kubernetes集群学习环境搭建(一)
一、Using Minikube to Create a Cluster(可直接忽略)
1.1 概述
Objectives(目标):
了解什么是Kubernetes集群。 了解什么是Minikube。 使用online terminal启动Kubernetes集群。
Kubernetes Clusters:
Kubernetes协调连接在一起作为单个单元工作的高可用性计算机集群。 Kubernetes中的抽象允许你将容器化的应用程序部署到集群,而无需将它们专门绑定到单个机器。 为了利用这种新的部署模型,需要以一种使应用程序与各个主机脱钩的方式打包应用程序:它们需要进行容器化。 容器化的应用程序比过去的部署模型更加灵活和可用,在过去的部署模型中,将应用程序直接安装到特定的计算机上,而程序包已深度集成到主机中。 Kubernetes以更有效的方式自动在整个集群中分配和调度应用程序容器。 Kubernetes是一个开放源代码平台,可以投入生产。
Kubernetes集群包含两种类型的资源:
Master协调集群 Nodes是运行应用程序的工作程序
Cluster Diagram(集群图):
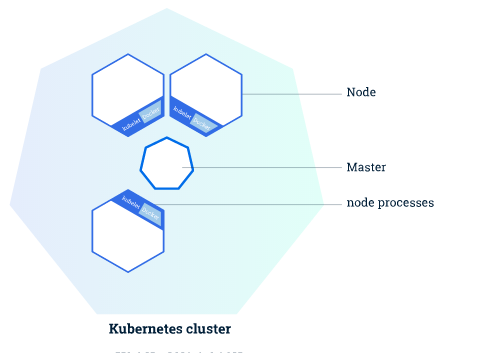
Master负责管理群集。 主服务器协调集群中的所有活动,例如调度应用程序,维护应用程序的所需状态,扩展应用程序以及推出新的更新。
Node是充当Kubernetes集群中的辅助计算机的VM或物理计算机。 每个节点都有一个Kubelet,它是用于管理节点并与Kubernetes主节点通信的代理。 该节点还应该具有用于处理容器操作的工具,例如Docker或rkt。 处理生产流量的Kubernetes集群至少应具有三个节点。
在Kubernetes上部署应用程序时,你告诉master启动应用程序容器。 master计划容器在群集的节点上运行。 Node使用主机公开的Kubernetes API与master进行通信。 最终用户还可以直接使用Kubernetes API与集群进行交互。
Kubernetes集群可以部署在物理机或虚拟机上。 要开始Kubernetes开发,可以使用Minikube。 Minikube是一种轻量级的Kubernetes实现,可在本地计算机上创建VM并部署仅包含一个节点的简单集群。 Minikube可用于Linux,macOS和Windows系统。 Minikube CLI提供了用于引导群集的基本引导程序操作,包括启动,停止,状态和删除。 但是,对于本教程,你将使用预装有Minikube的提供的在线终端。
1.2 Interactive Tutorial - Creating a Cluster(交互式教程-创建集群)
该交互式场景的目标是使用minikube部署本地开发Kubernetes集群
在线终端是一个预配置的Linux环境,可以用作常规控制台(你可以输入命令)。 单击代码块,然后按Enter键,将在终端中执行该命令。
下载minikube:
# wget https://github.com/kubernetes/minikube/releases/download/v1.7.3/minikube-linux-amd64
# chmod +x minikube-linux-amd64
# mv minikube-linux-amd64 /usr/local/bin/minikube
# minikube version
nikube version: v1.7.3 commit: 436667c819c324e35d7e839f8116b968a2d0a3ff
# minikube --help
Minikube是一个CLI工具,可配置和管理为开发工作流程优化的单节点Kubernetes集群。 基本命令: start 启动本地 kubernetes 集群 status 获取本地 kubernetes 集群状态 stop Stops a running local kubernetes cluster delete 删除本地的 kubernetes 集群 dashboard 访问在 minikube 集群中运行的 kubernetes dashboard pause pause containers unpause unpause Kubernetes Images Commands: docker-env Sets up docker env variables; similar to '$(docker-machine env)' podman-env Sets up podman env variables; similar to '$(podman-machine env)' cache 在本地缓存中添加或删除 image。 配置和管理命令: addons Modify minikube's kubernetes addons config Modify minikube config profile Profile gets or sets the current minikube profile update-context Verify the IP address of the running cluster in kubeconfig. Networking and Connectivity Commands: service 获取本地集群中指定服务的 kubernetes URL tunnel tunnel makes services of type LoadBalancer accessible on localhost 高级命令: mount Mounts the specified directory into minikube ssh Log into or run a command on a machine with SSH; similar to 'docker-machine ssh' kubectl Run kubectl Troubleshooting Commands: ssh-key Retrieve the ssh identity key path of the specified cluster ip Retrieves the IP address of the running cluster logs 获取正在运行的实例日志,用于调试 minikube,不是用户代码 update-check Print current and latest version number version Print the version of minikube options 显示全局命令行选项列表 (应用于所有命令)。 Other Commands: completion Outputs minikube shell completion for the given shell (bash or zsh)
# vim /etc/yum.repos.d/kubernetes.repo
name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
#yum install kubectl -y
使用minikube创建k8s集群:
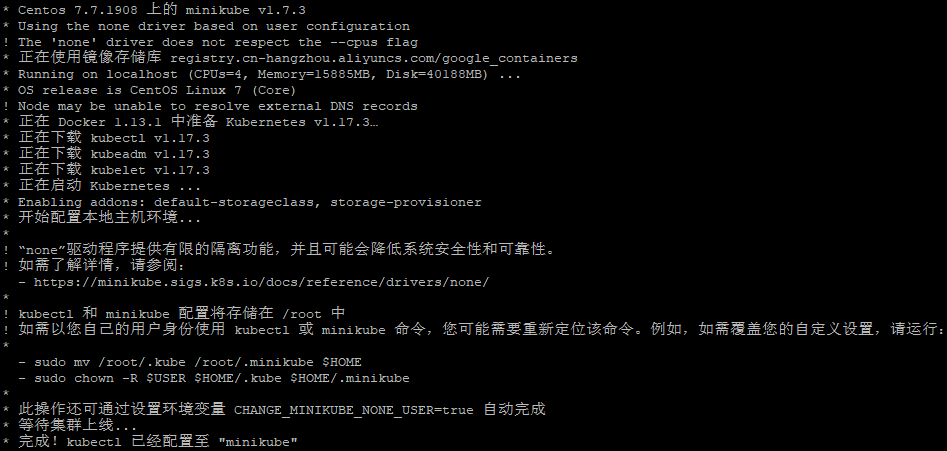
# minikube start --cpus=2 --disk-size='10g' --image-mirror-country='cn' --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers' --vm-driver=none --kubernetes-version v1.17.3
博文来自:www.51niux.com
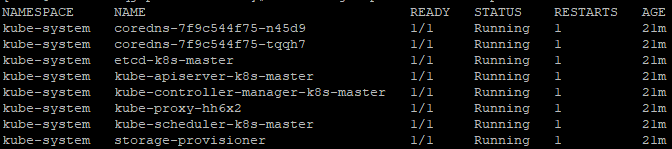
# kubectl get pod --all-namespaces #查看Pod
# minikube status #查看启动状态
host: Running kubelet: Running apiserver: Running kubeconfig: Configured
#注意:不加 --vm-driver=none会有下面报错(如果机器不支持虚拟化的话):
* Centos 7.7.1908 上的 minikube v1.7.3 X 无法确定要使用的默认驱动。尝试通过 --vm-dirver 指定,或者查阅 https://minikube.sigs.k8s.io/docs/start/
#或者再次启动可直接运行# minikube start --vm-driver=none --image-mirror-country='cn' --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers' --kubernetes-version v1.17.3 #不加--image-repository有下面的报错:
! Node may be unable to resolve external DNS records ! 虚拟机无权访问 k8s.gcr.io,或许您需要配置代理或者设置 --image-repository * 正在 Docker 1.13.1 中准备 Kubernetes v1.17.3… * 正在启动 Kubernetes ... * X 开启 cluster 时出错: apiserver healthz: apiserver process never appeared * * 由于出错 minikube 正在退出。如果以上信息没有帮助,请提交问题反馈: - https://github.com/kubernetes/minikube/issues/new/choose
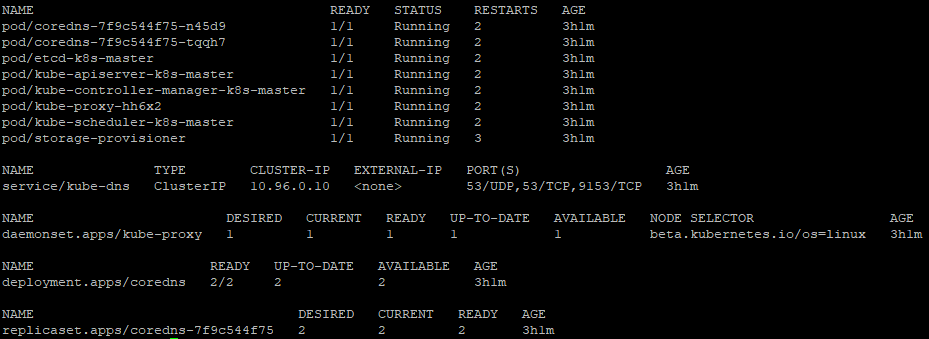
# kubectl get all --namespace=kube-system
# kubectl proxy --address='0.0.0.0' -p 80 #启动dashboard
创建kubernetes-dashboard管理员角色:
# vim k8s-admin.yaml
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
create管理员角色:
kubectl create -f k8s-admin.yaml
获取dashboard管理员角色token:
# kubectl get secret -n kube-system|grep dashboard-admin-token
dashboard-admin-token-9ch6x kubernetes.io/service-account-token 3 78s
# kubectl describe secret dashboard-admin-token-9ch6x -n kube-system
Name: dashboard-admin-token-9ch6x Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: dashboard-admin kubernetes.io/service-account.uid: 896eadce-8b2a-4d07-9457-b207ed00c641 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1066 bytes namespace: 11 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6Im5vV04wd1phdldZVm9DNlV3OWVCMDFYcFI4MnhQanZGa04wak12eWxVYVEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tOWNoNngiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiODk2ZWFkY2UtOGIyYS00ZDA3LTk0NTctYjIwN2VkMDBjNjQxIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.kR3kqbXw6lTPXWZl5s_DR7lAk4LPH50tc0pm1nekmc1TRHc8lNohzTzKWhMUlA2OrmRZTzaDGjXNGlLcRGDzIlefVXy_UkLnHYLoLIuGoI5bs42WxqnxoLsoYQaoKx4rdWE50TCMnOsQJU4nDIWsWj_9lEf5nLlNuX4Wu0bcxdb6uj02bp07vbD84zqNnvzpQxsWBB48PjIf2iOGVDEfRTwXETe4KQq7UgM1x5niZYBtlCUvGYlEPEZcBrX0HJt2yglHNO6TcCzH7o9FydeXiu6zVWUtcHul_lBgvr05o_CaeCyk9SgfSMxfzUJb40jreV9L8cS_P6ZUjlpvJqtLtQ
二、 使用kubeadm部署集群(学习环境)
官网文档:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/#%e5%87%86%e5%a4%87%e5%bc%80%e5%a7%8b
2.1 安装 kubeadm(所有主机都要执行)
确保每个节点上 MAC 地址和 product_uuid 的唯一性:
可以使用命令 ip link 或 ifconfig -a 来获取网络接口的 MAC 地址。
可以使用 sudo cat /sys/class/dmi/id/product_uuid 命令对 product_uuid 校验。
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败。
确保 iptables 工具不使用 nftables 后端:
在 Linux 中,nftables 当前可以作为内核 iptables 子系统的替代品。 iptables 工具可以充当兼容性层,其行为类似于 iptables 但实际上是在配置 nftables。 nftables 后端与当前的 kubeadm 软件包不兼容:它会导致重复防火墙规则并破坏 kube-proxy。
如果你系统的 iptables 工具使用 nftables 后端,则需要把 iptables 工具切换到“旧版”模式来避免这些问题。 默认情况下,至少在 Debian 10 (Buster)、Ubuntu 19.04、Fedora 29 和较新的发行版本中会出现这种问题。RHEL 8 不支持切换到旧版本模式,因此与当前的 kubeadm 软件包不兼容。
# systemctl stop firewalld
# systemctl disable firewalld
# update-alternatives --set iptables /usr/sbin/iptables-legacy
检查所需端口:
control-plane节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443* | Kubernetes API 服务器 | 所有组件 |
| TCP | 入站 | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 10251 | kube-scheduler | kube-scheduler 自身 |
| TCP | 入站 | 10252 | kube-controller-manager | kube-controller-manager 自身 |
工作节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | kubelet 自身、控制平面组件 |
| TCP | 入站 | 30000-32767 | NodePort 服务** | 所有组件 |
** NodePort 服务 的默认端口范围。使用 * 标记的任意端口号都可以被覆盖,所以你需要保证所定制的端口是开放的。
虽然控制平面节点已经包含了 etcd 的端口,你也可以使用自定义的外部 etcd 集群,或是指定自定义端口。
你使用的 pod 网络插件 (见下) 也可能需要某些特定端口开启。由于各个 pod 网络插件都有所不同,请参阅他们各自文档中对端口的要求
安装 runtime:
从 v1.6.0 版本起,Kubernetes 开始默认允许使用 CRI(容器运行时接口)。
从 v1.14.0 版本起,kubeadm 将通过观察已知的 UNIX 域套接字来自动检测 Linux 节点上的容器运行时。 下表中是可检测到的正在运行的 runtime 和 socket 路径。
| 运行时 | 域套接字 |
|---|---|
| Docker | /var/run/docker.sock |
| containerd | /run/containerd/containerd.sock |
| CRI-O | /var/run/crio/crio.sock |
如果同时检测到 docker 和 containerd,则优先选择docker。这是必然的,因为 docker 18.09 附带了 containerd 并且两者都是可以检测到的。 如果检测到其他两个或多个运行时,kubeadm 将以一个合理的错误信息退出。
在非 Linux 节点上,默认使用 docker 作为容器 runtime。
如果选择的容器 runtime 是 docker,则通过内置 dockershim CRI 在 kubelet 的内部实现其的应用。
基于 CRI 的其他 runtimes 有:
containerd (containerd 的内置 CRI 插件) cri-o frakti
安装 kubeadm、kubelet 和 kubectl(所有节点执行):
需要在每台机器上安装以下的软件包:
kubeadm:用来初始化集群的指令。 kubelet:在集群中的每个节点上用来启动 pod 和容器等。 kubectl:用来与集群通信的命令行工具。
博文来自:www.51niux.com
kubeadm 不能 帮你安装或者管理 kubelet 或 kubectl,所以你需要确保它们与通过 kubeadm 安装的控制平面的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。 然而,控制平面与 kubelet 间的相差一个次要版本不一致是支持的,但 kubelet 的版本不可以超过 API 服务器的版本。 例如,1.7.0 版本的 kubelet 可以完全兼容 1.8.0 版本的 API 服务器,反之则不可以。
关闭selinux:
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
# setenforce 0
# sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
关闭swap:
#swapoff -a
#echo "vm.swappiness = 0">> /etc/sysctl.conf
#sed -i 's/.*swap.*/#&/' /etc/fstab
内核设置转发:
一些 RHEL/CentOS 7 的用户曾经遇到过问题:由于 iptables 被绕过而导致流量无法正确路由的问题。你应该确保 在 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 被设置为 1。
#cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
加载modprobe br_netfilter设置网桥:
# modprobe br_netfilter
# lsmod | grep br_netfilter # 确保在此步骤之前已加载了 br_netfilter 模块。
br_netfilter 22256 0 bridge 151336 1 br_netfilter
修改yum源:
#vim /etc/yum.repos.d/kubernetes.repo
[kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 #gpgcheck这里设置成0就直接不检验了 gpgcheck=0 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
#vim /etc/yum.repos.d/docker-ce.repo
[docker-ce-stable] name=Docker CE Stable - $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/stable enabled=1 gpgcheck=1 gpgkey=http://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-stable-debuginfo] name=Docker CE Stable - Debuginfo $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/debug-$basearch/stable enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-stable-source] name=Docker CE Stable - Sources baseurl=http://mirrors.aliyun.com/docker-ce/linux/centos/7/source/stable enabled=0 gpgcheck=1 gpgkey=http://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-edge] name=Docker CE Edge - $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/edge enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-edge-debuginfo] name=Docker CE Edge - Debuginfo $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/debug-$basearch/edge enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-edge-source] name=Docker CE Edge - Sources baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/source/edge enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-test] name=Docker CE Test - $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/test enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-test-debuginfo] name=Docker CE Test - Debuginfo $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/debug-$basearch/test enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-test-source] name=Docker CE Test - Sources baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/source/test enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-nightly] name=Docker CE Nightly - $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/$basearch/nightly enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-nightly-debuginfo] name=Docker CE Nightly - Debuginfo $basearch baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/debug-$basearch/nightly enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg [docker-ce-nightly-source] name=Docker CE Nightly - Sources baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/source/nightly enabled=0 gpgcheck=1 gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
yum安装软件包:
#yum -y install docker-ce
#yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# systemctl enable --now kubelet #kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
# systemctl enable --now docker
# kubeadm version #查看kubeadm版本
kubeadm version: &version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.3", GitCommit:"06ad960bfd03b39c8310aaf92d1e7c12ce618213", GitTreeState:"clean", BuildDate:"2020-02-11T18:12:12Z", GoVersion:"go1.13.6", Compiler:"gc", Platform:"linux/amd64"}在control plane节点上配置 kubelet 使用的 cgroup 驱动程序:
使用 docker 时,kubeadm 会自动为其检测 cgroup 驱动并在运行时对 /var/lib/kubelet/kubeadm-flags.env 文件进行配置。
如果你使用不同的 CRI,你需要使用 cgroup-driver 值修改 /etc/default/kubelet 文件(对于 CentOS、RHEL、Fedora,修改 /etc/sysconfig/kubelet 文件),像这样:KUBELET_EXTRA_ARGS=--cgroup-driver=<value>
这个文件将由 kubeadm init 和 kubeadm join 使用以获取额外的用户自定义的 kubelet 参数。请注意,你只 需要在你的 cgroup 驱动程序不是 cgroupfs 时这么做,因为它已经是 kubelet 中的默认值。需要重新启动 kubelet:
systemctl daemon-reload systemctl restart kubelet
自动检测其他容器运行时的 cgroup 驱动,例如在进程中工作的 CRI-O 和 containerd。
系统配置:
#不同角色的主机设置主机名:
#hostnamectl set-hostname k8s-master
#hostnamectl set-hostname k8s-node01
#hostnamectl set-hostname k8s-node02
#设置主机名解析所有节点一致:
#vi /etc/hosts
192.168.1.138 k8s-master 192.168.1.139 k8s-node01 192.168.1.140 k8s-node02
# kubeadm config 子命令介绍
#kubeadm将配置文件以ConfigMap的形式保存到集群之中,便于后续的查询和升级工作。kubeadm config基本命令后面会用到。
kubeadm config upload from-file:由配置文件上传到集群中生成ConfigMap。 kubeadm config upload from-flags:由配置参数生成ConfigMap。 kubeadm config view:查看当前集群中的配置值。 kubeadm config print init-defaults:输出kubeadm init默认参数文件的内容。 kubeadm config print join-defaults:输出kubeadm join默认参数文件的内容。 kubeadm config migrate:在新旧版本之间进行配置转换。 kubeadm config images list:列出所需的镜像列表。 kubeadm config images pull:拉取镜像到本地。
# kubectl config view --help #如这个后面加上--help可以查看比较详细的使用说明
2.2 安装kubernetes 镜像(所有节点都要执行)
获取需要安装的镜像列表:
# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.17.3 k8s.gcr.io/kube-controller-manager:v1.17.3 k8s.gcr.io/kube-scheduler:v1.17.3 k8s.gcr.io/kube-proxy:v1.17.3 k8s.gcr.io/pause:3.1 k8s.gcr.io/etcd:3.4.3-0 k8s.gcr.io/coredns:1.6.5
#如果执行此命令报错请执行下面的操作:
# kubeadm config images pull #验证与gcr.io容器image registry的连接
failed to pull image "k8s.gcr.io/kube-apiserver:v1.17.3": output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) , error: exit status 1 To see the stack trace of this error execute with --v=5 or higher
提前将镜像下载下来并tag替换:
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.17.3
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.17.3
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.17.3
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.17.3
docker pull registry.aliyuncs.com/google_containers/pause:3.1
docker pull registry.aliyuncs.com/google_containers/etcd:3.4.3-0
docker pull registry.aliyuncs.com/google_containers/coredns:1.6.5
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.17.3 k8s.gcr.io/kube-apiserver:v1.17.3
docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.17.3 k8s.gcr.io/kube-controller-manager:v1.17.3
docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.17.3 k8s.gcr.io/kube-scheduler:v1.17.3
docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.17.3 k8s.gcr.io/kube-proxy:v1.17.3
docker tag registry.aliyuncs.com/google_containers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag registry.aliyuncs.com/google_containers/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0
docker tag registry.aliyuncs.com/google_containers/coredns:1.6.5 k8s.gcr.io/coredns:1.6.5
注:当然也可以使用kubeadm init --image-repository registry.aliyuncs.com/google_containers #指定镜像源
2.3 初始化集群
官网初始化的解释:
初始化control-plane节点:
control-plane节点是运行control-plane组件的机器,包括etcd(集群数据库)和API服务器(kubectl命令行工具与之通信)。
(推荐)如果计划将单个控制平面kubeadm集群升级到高可用性,则应指定--control-plane-endpoint来设置所有控制平面节点的共享端点。 这样的端点可以是负载均衡器的DNS名称或IP地址。
选择一个Pod网络插件,并验证是否需要将任何参数传递给kubeadm init。 根据你选择的第三方提供商,你可能需要将--pod-network-cidr设置为提供商特定的值。 请参阅安装Pod网络附加组件:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#pod-network
(可选)自版本1.14开始,kubeadm尝试使用一系列众所周知的域套接字路径来检测Linux上的容器运行时。 要使用不同的容器运行时,或者如果在已配置的节点上安装了多个容器,请在kubeadm init中指定--cri-socket参数。 请参阅Installing runtime。
(可选)除非另有说明,否则kubeadm使用与默认网关关联的网络接口来为此特定控制平面节点的API服务器设置advertise地址。 要使用其他网络接口,请在kubeadm init中指定--apiserver-advertise-address = <ip-address>参数。 要使用IPv6寻址部署IPv6 Kubernetes集群,必须指定一个IPv6地址,例如--apiserver-advertise-address=fd00::101
(可选)在kubeadm初始化之前运行kubeadm config images pull,以验证与gcr.io容器image registry的连接。
要初始化control-plane节点,请运行:
kubeadm init <args>
关于apiserver-advertise-address和ControlPlaneEndpoint的注意事项:
虽然--apiserver-advertise-address可用于为此特定控制平面节点的API服务器设置advertise地址,但--control-plane-endpoint可用于为所有控制平面节点设置共享端点。
--control-plane-endpoint允许IP地址,但也可以映射到IP地址的DNS名称。 请与你的网络管理员联系,以评估有关此类映射的可能解决方案。这是一个示例映射:192.168.0.102 cluster-endpoint
其中192.168.0.102是此节点的IP地址,而群集端点是映射到该IP的自定义DNS名称。 这将允许你将--control-plane-endpoint=cluster-endpoint传递给kubeadm init,并将相同的DNS名称传递给kubeadm join。 稍后,可以修改群集端点,以指向高可用性方案中的负载均衡器的地址。
kubeadm不支持将没有--control-plane-endpoint创建的单个控制平面集群转换为高可用性集群。
初始化control-plane节点(这里是master节点):
# kubeadm init --kubernetes-version=v1.17.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 #下面是最后的消息
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.1.138:6443 --token k4im2b.0j14jrybfwri6z5t \ --discovery-token-ca-cert-hash sha256:01c635f5057ffa14e86e7eced135e0796090688a6e1d02160cfdb8e3c3fbfb81
#下面是一些常用参数:
--kubernetes-version: 用于指定k8s版本;
--apiserver-advertise-address:用于指定kube-apiserver监听的ip地址,就是 master本机IP地址。
--pod-network-cidr:用于指定Pod的网络范围; 10.244.0.0/16
--service-cidr:用于指定SVC的网络范围;
--image-repository: 指定阿里云镜像仓库地址
#kubeadm init --config=init.yaml 把参数按照规范写入到yaml文件中指定yaml文件进行初始化。
# kubectl get -n kube-system configmap #可以看看是否生成了名为kubeadm-config的ConfigMap对象
#如下面是比较全的命令,当然默认kube-apiserver监听的ip地址就是当前的ip地址,镜像我们已经提前下载好了也不用指定:
# kubeadm init --kubernetes-version=v1.17.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --apiserver-advertise-address=192.168.1.138 --image-repository=registry.aliyuncs.com/google_containers
#如果kubelet报错:
# tail -f /var/log/messages
"Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""
#这是因为docker和k8s使用的cgroup不一致导致。修改二者一致,统一使用systemd或者cgroupfs进行资源管理。由于k8s官方文档中提示使用cgroupfs管理docker和k8s资源,而使用systemd管理节点上其他进程资源在资源压力大时会出现不稳定,因此推荐修改docker和k8s统一使用systemd管理资源。
# docker info|grep 'Cgroup Driver'
Cgroup Driver: cgroupfs
#要么改docker的要么改kubelet的,我们这里改kubelet的。
#vim /var/lib/kubelet/config.yaml
#cgroupDriver: systemd cgroupDriver: cgroupfs
# service kubelet restart
# service kubelet status #查看状态
#但是存在一个问题哈,/var/lib/kubelet/config.yaml是在执行完kubeadm命令才有的,所以就需要执行完kubeadm出错了,再去修改kubelet文件。修改docker,只需在/etc/docker/daemon.json中,添加"exec-opts": ["native.cgroupdriver=systemd"]即可
按提示执行命令:
#如果是非root用户就是下面的操作:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
#如果是root用户就是下面的操作:
# export KUBECONFIG=/etc/kubernetes/admin.conf
# echo 'export KUBECONFIG=/etc/kubernetes/admin.conf' >>/etc/profile
# source /etc/profile
#这token用于控制平面节点和加入节点之间的相互身份验证。 这里包含的token的secret。 确保安全,因为拥有此令牌的任何人都可以将经过身份验证的节点添加到你的集群中。 可以使用kubeadm token命令列出,创建和删除这些token。
让node节点加入集群(在另外两台node节点上面执行下面的命令):
#kubeadm join 192.168.1.138:6443 --token 92kk2e.yscrjv99h97i09ra \
--discovery-token-ca-cert-hash sha256:5579bd45fe4fa0e978d371366183ade6dfedb93a7298cfec083f2dcce306f04e
[preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
在master节点查看一下当前节点:
# kubectl get nodes
NAME STATUS ROLES AGE VERSION k8s-master NotReady master 10m v1.17.3 k8s-node01 NotReady <none> 2m32s v1.17.3 k8s-node02 NotReady <none> 0s v1.17.3
#可以看到三个节点都已经在了,但是都是NotReady状态
# kubectl get cs #查看组件状态
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}#如果出现:
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
# vim /etc/kubernetes/manifests/kube-scheduler.yaml
#- --port=0 #上面的报错原因是设置的默认端口是0导致的,解决方式是注释掉对应的port即可
# service kubelet restart
博文来自:www.51niux.com
# service kubelet status #查看一下kubelet状态
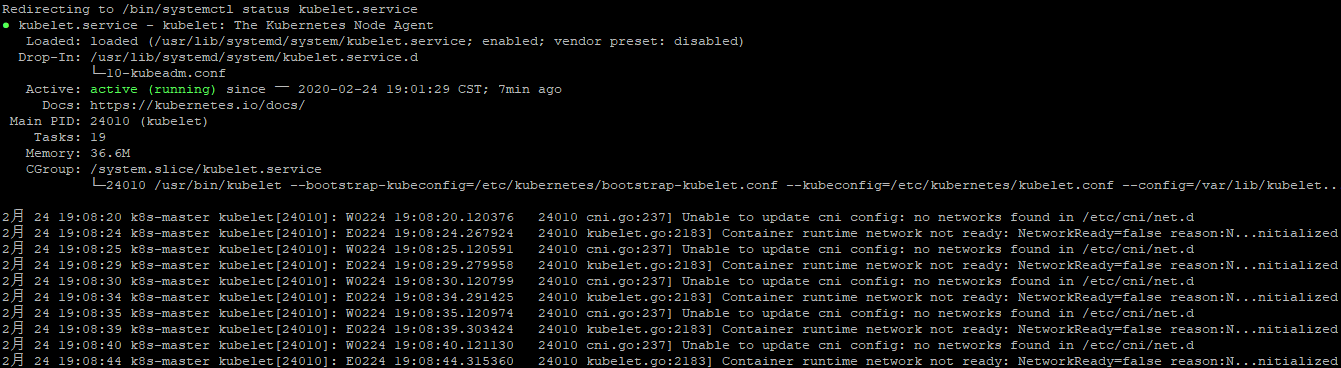
2月 24 19:08:40 k8s-master kubelet[24010]: W0224 19:08:40.121130 24010 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d 2月 24 19:08:44 k8s-master kubelet[24010]: E0224 19:08:44.315360 24010 kubelet.go:2183] Container runtime network not ready: NetworkReady=false reason:N...nitialized
#上面报错的意思是还缺少网络插件。
#如果想要重置重来:
kubeadm reset iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X systemctl stop kubelet systemctl stop docker rm -rf /var/lib/cni/* rm -rf /var/lib/kubelet/* rm -rf /etc/cni/* ifconfig cni0 down ifconfig flannel.1 down ifconfig docker0 down ip link delete cni0 ip link delete flannel.1 systemctl start docker
#然后重新开始最初的kubeadm init便可。
2.4 安装Pod网络附加组件
还是跟着官网了解一下:
警告:
本节包含有关网络设置和部署顺序的重要信息。必须部署基于容器网络接口(CNI)的Pod网络附加组件,以便你的Pod可以相互通信。在安装网络之前,群集DNS(CoreDNS)将不会启动。
请注意,你的Pod网络不得与任何主机网络重叠:如果有任何重叠,你很可能会遇到问题。(如果你发现网络插件的首选Pod网络与某些主机网络之间存在冲突,则应考虑使用一个合适的CIDR块来代替,然后在kubeadm初始化期间使用--pod-network-cidr并将其替换 在你的网络插件的YAML中)。
默认情况下,kubeadm将你的集群设置为使用和强制使用RBAC(基于角色的访问控制)。确保你的Pod网络插件支持RBAC,以及用于部署它的所有清单也是如此。
如果要为群集使用IPv6(仅双协议栈或单协议栈IPv6网络),请确保Pod网络插件支持IPv6。IPv6支持已在v0.6.0中添加到CNI。
一些外部项目使用CNI提供Kubernetes Pod网络,其中一些还支持网络策略:https://kubernetes.io/docs/concepts/services-networking/networkpolicies/
请参阅可用网络和网络策略加载项列表:https://kubernetes.io/docs/concepts/cluster-administration/addons/#networking-and-network-policy
可以使用以下命令在控制平面节点或具有kubeconfig凭据的节点上安装Pod网络附加组件:kubectl apply -f <add-on.yaml>
每个群集只能安装一个Pod网络。 可以在下面找到一些流行的Pod网络插件的安装说明:
#地址:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml
安装flannel网络插件(master节点操作就行):
# kubectl get pods --all-namespaces
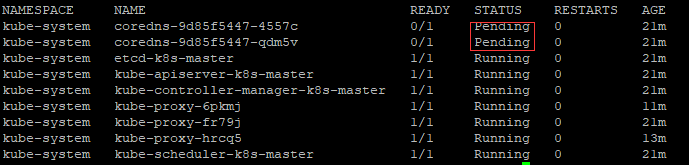
#从上图可以看到我们的coredns果然处于等待状态,其他的组件已经启动起来了。
下载kube-flannel.yml:
# docker pull quay.io/coreos/flannel:v0.11.0-amd64
# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds-amd64 created daemonset.apps/kube-flannel-ds-arm64 created daemonset.apps/kube-flannel-ds-arm created daemonset.apps/kube-flannel-ds-ppc64le created daemonset.apps/kube-flannel-ds-s390x created
再次查看:
# kubectl get nodes
NAME STATUS ROLES AGE VERSION k8s-master Ready master 71m v1.17.3 k8s-node01 Ready <none> 64m v1.17.3 k8s-node02 Ready <none> 61m v1.17.3
# kubectl get pod -n kube-system
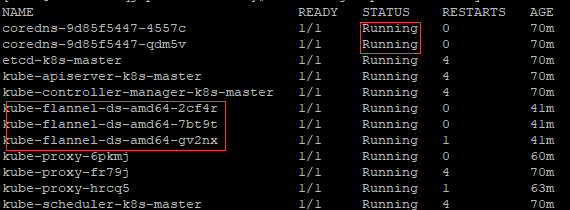
# kubectl get ns #查看当前的命名空间
NAME STATUS AGE default Active 77m kube-node-lease Active 77m kube-public Active 77m kube-system Active 77m
# kubectl get pods -n kube-system -o wide #可以查看组件都部署在哪几个节点上面
# kubectl get pods -n kube-system -o wide|grep node #可见kube-proxy和kube-flannel都会部署在每一个节点上面
coredns-9d85f5447-4557c 1/1 Running 0 78m 10.244.2.3 k8s-node02 <none> <none> coredns-9d85f5447-qdm5v 1/1 Running 0 78m 10.244.2.2 k8s-node02 <none> <none> kube-flannel-ds-amd64-2cf4r 1/1 Running 0 50m 192.168.1.140 k8s-node02 <none> <none> kube-flannel-ds-amd64-gv2nx 1/1 Running 2 50m 192.168.1.139 k8s-node01 <none> <none> kube-proxy-6pkmj 1/1 Running 0 68m 192.168.1.140 k8s-node02 <none> <none> kube-proxy-hrcq5 1/1 Running 2 71m 192.168.1.139 k8s-node01 <none> <none>
网卡查看:
master节点查看:
# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
node01节点查看:
# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
node02节点查看:
# ifconfig
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.2.1 netmask 255.255.255.0 broadcast 0.0.0.0 docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
2.5 关于集群加入的令牌
#如果忘记了join时的token可以在master节点上面执行:# kubeadm token list
默认情况下,令牌会在24小时后过期。 如果要在当前令牌过期后将节点加入集群,则可以通过在控制平面节点上运行以下命令来创建新令牌:
#kubeadm token create #输出类似于下面的输出
5didvk.d09sbcov8ph2amjw
如果你没有--discovery-token-ca-cert-hash的值,则可以通过在控制平面节点上运行以下命令链来获取它:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \ openssl dgst -sha256 -hex | sed 's/^.* //'
输出类似于:
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
注意:要为<control-plane-host>:<control-plane-ip>指定IPv6 address,必须将IPv6地址括在方括号中,例如:[fd00::101]:2073。
2.6 Clean up(清理)
如果你在群集中使用了一次性服务器,则可以进行测试,将其关闭,而无需进一步清理。 你可以使用kubectl config delete-cluster删除对集群的本地引用。但是,如果要更干净地取消配置群集,则应首先排空该节点并确保该节点为空,然后取消配置该节点。
Remove the node(删除节点):
与控制平面节点使用适当的凭据进行对话,请运行:
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
然后,在要删除的节点上,重置所有kubeadm安装状态:kubeadm reset
重置过程不会重置或清除iptables规则或IPVS表。 如果你希望重置iptables,则必须手动进行:
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
如果要重置IPVS表,则必须运行以下命令:ipvsadm -C
如果你想重新开始,只需运行kubeadm init或kubeadm加入适当的参数。
Clean up the control plane:
可以在控制平面主机上使用kubeadm reset来触发尽力而为的清理。
博文来自:www.51niux.com
三、Web UI (Dashboard)
官网链接:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dash
3.1 部署Dashboard
默认情况下,仪表板用户界面未部署。 要部署它,请运行以下命令:
#kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-beta8/aio/deploy/recommended.yaml
namespace/kubernetes-dashboard created serviceaccount/kubernetes-dashboard created service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created
# kubectl get ns
NAME STATUS AGE default Active 112m kube-node-lease Active 112m kube-public Active 112m kube-system Active 112m kubernetes-dashboard Active 5m46s #新增加了一个命令空间
# kubectl get pods -n kubernetes-dashboard -o wide

3.2 访问 Dashboard UI
为了保护你的群集数据,默认情况下,Dashboard会使用最少的RBAC配置进行部署。 当前,仪表板仅支持使用Bearer令牌登录。 要为此演示创建令牌,你可以按照我们的指南创建样本用户:https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
Command line proxy(测试了解一下就好了没有用这种方式):
可以通过运行以下命令,使用kubectl命令行工具访问仪表板:kubectl proxy
# kubectl proxy --address=192.168.1.138 -p 80 --disable-filter=true & #然后访问浏览器输入下面的地址(先用火狐浏览器)
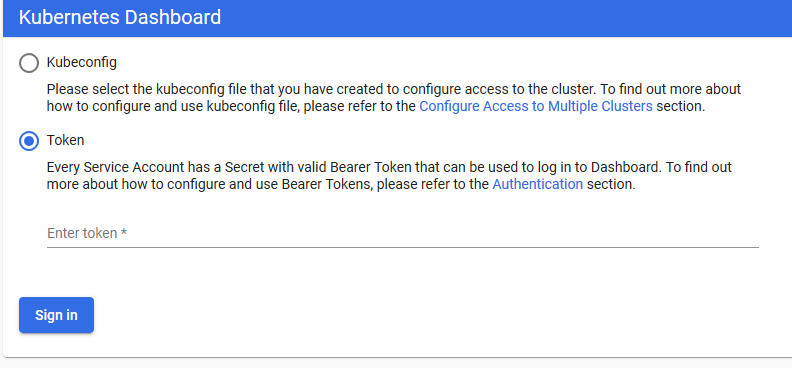
注意:Kubeconfig身份验证方法不支持外部身份提供程序或基于x509证书的身份验证。
如果是直接:https://192.168.1.138访问呢?
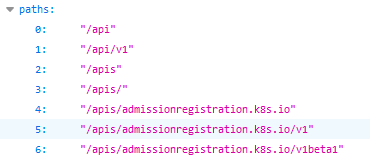
#显示的都是api接口,通过不同的path拼接可以获取不同的值
#--disable-filter=true意思也就是让apiserver中的- --anonymous-auth=false(apiserver配置文件路径:/etc/kubernetes/manifests/kube-apiserver.yaml),如果你的命令中没有加这个参数,页面只会出现Forbidden表示匿名用户没有权限访问
3.3 kubernetes-dashboard方式访问
如果yaml文件里面的镜像下载不下来:
spec:
containers:
- name: kubernetes-dashboard
#image: kubernetesui/dashboard:v2.0.0-beta8
#imagePullPolicy: Always
image: registry.cn-hangzhou.aliyuncs.com/google_containers/kubernetes-dashboard-amd64:v1.10.1
imagePullPolicy: IfNotPresent
#找到镜像地方,将要下载的镜像替换成阿里云提供的镜像然后选择如果本地有镜像就不去更新下载镜像了
使用nodeport的方式启动:
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #这里为新加项,为选择NodePort类型
ports:
- port: 443
targetPort: 8443
nodePort: 30002 #这里表示将端口映射到所在Node的30002端口
创建超级用户权限:
# vim k8s-admin.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: dashboard-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
# kubectl apply -f k8s-admin.yaml
serviceaccount/dashboard-admin created clusterrolebinding.rbac.authorization.k8s.io/dashboard-admin created
获取管理员token:
# kubectl get secret -n kube-system|grep admin
dashboard-admin-token-dr5w7 kubernetes.io/service-account-token 3 26s
# kubectl describe secret dashboard-admin-token-dr5w7 -n kube-system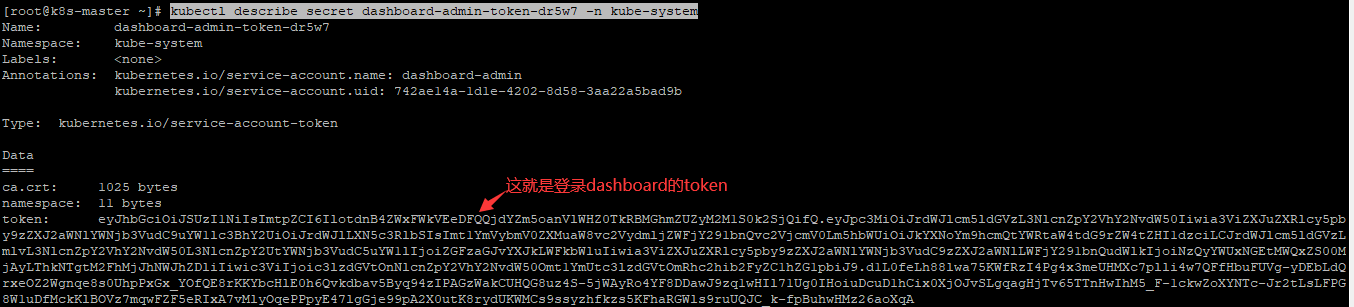
重新启动dashboard:
#上面我们针对yaml文件做了一些修改,比如启动了nodeport的方式。
# kubectl delete -f recommended.yaml
# kubectl apply -f recommended.yaml
访问dashboard:
直接浏览器访问:https://192.168.1.138:30002/
#因为我们没有做浏览器证书认证,但是必须使用https协议,所以先用浏览器忽略这个风险。
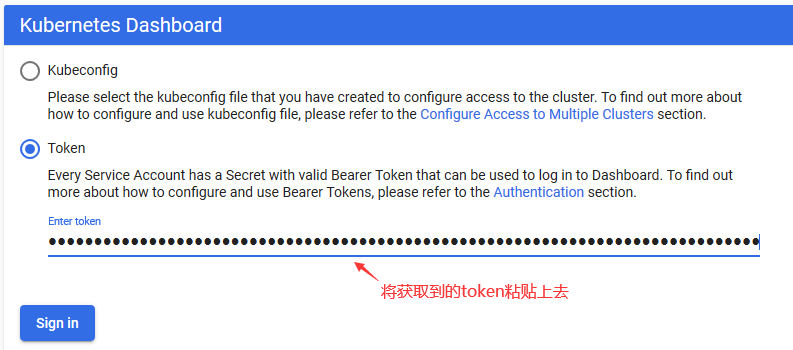
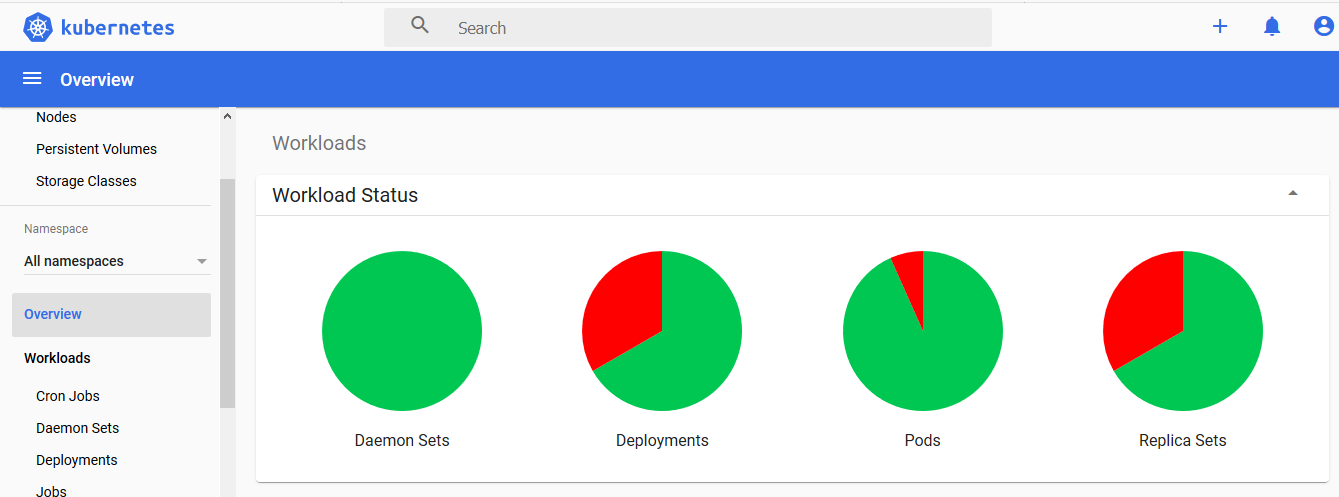

#用dashboard创建了一个tomcat也成功了
记得关注消息通知(如果你的授权不对就算登陆进来了也可能会有其他问题,如下面的示例):
#https://192.168.1.138:30002/#/clusterrole?namespace=default #点进来默认是这个链接哈
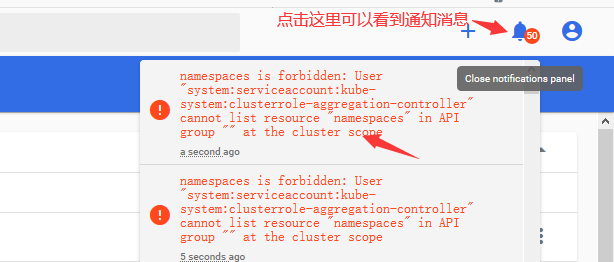
报错信息: namespaces is forbidden: User "system:serviceaccount:kube-system:clusterrole-aggregation-controller" cannot list resource "namespaces" in API group "" at the cluster scope
报错信息: pods is forbidden: User "system:serviceaccount:kube-system:namespace-controller" cannot create resource "pods" in API group "" in the namespace "default"
#上面的两个错误都属于token权限不对,要好好确认一下是不是复制的kube-system下面的admin的token.要么你授权的admin用户的token的角色不对,要么API组中用户不能在默认命名空间创建Pod。
3.4 官网翻译dashboard的使用
部署容器化的应用程序之Specifying application details(指定应用程序详细信息):
通过仪表板,你可以使用简单的向导将容器化的应用程序创建和部署为部署和可选服务。 你可以手动指定应用程序详细信息,也可以上传包含应用程序配置的YAML或JSON文件。单击任何页面右上角的CREATE按钮以开始。
部署向导期望你提供以下信息:
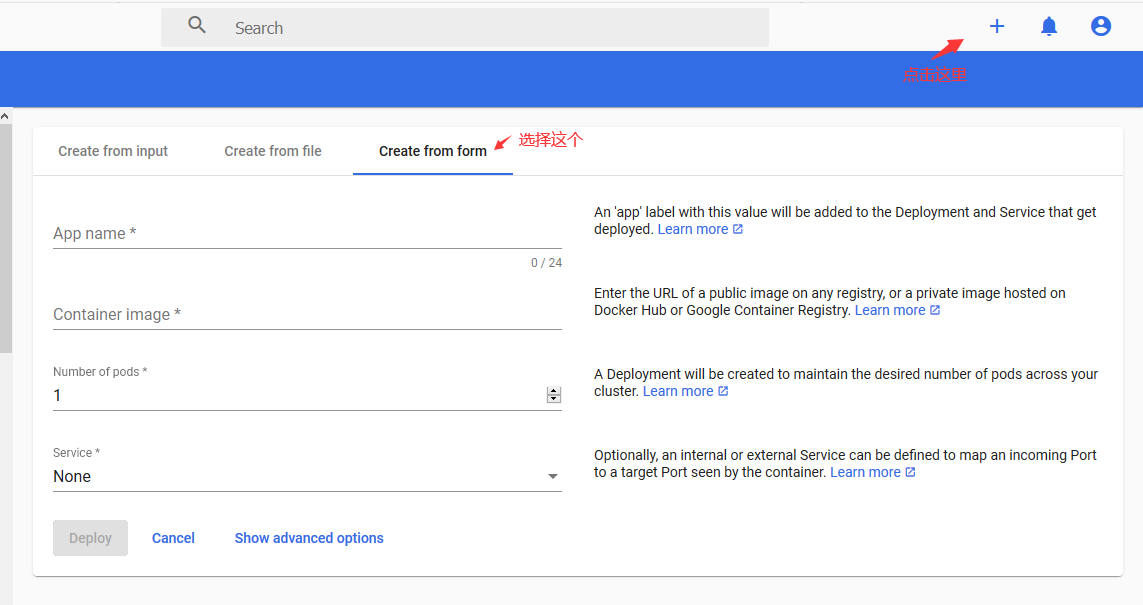
App name (必填):
你的应用名称。 具有名称的标签将被添加到将要部署的Deployment and Service(如果有)中。
在选定的Kubernetes命名空间中,应用程序名称必须唯一。 它必须以小写字母开头,以小写字母或数字结尾,并且只能包含小写字母,数字和破折号(-)。 最多24个字符。 前导和尾随空格将被忽略。
Container image (必填):
任何registry上的公共Docker容器iamge或私有image(通常托管在Google Container Registry或Docker Hub上)的URL。 容器iamge规范必须以冒号结尾。
Number of pods (强制性):
要在其中部署应用程序的Pod的目标数量。该值必须为正整数。
将创建一个Deployment,以在整个集群中维持所需数量的Pod。
Service (可选):
对于应用程序的某些部分(例如前端),你可能希望将服务公开到群集外部的外部(也许是公共IP)地址(外部服务)。 对于外部服务,你可能需要打开一个或多个端口。 在此处查找更多详细信息:https://kubernetes.io/docs/tasks/access-application-cluster/configure-cloud-provider-firewall/
仅在群集内部可见的其他服务称为内部服务。
不论服务类型如何,如果你选择创建服务,并且你的容器侦听端口(incoming),则需要指定两个端口。 将创建服务,将端口(incoming)映射到容器看到的目标端口。 该服务将路由到你部署的Pod。 支持的协议是TCP和UDP。 此服务的内部DNS名称将是您在上面指定为应用程序名称的值。
如果需要,可以展开“Advanced options (高级选项)”部分,在其中可以指定更多设置:
Description:
在此处输入的文本将作为批注添加到“Show Advanced options”中,并显示在应用程序的详细信息中。
Labels:
用于你的应用程序的默认标签是应用程序名称和版本。 你可以指定要应用于“Deployment”,“Service”(如果有)和“Pods”的其他标签,例如release, environment, tier, partition, and release track(发行版,环境,层,分区和发行版)。
Example:
release=1.0 tier=frontend environment=pod track=stable
Namespace:
Kubernetes支持由同一物理群集支持的多个虚拟群集。 这些虚拟群集称为名称空间。 它们使你可以将资源划分为逻辑命名的组。
仪表板在下拉列表中提供所有可用的名称空间,并允许你创建新的名称空间。 名称空间名称最多可以包含63个字母数字字符和破折号(-),但不能包含大写字母。 命名空间名称不应仅由数字组成。 如果名称设置为数字,例如10,则pod将放置在默认名称空间中。如果成功创建了命名空间,则默认情况下将其选中。 如果创建失败,则选择第一个名称空间。
Image Pull Secret:
如果指定的Docker容器映像为私有image,则可能需要pull secret凭证。
仪表板在下拉列表中提供所有可用的机密,并允许您创建一个新secrets。 secrets名称必须遵循DNS域名语法,例如 new.image-pull.secret。 secrets内容必须经过base64编码,并在.dockercfg文件中指定。secrets名称最多可以包含253个字符。如果成功创建image请求密钥,则默认情况下将其选中。 如果创建失败,则不会应用任何secrets。
CPU requirement (cores) and Memory requirement (MiB):
可以指定容器的最小资源限制。 默认情况下,Pod在不受限制的CPU和内存限制下运行。
Run command and Run command arguments(运行命令和运行命令参数):
默认情况下,你的容器运行指定的Docker image的默认entrypoint command。 你可以使用命令选项和参数来覆盖默认值。
Run as privileged(以特权身份运行):
此设置确定特权容器中的进程是否等效于在主机上以root用户身份运行的进程。 特权容器可以利用诸如操纵网络堆栈和访问设备之类的功能。
Environment variables:
Kubernetes通过环境变量公开服务。 你可以编写环境变量或使用环境变量的值将参数传递给命令。 可以在应用程序中使用它们来查找服务。 值可以使用$(VAR_NAME)语法引用其他变量。
部署容器化的应用程序之Uploading a YAML or JSON file(上载YAML或JSON文件):
Kubernetes支持声明式配置。 通过这种样式,所有配置都使用Kubernetes API资源架构存储在YAML或JSON配置文件中。作为在部署向导中指定应用程序详细信息的替代方法,你可以在YAML或JSON文件中定义应用程序,然后使用仪表板上传文件。
Using Dashboard:
以下各节描述了Kubernetes Dashboard UI的视图; 他们提供什么以及如何使用它们。
Navigation(导航):
当集群中定义了Kubernetes对象时,仪表板会在初始视图中显示它们。 默认情况下,仅显示默认名称空间中的对象,并且可以使用位于导航菜单中的名称空间选择器进行更改。仪表板显示大多数Kubernetes对象种类并将它们分组在几个菜单类别中。
Admin Overview:
对于集群和名称空间管理员,仪表板列出了节点,名称空间和持久卷,并具有它们的详细视图。 节点列表视图包含所有节点上汇总的CPU和内存使用情况指标。 详细信息视图显示运行的节点上的指标,其specification, status, allocated resources, events(规格,状态,分配的资源,事件和Pod)。
Workloads:
显示在选定名称空间中运行的所有应用程序。 该视图按工作负载类型(例如,部署,副本集,状态集等)列出应用程序,并且可以分别查看每种工作负载类型。 列表总结了有关工作负载的可操作信息,例如,副本集准备就绪的窗格数或Pod的当前内存使用情况。
工作负载的详细视图显示状态和规格信息以及对象之间的表面关系。 例如,副本集控制的Pod或“新副本集”和“用于部署的水平Pod自动缩放器”。
Services:
显示Kubernetes资源,这些资源允许将服务公开给外部世界并在集群中发现它们。 因此,Service and Ingress视图显示它们所针对的Pod,用于群集连接的内部端点和用于外部用户的外部端点。
Storage:
存储视图显示了持久卷声明资源,应用程序使用它们来存储数据。
Config Maps and Secrets:
显示用于对集群中运行的应用程序进行实时配置的所有Kubernetes资源。 该视图允许编辑和管理配置对象,并显示默认情况下hidden的secrets。
Logs viewer:
Pod lists和详细信息页面链接到仪表板中内置的日志查看器。 查看器允许从属于单个Pod的容器中drilling down logs。
核心组件的启动参数就不一一翻译了直接看官网即可:https://kubernetes.io/docs/reference/command-line-tools-reference/
