试问题的线索。
#调试事件流水线问题的一种方法是设置一个连接到Logger Sink的额外的Memory Channel,它将输出所有事件数据到Flume日志。 但是在某些情况下,这种方法是不够的。
#为了启用事件和配置相关数据的日志记录,除了log4j属性之外,还必须设置一些Java系统属性。
#要启用配置相关的日志记录,请设置Java系统属性-Dorg.apache.flume.log.printconfig = true。 这可以通过命令行传递,也可以通过在flume-env.sh中的JAVA_OPTS变量中设置。
#要启用数据记录,请按照上述相同的方式设置Java系统属性-Dorg.apache.flume.log.rawdata = true。 对于大多数组件,log4j日志记录级别还必须设置为DEBUG或TRACE,以使特定于事件的日志记录显示在Flume日志中。
#以下是启用配置日志记录和原始数据日志记录的示例,同时还将Log4j日志级别设置为DEBUG以进行控制台输出:
$ NC_PORT=44444 bin/flume-ng agent --conf conf --conf-file conf/flume-conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
2017-11-29 17:39:27,427 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting
2017-11-29 17:39:27,435 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/0:0:0:0:0:0:0:0:44444]
2017-11-29 17:39:27,437 (SinkRunner-PollingRunner-DefaultSinkProcessor) [DEBUG - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:141)] Polling sink runner starting
2017-11-29 17:39:27,437 (lifecycleSupervisor-1-3) [DEBUG - org.apache.flume.source.NetcatSource.start(NetcatSource.java:191)] Source started
2017-11-29 17:39:27,438 (Thread-2) [DEBUG - org.apache.flume.source.NetcatSource$AcceptHandler.run(NetcatSource.java:271)] Starting accept handler
2017-11-29 17:39:38,567 (netcat-handler-0) [DEBUG - org.apache.flume.source.NetcatSource$NetcatSocketHandler.run(NetcatSource.java:316)] Starting connection handler
2017-11-29 17:39:43,025 (netcat-handler-0) [DEBUG - org.apache.flume.source.NetcatSource$NetcatSocketHandler.run(NetcatSource.java:328)] Chars read = 16
2017-11-29 17:39:43,030 (netcat-handler-0) [DEBUG - org.apache.flume.source.NetcatSource$NetcatSocketHandler.run(NetcatSource.java:332)] Events processed = 1
2017-11-29 17:39:43,033 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 77 6F 20 7A 61 69 6C 61 69 20 79 69 62 6F 0D wo zailai yibo. }
2017-11-29 17:39:47,199 (netcat-handler-0) [DEBUG - org.apache.flume.source.NetcatSource$NetcatSocketHandler.run(NetcatSource.java:328)] Chars read = 8
2017-11-29 17:39:47,200 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 66 65 69 20 71 69 0D fei qi. }
2017-11-29 17:39:47,200 (netcat-handler-0) [DEBUG - org.apache.flume.source.NetcatSource$NetcatSocketHandler.run(NetcatSource.java:332)] Events processed = 1
2017-11-29 17:39:57,428 (conf-file-poller-0) [DEBUG - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:127)] Checking file:conf/flume-conf for changes2.4 基于Zookeeper的配置
#Flume通过Zookeeper支持代理配置。 这是一个实验性功能。 配置文件需要在可配置的前缀下在Zookeeper中上传。 配置文件存储在Zookeeper Node数据中。以下是Zookeeper节点树对于agent端a1和a2的展示:
- /flume |- /a1 [Agent config file] |- /a2 [Agent config file]
一旦上传配置文件,请使用以下选项启动agent:
$ bin/flume-ng agent –conf conf -z zkhost:2181,zkhost1:2181 -p /flume –name a1 -Dflume.root.logger=INFO,console
z #Zookeeper连接字符串。 主机名:端口的逗号分隔列表 p #/基本路径来存储agent配置,默认值/flume
2.5 安装第三方插件
Flume有一个完全基于插件的架构。 虽然Flume带有许多开箱即用的源,通道,接收器,序列化器等,但存在许多与Flume分开发布的实现。
尽管通过在Flume-env.sh文件中将其jar包添加到FLUME_CLASSPATH变量中可以包含自定义的Flume组件,但Flume现在支持一个名为plugins.d的特殊目录,该目录自动获取以特定格式打包的插件。 这样可以更轻松地管理插件打包问题,以及简化几类问题的调试和故障排除,尤其是库依赖性冲突。
plugins.d目录
plugins.d目录位于$ FLUME_HOME/plugins.d。启动时,flume-ng start脚本在plugins.d目录中查找符合以下格式的插件,并在启动java时将它们包含在适当的路径中。
插件的目录设计
plugins.d中的每个插件(子目录)最多可以有三个子目录:
lib - 插件的jar(s) libext - 插件的依赖jar(s) native - 任何所需的本机库,如.so文件
plugins.d目录中的两个插件的示例:
plugins.d/ plugins.d/custom-source-1/ plugins.d/custom-source-1/lib/my-source.jar plugins.d/custom-source-1/libext/spring-core-2.5.6.jar plugins.d/custom-source-2/ plugins.d/custom-source-2/lib/custom.jar plugins.d/custom-source-2/native/gettext.so
2.6 获取数据
Flume支持从外部获取数据的多种机制。
RPC
包含在Flume发行版中的Avro客户端可以使用avro RPC机制将给定的文件发送到Flume Avro源代码:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
#上面的命令会将/usr/logs/log.10的内容发送到监听端口的Flume源。
执行命令
有一个exec源执行给定的命令并消耗输出。即输出的单一“行”。文本后跟回车符('\ r')或换行符('\ n')或两者一起。
网络流
Flume支持以下机制从常见的日志流类型中读取数据,例如:Avro、Thrift、Syslog、Netcat
2.7 设置多agent模式
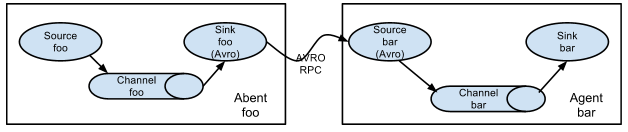
为了使数据在多个代理或跳跃之间流动,前一个代理的接收器和当前跳跃的来源必须是指向源的主机名(或IP地址)和端口的接收器。
2.8 多agent合并模式
日志收集中非常常见的情况是大量的日志生成客户端将数据发送到连接到存储子系统的少数consumer agents。 例如,从数百个Web服务器收集的日志发送给十几个写入HDFS集群的agents。
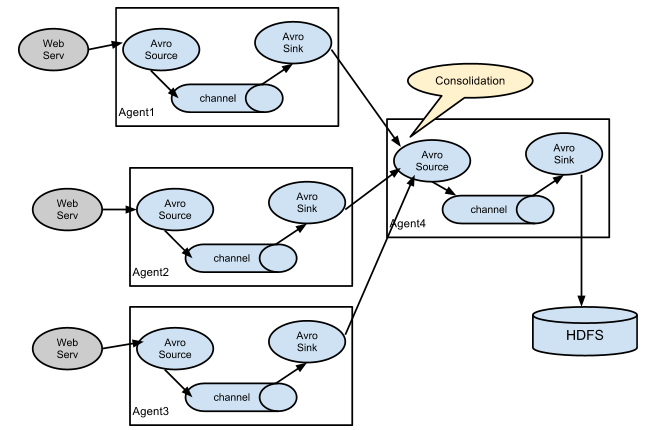
这可以在Flume中通过配置多个第一层agents和一个avro sink来实现,所有代理都指向单一agent的一个avro source(在这种情况下,您也可以使用thrift
sources/sinks/clients)。 第二层agent上的这个source将接收到的事件整合到单个通道中,由通道传送到最终目的地。
2.9 多路复用模式
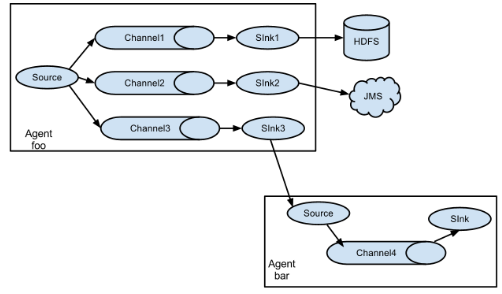
Flume支持将事件流复用到一个或多个目的地。 这是通过定义一个流复用器来实现的,该复用器可以复制或选择性地将一个事件路由到一个或多个通道。
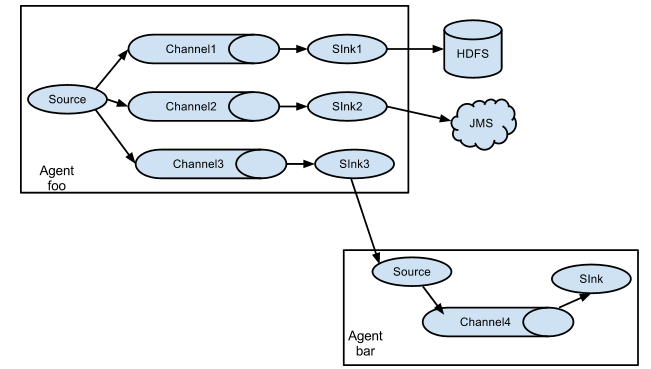
上面的例子显示了一个来自代理“foo”的信息源,将信息流分成三个不同的channel。这fan out可以复制或复用。 在复制流程的情况下,每个事件被发送到所有三个通道。对于复用情况,事件的属性与预先配置的值相匹配时,将事件传递给可用通道的子集。例如,如果一个名为“txnType”的事件属性被设置为“customer”,那么它应该转到channel1和channel3,如果它是“vendor”,那么它应该转到channel2,否则通道3。 映射可以在agent的配置文件中设置。
这种模式,有两种方式,一种是用来复制,另一种是用来分流。配置文件中指定selector的type的值为replication:复制。配置文件中指定selector的type的值为Multiplexing:分流。
博文来自:www.51niux.com
2.10 Configuration
如前面部分所述,Flume代理配置是从类似具有分层属性设置的Java属性文件格式的文件中读取的。
定义流程:
要在一个agent中定义流程,需要通过一个channel将source和sink连接起来,需要给一个agent列出sources,sink和channels,然后将source和sink指向一个channel。一个source实例可以指定多个通道,但一个接收器实例只能指定一个通道。 格式如下:
# list the sources, sinks and channels for the agent <Agent>.sources = <Source> <Agent>.sinks = <Sink>< Agent>.channels = <Channel1> <Channel2> # set channel for source <Agent>.sources.<Source>.channels = <Channel1> <Channel2> ... # set channel for sink <Agent>.sinks.<Sink>.channel = <Channel1>
例如,名为agent_foo的代理正在从外部avro客户端读取数据,并通过内存通道将其发送到HDFS。 配置文件weblog.config可能如下所示:
# list the sources, sinks and channels for the agent agent_foo.sources = avro-appserver-src-1 agent_foo.sinks = hdfs-sink-1 agent_foo.channels = mem-channel-1 # set channel for source agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1 # set channel for sink agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
#上面是这将使事件通过内存通道mem-channel-1从avro-AppSrv-source流向hdfs-Cluster1-sink。 当代理以weblog.config作为配置文件启动时,它将实例化该流。
配置单个组件:
定义流程之后,需要设置每个source,sink和channel的属性。 这是以相同的分层名称空间方式完成的,您可以在其中为每个组件特定的属性设置组件类型和其他值:
# properties for sources <Agent>.sources.<Source>.<someProperty> = <someValue> # properties for channels <Agent>.channel.<Channel>.<someProperty> = <someValue> # properties for sinks <Agent>.sources.<Sink>.<someProperty> = <someValue>
需要为Flume的每个组件设置属性“type”来理解它需要的对象类型。每个source,sink和channel类型都有其自己的一组属性,以使其按预期运行。所有这些都需要根据需要设置。 在前面的例子中,我们有一个来自avro-AppSrv-source到hdfs-Cluster1-sink通过内存通道mem-channel-1。 这是一个显示每个组件的配置的例子:
agent_foo.sources = avro-AppSrv-source agent_foo.sinks = hdfs-Cluster1-sink agent_foo.channels = mem-channel-1 # set channel for sources, sinks # properties of avro-AppSrv-source agent_foo.sources.avro-AppSrv-source.type = avro agent_foo.sources.avro-AppSrv-source.bind = localhost agent_foo.sources.avro-AppSrv-source.port = 10000 # properties of mem-channel-1 agent_foo.channels.mem-channel-1.type = memory agent_foo.channels.mem-channel-1.capacity = 1000 agent_foo.channels.mem-channel-1.transactionCapacity = 100 # properties of hdfs-Cluster1-sinka gent_foo.sinks.hdfs-Cluster1-sink.type = hdfs agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata #...
在agent中添加多个流:
一个Flume代理可以包含多个独立的flows。 可以在配置中列出多个source,sink和channel。 这些组件可以链接形成多个flows:
# list the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Source2> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2>
然后,可以将sources和sinks链接到相应的channels以设置两个不同的流。例如,如果需要在agent中设置两个流程,一个从外部avro客户端到外部HDFS,另一个从尾部输出到avro接收器,则可以使用以下配置:
# list the sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source1 exec-tail-source2 agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2 agent_foo.channels = mem-channel-1 file-channel-2 # flow #1 configuration agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1 # flow #2 configuration agent_foo.sources.exec-tail-source2.channels = file-channel-2 agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
配置多agent flow:
要设置一个多层流,需要一个avro/thrift sink第一跳指向avro/thrift source为下一跳。这将导致第一个Flume agent将事件转发到下一个Flume agent。例如,如果定期使用avro客户端向本地Flume agent发送文件(每个事件一个文件),那么这个本地agent可以将其转发给另一个已安装存储的agent。
Weblog代理配置:
# list sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source agent_foo.sinks = avro-forward-sinka gent_foo.channels = file-channel # define the flowa gent_foo.sources.avro-AppSrv-source.channels = file-channel agent_foo.sinks.avro-forward-sink.channel = file-channel # avro sink properties agent_foo.sinks.avro-forward-sink.type = avro agent_foo.sinks.avro-forward-sink.hostname = 10.1.1.100 agent_foo.sinks.avro-forward-sink.port = 10000 # configure other pieces#...
HDFS代理配置:
# list sources, sinks and channels in the agent agent_foo.sources = avro-collection-source agent_foo.sinks = hdfs-sink agent_foo.channels = mem-channel # define the flow agent_foo.sources.avro-collection-source.channels = mem-channel agent_foo.sinks.hdfs-sink.channel = mem-channel # avro source properties agent_foo.sources.avro-collection-source.type = avro agent_foo.sources.avro-collection-source.bind = 10.1.1.100 agent_foo.sources.avro-collection-source.port = 10000 # configure other pieces #...
在这里,我们将weblog代理的avro-forward-sink链接到hdfs代理的avro-collection-source。 这将导致来自外部应用服务器源的事件最终被存储在HDFS中。
Fan out flow
正如前面部分所讨论的,Flume支持从一个source流向多个信道。删除有复制和复用两种模式。在复制流程中,事件被发送到所有配置的通道。在多路复用的情况下,事件只被发送到合格channel的一个子集。为了扇区流出,需要为指定源指定一个channels列表和一个faning it out策略。这是通过添加可以复制或复用的通道“selector(筛选器)”来完成的。然后进一步指定选择规则,如果它是一个多路复用器。如果您不指定选择器,则默认情况下它是复制:
# List the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2> # set list of channels for source (separated by space) <Agent>.sources.<Source1>.channels = <Channel1> <Channel2> # set channel for sinks <Agent>.sinks.<Sink1>.channel = <Channel1> <Agent>.sinks.<Sink2>.channel = <Channel2> <Agent>.sources.<Source1>.selector.type = replicating
多路复用选择还有一组属性来分流。 这要求指定一个事件属性到一个通道集的映射。选择器检查事件头中的每个配置的属性。 如果它匹配指定的值,则该事件被发送到映射到该值的所有通道。如果没有匹配,则将事件发送到配置为默认值的一组通道:
# Mapping for multiplexing selector <Agent>.sources.<Source1>.selector.type = multiplexing <Agent>.sources.<Source1>.selector.header = <someHeader> <Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1> <Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2> <Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2> #... <Agent>.sources.<Source1>.selector.default = <Channel2>
#映射允许重叠每个值的通道。以下示例具有复用到两个路径的单个流。 名为agent_foo的代理具有一个avro源和两个链接到两个接收器的通道:
# list the sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source1 agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2 agent_foo.channels = mem-channel-1 file-channel-2 # set channels for source agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2 # set channel for sinks agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1 agent_foo.sinks.avro-forward-sink2.channel = file-channel-2 # channel selector configuration agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing agent_foo.sources.avro-AppSrv-source1.selector.header = State agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
#上面是选择器检查名为“State”的标题。 如果值是“CA”,那么它发送到mem-channel-1,如果它的“AZ”则转到文件通道-2或者如果它的“NY”那么两者。 如果“状态”标题没有设置或不匹配任何三个,那么它将转到被指定为“默认”的mem-channel-1。
#选择器还支持可选通道。 要为标题指定可选通道,配置参数“optional”用于以下方式:
# channel selector configuration agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing agent_foo.sources.avro-AppSrv-source1.selector.header = State agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.optional.CA = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
#选择器将首先尝试写入所需的通道,并且如果这些通道中的一个通道不能传输事件,则传输将失败。传输重新再所有通道上进行。一旦所有必需的频道都消费了这些event,那么选择器将尝试写入可选的通道。任何可选渠道去消费这些event发生故障简单地被忽略,而不是重试。
#如果可选通道和特定报头所需通道之间存在重叠,则认为该通道是必需的,而通道故障将导致重试整组所需的通道。 例如,在上面的例子中,对于标题“CA”,mem-channel-1即使被标记为必需和可选,也被认为是必需的频道,并且写入该频道的失败将导致该事件 在为选择器配置的所有通道上重试。
#请注意,如果标题没有任何所需的频道,则该事件将被写入默认频道,并将尝试写入该标题的可选频道。 如果没有指定所需的通道,则指定可选通道仍然会将事件写入默认通道。 如果没有频道被指定为默认频道,并且没有要求,则选择器将尝试将事件写入到可选频道。 在这种情况下,任何失败都会被忽略。
