open-falcon之进程监控和Expression(三)
一、进程监控
#此进程监控只适用于那种进程名称唯一的,如果是java进程可能启多个java服务就不太合适了,像falcon-agent这种进程就挺合适。
1.1 官网解释
进程监控和端口监控类似,也是通过用户配置的策略自动计算出来要采集哪个进程的信息然后上报。举个例子:
proc.num/name=ntpd if all(#2) == 0 then alarm() proc.num/name=crond if all(#2) == 0 then alarm() proc.num/cmdline=uic.properties if all(#2) == 0 then alarm()
proc.num表示进程数,比如进程名叫做crond的进程,其实可以有多个。支持两种tag配置,一个是进程name,一个是配置进程cmdline,但是不能同时出现。
那现在DEV写了一个程序,我怎么知道进程名呢? 首先要拿到进程ID,然后cat /proc/$pid/status,看到里面的name字段了么?falcon-agent就是根据这个name字段来采集的。此处有个坑,就是这个name字段最多15个字节,所以,如果你的进程名特别长可能被截断,截断之前的原始进程名我们不管,agent以这个status文件中的name为准。所以,你配置name这个tag的时候,一定要看一眼这个status文件,从这里获取name,而不是想当然的去写一个你自认为对的进程名。
再说说cmdline,name是从/proc/$pid/status文件采集的,cmdline是从/proc/$pid/cmdline采集的。这个文件存放的是你启动进程的时候用到的命令,比如你用java -c uic.properties启动了一个Java进程,进程名是java,其实所有的java进程,进程名都是java,那我们是没法通过name字段做区分的。怎么办呢?此时就要求助于这个/proc/$pid/cmdline文件的内容了。
cmdline中的内容是你的启动命令,这么说不准确,你会发现空格都没了。其实是把空格自动替换成\0了。不用关心,直接鼠标选中,拷贝之即可。不要自以为是的手工加空格配置到策略中哈,监控策略的tag是不允许有空格的。上面的例子,java -c uic.properties在cmdline中的内容会变成:java-cuic.properties,无需把整个cmdline都拷贝并配置到策略中。虽然name这个tag是全匹配的,即用的==比较name,但是cmdline不是,我们只需要拷贝cmdline的一部分字符串,能够与其他进程区分开即可。比如上面的配置:
proc.num/cmdline=uic.properties if all(#2) == 0 then alarm()
就已经OK了。falcon-agent拿到cmdline文件的内容之后会使用strings.Contains()方法来做判断。
博文来自:www.51niux.com
1.2 进程监控例子
#这里就以postfix进程举例把。
找出进程的名称:
# ps -ef|grep postfix #可以看到postfix进程是1068
root 1068 1 0 11月07 ? 00:00:01 /usr/libexec/postfix/master -w postfix 1072 1068 0 11月07 ? 00:00:00 qmgr -l -t unix -u postfix 86204 1068 0 17:18 ? 00:00:00 pickup -l -t unix -u
# netstat -lntup|grep 25 #可以再合适一下确实是1068的PID
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1068/master tcp6 0 0 ::1:25 :::* LISTEN 1068/master
# cat /proc/1068/status #可以看到Name是master
Name: master Umask: 0077 State: S (sleeping) Tgid: 1068 Ngid: 0 Pid: 1068 PPid: 1 TracerPid: 0 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 128 Groups: 0
配置Templates:
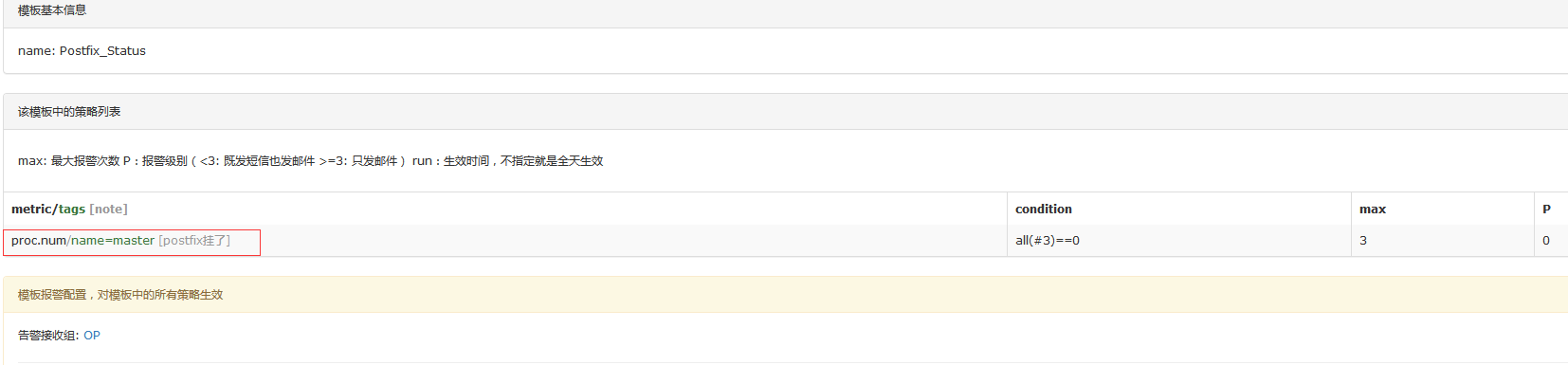
配置HostGroups:
#这里就不截图了。就是再创建一个Postfix的主机组然后引用上面的模板,然后哪个机器的postfix进程要监控就加入到这个主机组就行了。
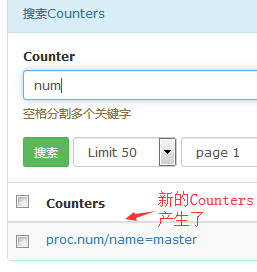
#加入此主机组的主机会产生一个新的Counters
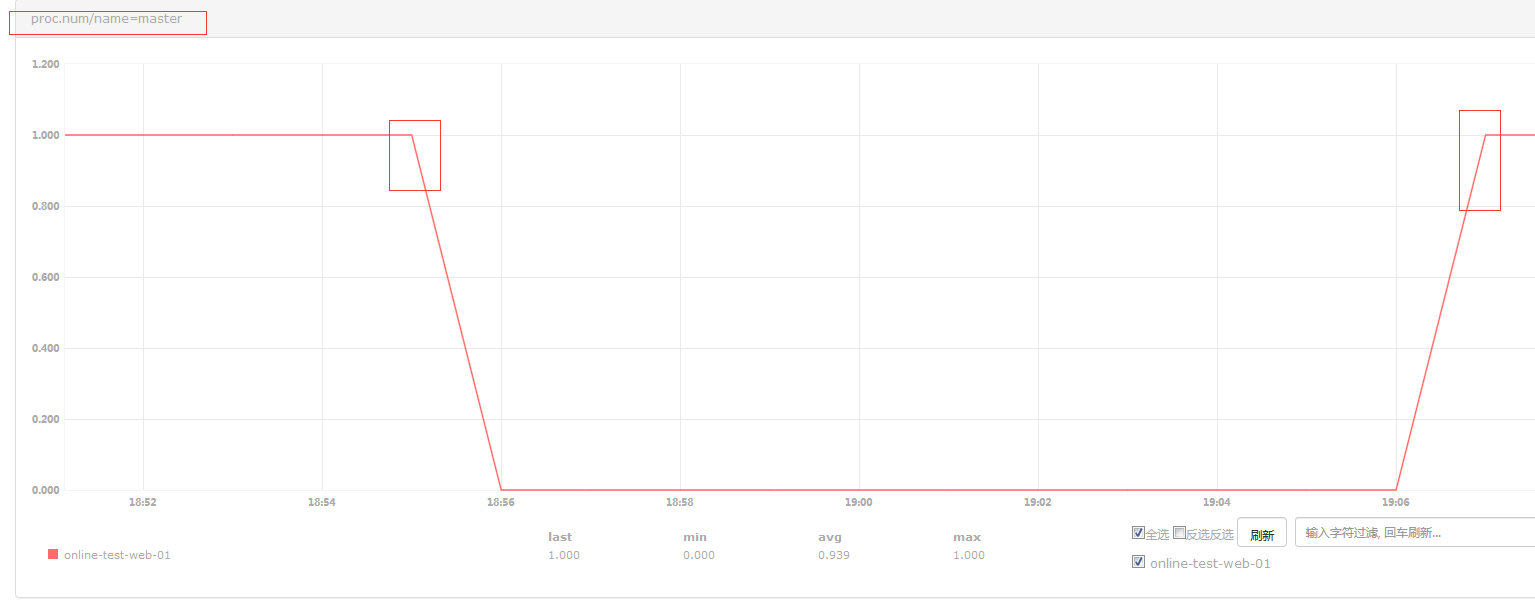
停掉postfix进程检查一下:
二、自定义Push数据
不仅仅是falcon-agent采集的数据可以push到监控系统,一些场景下,我们自定义的一些数据指标,也可以push到open-falcon中,比如:线上某服务的、qps某业务的在线人数、某个接⼝的响应时间、某个页面的状态码(500、200)、某个接口的请求出错次数......
2.1 官网例子:
# cat 1.sh
#!/bin/bash
ts=`date +%s`;
curl -X POST -d "[{\"metric\": \"test-metric\", \"endpoint\": \"test-endpoint\", \"timestamp\": $ts,\"step\": 60,\"value\": 1,\"counterType\": \"GAUGE\",\"tags\": \"idc=lg,project=xx\"}]" http://127.0.0.1:1988/v1/push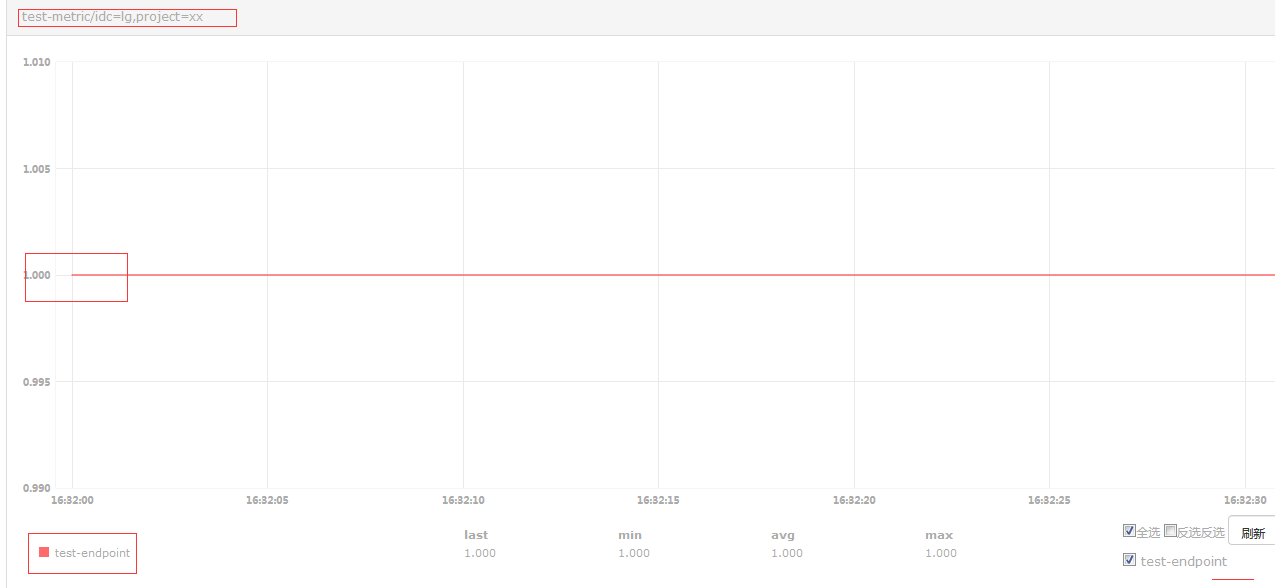
# pip install requests
# cat 1.py
#!-*- coding:utf8 -*-
import requests
import time
import json
ts = int(time.time())
payload = [
{
"endpoint": "test-endpoint",
"metric": "test-metric",
"timestamp": ts,
"step": 60,
"value": 1,
"counterType": "GAUGE",
"tags": "idc=lg,loc=beijing",
},
{
"endpoint": "test-endpoint",
"metric": "test-metric2",
"timestamp": ts,
"step": 60,
"value": 2,
"counterType": "GAUGE",
"tags": "idc=lg,loc=beijing",
},
]
r = requests.post("http://127.0.0.1:1988/v1/push", data=json.dumps(payload))
print r.text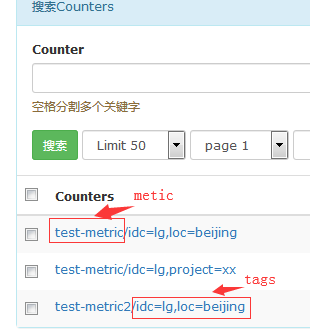
博文来自:www.51niux.com
2.2 mtail监控nginx日志进行状态报警
#mtail是谷歌的一个工具用来监控日志,然后可以根据我们配置的正则去进行日志过滤,但是有个问题就是日志量很大的时候CPU占用的也高。
配置使用文档:https://github.com/google/mtail/blob/master/docs/Programming-Guide.md
mtail的安装:
#cd /usr/lib/golang/src/golang.org/x #提前将需要的依赖包先下载下来,不然网站是国外的你懂的,当然也可以需要什么go get github.com/go-sql-driver/mysql #这样安装#git clone https://github.com/golang/net.git
#git clone https://github.com/golang/sys.git
#git clone https://github.com/golang/tools.git
#git clone https://github.com/golang/text.git
#cd $GOPATH/src
#go get github.com/google/mtail
#cd github.com/google/mtail
#make #出现下面表示编译成功了
go install -ldflags "-X main.Version=v3.0.0-rc17-11-gb2b6615 -X main.Revision=b2b661589536f525954bbe8edf0982c4ef9b8e7f"
# find / -name "mtail" #如果不知道mtail命令编译到哪去了可以通过这样查找一下
#mkdir /home/work/mtail
# cp /opt/bin/mtail /home/work/mtail/
# ./mtail -h
-address string #绑定HTTP侦听器的主机或IP地址 -alsologtostderr #记录标准错误以及文件 -block_profile_rate int #报告goroutine阻塞事件之前的纳秒时间。 0关闭。 -collectd_prefix string #用于收集指标的前缀。 -collectd_socketpath string # 收集unixsock以编写指标的路径 -compile_only #仅编译程序,不加载虚拟机。 -dump_ast #解析后转储程序的AST(到INFO日志)。 -dump_ast_types #在typecheck之后转储具有类型注释的程序的AST(到INFO日志)。 -dump_bytecode #转储程序的字节码(到INFO日志)。 -emit_prog_label #在变量导出中发出'prog'标签。(默认为true) -graphite_host_port string #主机:端口到graphite carbon 服务器写指标。 -graphite_prefix string #用于graphite carbon指标的前缀。 -log_backtrace_at value #当记录命中行文件时:N,发出堆栈跟踪 -log_dir string # 如果非空,则在此目录中写入日志文件 -logs value #要监视的日志文件列表,以逗号分隔。可以多次指定该标志。 -logtostderr #记录标准错误而不是文件 -metric_push_interval_seconds int #度量推送之间的间隔,以秒为单位。 (默认60) -metric_push_write_deadline duration #在退出错误之前等待推送成功的时间。 (默认10秒) -mtailDebug int #设置解析器调试级别。 -mutex_profile_fraction int #报告了互斥争用事件的一部分。 0关闭。 -one_shot #编译程序,然后从开始直到EOF读取提供的日志的内容,打印度量存储的值并退出。这只是一个调试标志,不适用于生产用途。 -one_shot_metrics #DEPRECATED:一次性模式后转储指标(到标准输出)。 -override_timezone string #如果设置,请在时间戳转换中使用提供的时区,而不是UTC。 -poll_interval duration #设置间隔以轮询所有日志文件以获取数据;必须为正,否则为零以禁用轮询。 -port string #要侦听的HTTP端口。 (默认“3903”) -progs string #包含mtail程序的目录的名称 -statsd_hostport string # 主机:端口到statsd服务器以写入指标。 -statsd_prefix string #用于statsd指标的前缀。 -stderrthreshold value #等于或高于此阈值的日志转到stderr -syslog_use_current_year #修补与今年无关的时间戳。 (默认为true) -v value #v 日志的日志级别 -version #打印mtail版本信息。 -vmodule value #逗号分隔的模式列表=文件筛选日志记录的N设置
#如果.mtail文件不知道怎么写的话,mtail-3.0.0-rc16/examples下面有很多例子。
mtail简单使用展示:
# cat /home/work/scripts/mtail_start.sh
#!/bin/bash /home/work/mtail/mtail -logs /usr/local/nginx/logs/access.log -progs /home/work/mtail/http_mprog/nginx_status.mtail -address 127.0.0.1 -metric_push_interval_seconds 60 >>/home/work/mtail/logs.log &
#-address 127.0.0.1可以先不加这句话,这里有个3903端口,你可以通过web页面查看都有哪些展示。我现在写这个脚本的意义就是让mtail监控程序实时的查看nginx的日志。
# sh /home/work/scripts/mtail_start.sh #好了让mtail程序跑起来
# netstat -lntup|grep 3903
tcp 0 0 127.0.0.1:3903 0.0.0.0:* LISTEN 31380/mtail
# cat /home/work/mtail/http_mprog/nginx_status.mtail
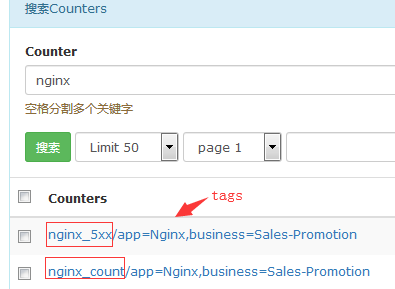
counter nginx_5xx #这里首先定义了两个变量一个nginx_5xx一个nginx_count
counter nginx_count
/$/{ #这里是匹配所有
nginx_count++ #只要有一条日志插入nginx_count就会有一条计数认为nginx的日志又增加了一行,但是重新的话是从最新的日志行开始计数这个要记住哦
/HTTP\/1\.1\" 50[0-9]/ { #这里//里面是一个正则,如果匹配到我们写的一个正则
nginx_5xx++ #nginx_5xx++就增加一个计数
}
}# cat /home/work/scripts/push.py #这是一个简单的python脚本,很简单只是为了表示一个意思,我就不多做介绍了
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import time
import json
import re
import os
def write_file(file_name,input_value):
with open(file_name, 'w') as f:
input_value = str(input_value)
f.write(input_value)
def read_file(file_name):
file = open(file_name,'r')
out_value = file.readline()
return out_value
ts = int(time.time())
res = requests.get("http://127.0.0.1:3903/json")
res = res.json()
for i in range(0,len(res)):
metric = res[i]['Name']
now_value = res[i]['LabelValues'][0]['Value']['Value']
if os.path.exists(metric):
out_value=read_file(metric)
value = now_value-int(out_value)
else:
value=now_value
payload = [
{
"endpoint": "online-test-web-01",
"metric": metric,
"timestamp": ts,
"step": 60,
"value": value,
"counterType": "GAUGE",
"tags": "app=Nginx,business=Sales-Promotion",
},
]
r = requests.post("http://127.0.0.1:1988/v1/push", data=json.dumps(payload))
print r.text
if value != 0:
write_file(metric,now_value)# for num in `seq 1 10000`;do python /home/work/scripts/push.py ;done #可以先打点数据到服务端。
# echo "192.168.1.152 - - [13/Nov/2018:20:03:54 +0800] HEAD HTTP/1.1\" 500 0 - curl/7.29.0" >>/usr/local/nginx/logs/access.log #打五条测试数据,记得时间戳那里一定是当前时间的哦,不然是不会记录的
# echo "192.168.1.152 - - [13/Nov/2018:20:03:54 +0800] HEAD HTTP/1.1\" 501 0 - curl/7.29.0" >>/usr/local/nginx/logs/access.log
# echo "192.168.1.152 - - [13/Nov/2018:20:03:54 +0800] HEAD HTTP/1.1\" 502 0 - curl/7.29.0" >>/usr/local/nginx/logs/access.log
# echo "192.168.1.152 - - [13/Nov/2018:20:03:54 +0800] HEAD HTTP/1.1\" 200 0 - curl/7.29.0" >>/usr/local/nginx/logs/access.log
# echo "192.168.1.152 - - [13/Nov/2018:20:03:54 +0800] HEAD HTTP/1.1\" 200 0 - curl/7.29.0" >>/usr/local/nginx/logs/access.log
# curl 127.0.0.1:3903/json #可以看一下数值,可以看到nginx_count代表总日志条数是5条,然后nginx_5xx代表错误的日志条数是3条
[
{
"Name": "nginx_5xx",
"Program": "nginx_status.mtail",
"Kind": 1,
"Type": 0,
"LabelValues": [
{
"Value": {
"Value": 3,
"Time": 1542024197825958304
}
}
]
},
{
"Name": "nginx_count",
"Program": "nginx_status.mtail",
"Kind": 1,
"Type": 0,
"LabelValues": [
{
"Value": {
"Value": 5,
"Time": 1542024204354071591
}
}
]
}
]# crontab -l #先简单的写个定时任务保证数据不断层
*/1 * * * * cd /home/work/scripts && /usr/bin/python /home/work/scripts/push.py
配置策略表达式:
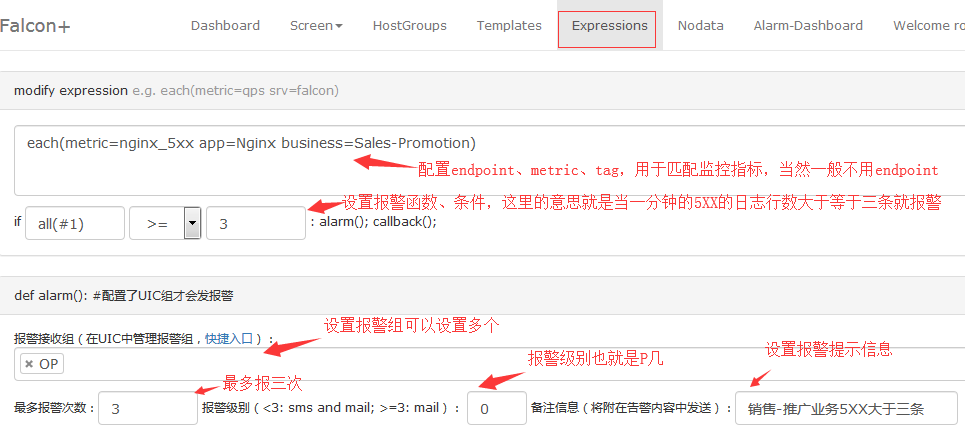
#expression无需绑定到HostGroup。
#然后就是用我上面的echo 信息到nginx的日志里面去进行测试。
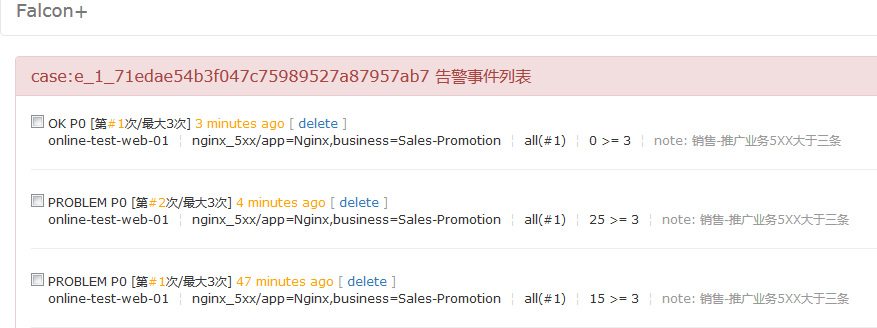
#通过报警事件可以看到对Nginx的5XX错误已经可以实现报警提醒效果了。当然这只是一个简单的例子。
