大数据(十四)flume实例部署
#我擦前面又把官网翻译了一遍,现在写一些例子把前面的知识捋一下,虽然前面又好多的source、channel、sink,但是实际用到的也不多。
一、简单本机示例
1.1 使用memory做channel、exec做source、file_roll做sink
设置一个测试.conf:
$ vim /home/flume/flume/conf/exec_test1.conf
a1.sources = source1 #定义sources源的名称是source1 a1.channels = channel1 #定义channels通道的名称是channel1 a1.sinks = sink1 #定义存储介质的名称是sink1 #Define a memory channel called channel1 on a1 a1.channels.channel1.type = memory #定义通道类型数memory内存通道 a1.channels.channel1.capacity = 1000000 #存储在通道中的事件的最大数量1000000 a1.channels.channel1.transactionCapacity = 100000 #每次最大从source拿到或者送到sink中的event数量是100000 a1.channels.channel1.keep-alive = 30 # 以秒为单位添加或删除事件的超时时间这里是30秒,默认是超时3秒。 # Define an Exec source called source1 on a1 and tell it a1.sources.source1.channels = channel1 #指定source1通过channel1通道发送数据 a1.sources.source1.type = exec #source1的类型是exec a1.sources.source1.command = tail -F /usr/local/nginx/logs/access.log #source1源要执行什么命令来收集event信息 a1.sources.source1.batchSize = 10000 #一次读取和发送到channel1中的最大行数是10000 #Define an File Roll Sink called sink1 on a1 a1.sinks.sink1.type = file_roll #指定sink1的类型是file_roll也就是存放到一个目录下面 a1.sinks.sink1.channel = channel1 #指定sink1从channel1接收源信息 a1.sinks.sink1.sink.directory = /tmp/test/ #指定sink1收到源发来的信息之后存储到哪个目录下面
启动服务:
$ flume-ng agent -n a1 -c conf -f conf/exec_test1.conf -Dflume.root.logger=INFO,console #启动服务
# cat xaa >>/usr/local/nginx/logs/access.log #搞了一个1G的测试文件往access.log日志里面灌
正常测试观察:
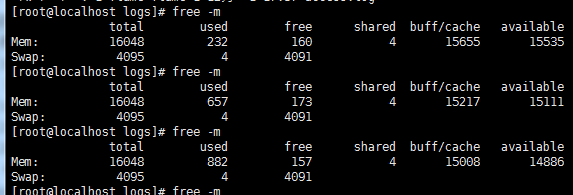
#首先看到内存是增加使用量是一个增加的过程,因为使用的是内存通道。

#1G的日志很快传输完了,可以看见传输到sink指定目录下的日志文件是以时间戳的形式生成的。
异常测试观察:
观察1,好的假设我们flume程序死了,又手工拉起来了。也就是flume程序重启了。
# ls -lh /tmp/test/
总用量 1001M -rw-rw-r--. 1 flume flume 643M 12月 1 18:02 1512122502948-1 -rw-rw-r--. 1 flume flume 358M 12月 1 18:02 1512122502948-2 -rw-rw-r--. 1 flume flume 0 12月 1 18:02 1512122502948-3 -rw-rw-r--. 1 flume flume 51 12月 1 18:03 1512122502948-4 -rw-rw-r--. 1 flume flume 2.0K 12月 1 18:04 1512122624329-1 #这是执行重启之后产生的一个文件 -rw-rw-r--. 1 flume flume 0 12月 1 18:04 1512122624329-2 -rw-rw-r--. 1 flume flume 0 12月 1 18:04 1512122624329-3 -rw-rw-r--. 1 flume flume 0 12月 1 18:05 1512122624329-4 -rw-rw-r--. 1 flume flume 0 12月 1 18:05 1512122624329-5 -rw-rw-r--. 1 flume flume 0 12月 1 18:06 1512122624329-6
#当然可以看到下面就算没有日志写入也会每分钟产生一份新的空文件。
观察2,将源文件搞走再搞回来。

#迅速的搞走再搞回来。
# ls -lh /tmp/test/
-rw-rw-r--. 1 flume flume 324M 12月 1 18:11 1512122624329-15 -rw-rw-r--. 1 flume flume 677M 12月 1 18:12 1512122624329-16
#这倒没什么影响,因为log轮询的话再产生的肯定是新的空的日志文件等待着再写入。
观察3,在flume服务启动的过程中将source源文件搞走flume程序会死吗?
#经过观察是不会死的。
观察4,如果源文件不存在flume程序启动会怎么样?
#经过观察也是flume程序也是不会死的,再启动flume的时候源文件不存在的话flume程序也是不会死的。
博文来自:www.51niux.com
1.2 使用memory做channel、exec做source、hdfs做sink
#自己采自己的日志然后存本地目录没啥意思哈,那咱们实时的采集日志信息往hdfs上面存。
设置一个测试conf:
# vim /home/flume/flume/conf/exec_hdfs1.conf
a1.sources = source1 a1.channels = channel1 a1.sinks = sink1 #Define a memory channel called channel1 on a1 a1.channels.channel1.type = memory a1.channels.channel1.capacity = 1000000 a1.channels.channel1.transactionCapacity = 100000 a1.channels.channel1.keep-alive = 30 # Define an Exec source called source1 on a1 and tell it a1.sources.source1.channels = channel1 a1.sources.source1.type = exec a1.sources.source1.command = tail -F /usr/local/nginx/logs/access.log a1.sources.source1.batchSize = 10000 #Define an File Roll Sink called sink1 on a1 a1.sinks.sink1.channel = channel1 a1.sinks.sink1.type = hdfs a1.sinks.sink1.hdfs.path = hdfs://192.168.14.50:8020/flumetest/
将hadoop源码包放到flume客户端本地并且设置环境变量:
# cat /etc/profile
#############hadoop########################################## export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/sbin/:$HADOOP_HOME/bin/ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/hadoop/hadoop/lzo/:$LD_LIBRARY_PATH:/home/hadoop/hadoop/lib/native/
#不把hadoop源码包解压放到flume客户端的话,因为它要使用hadoop里面的jar包命令什么的,会在启动的时候报下面的错误:
2017-12-01 19:12:07,881 (conf-file-poller-0) [ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:146)] Failed to start agent because dependencies were not found in classpath. Error follows. java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType at org.apache.flume.sink.hdfs.HDFSEventSink.configure(HDFSEventSink.java:235) at org.apache.flume.conf.Configurables.configure(Configurables.java:41) at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:411) at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:102) at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:141) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.io.SequenceFile$CompressionType at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
$ source /etc/profile
hadoop节点上面创建目录并授权
[hadoop@master ~]$ hadoop fs -mkdir hdfs://192.168.14.50:8020/flumetest/
[hadoop@master ~]$ hadoop fs -chown flume:flume hdfs://192.168.14.50:8020/flumetest/
#你不授权的话,因为客户端用的是flume用户,在发送日志的时候会报下面的错:
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=flume, access=WRITE, inode="/flumetest":hadoop:supergroup:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:317) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:223) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:199) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1752) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1736)
客户端启动服务并观察:
[flume@localhost flume]$ flume-ng agent -n a1 -c conf -f conf/exec_hdfs1.conf -Dflume.root.logger=INFO,console #直接看最底部的信息啊看到在往hdfs里面传数据了,然后传完一个会有重命名操作,将.tmp的后缀去掉
2017-12-01 19:23:25,563 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.ExecSource.start(ExecSource.java:168)] Exec source starting with command: tail -F /usr/local/nginx/logs/access.log 2017-12-01 19:23:25,564 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: source1: Successfully registered new MBean. 2017-12-01 19:23:25,564 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: source1 started 2017-12-01 19:23:28,646 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSSequenceFile.configure(HDFSSequenceFile.java:63)] writeFormat = Writable, UseRawLocalFileSystem = false 2017-12-01 19:23:29,013 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//FlumeData.1512127408642.tmp 2017-12-01 19:23:31,637 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:393)] Closing hdfs://192.168.14.50:8020/flumetest//FlumeData.1512127408642.tmp 2017-12-01 19:23:31,733 (hdfs-sink1-call-runner-8) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:655)] Renaming hdfs://192.168.14.50:8020/flumetest/FlumeData.1512127408642.tmp to hdfs://192.168.14.50:8020/flumetest/FlumeData.1512127408642 2017-12-01 19:23:31,829 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//FlumeData.1512127408643.tmp ...... 2017-12-01 19:24:02,183 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.HDFSEventSink$1.run(HDFSEventSink.java:382)] Writer callback called. #如果这个文件写完了最后是这个格式
hdfs上面的查看:

#可以看到如果是正在写入的前缀是FlumeData中间是时间戳后面是.tmp,如果已经写完了呢也就是文件关闭已经不再写入呢就变成了FlumeData.时间戳的形式。
将sink多设置一点:
# vim /home/flume/flume/conf/exec_hdfs1.conf
a1.sources = source1 a1.channels = channel1 a1.sinks = sink1 #Define a memory channel called channel1 on a1 a1.channels.channel1.type = memory a1.channels.channel1.capacity = 1000000 a1.channels.channel1.transactionCapacity = 100000 a1.channels.channel1.keep-alive = 30 # Define an Exec source called source1 on a1 and tell it a1.sources.source1.channels = channel1 a1.sources.source1.type = exec a1.sources.source1.command = tail -F /usr/local/nginx/logs/access.log a1.sources.source1.batchSize = 10000 #Define an File Roll Sink called sink1 on a1 a1.sinks.sink1.channel = channel1 a1.sinks.sink1.type = hdfs #sink类型是hdfs a1.sinks.sink1.hdfs.path = hdfs://192.168.14.50:8020/flumetest/ #sink接收到源数据后写到哪个目录下面 a1.sinks.sink1.hdfs.writeFormat = Text #记录类型为Text类型 a1.sinks.sink1.hdfs.fileType = DataStream #文件格式是数据流的形式 a1.sinks.sink1.hdfs.fileSuffix = .log #写入hdfs里面的文件后缀 a1.sinks.sink1.hdfs.filePrefix = %[IP] #写入hdfs里面的文件前缀 a1.sinks.sink1.hdfs.idleTimeout = 0 #禁止自动关闭空闲文件 a1.sinks.sink1.hdfs.rollInterval = 60 #多少秒产生一个新的文件,这里是60秒产生一个新的文件 #a1.sinks.sink1.hdfs.rollSize = 209715200 #这里是按照文件的大小轮询,当存入到hdfs里面的日志多大之后产生一个新的文件,这里是200M产生一个新的文件,但是这里我测试了。 a1.sinks.sink1.hdfs.rollSize = 0 #rollSize设置为0表示不会根据文件大小滚动切割 a1.sinks.sink1.hdfs.rollCount = 0 #根据写入文件的event数量来滚动,0就是不根据这个滚动。 a1.sinks.sink1.hdfs.round = true #这里我们让时间戳四舍五入 a1.sinks.sink1.hdfs.roundUint = minute #四舍五入的单位是分钟 a1.sinks.sink1.hdfs.minBlockReplicas = 1 # 指定每个HDFS块的最小数量的副本。 如果未指定,则它来自类路径中的默认Hadoop配置。 a1.sinks.sink1.hdfs.batchSize = 1000 #在刷新到HDFS之前写入文件的事件数量 a1.sinks.sink1.hdfs.callTimeout = 120000 # HDFS操作允许的毫秒数,例如打开,写入,刷新,关闭。 如果发生许多HDFS超时操作,则应该增加此数字。这里把这个时间增加了120000毫秒也就是120秒 a1.sinks.sink1.hdfs.useLocalTimeStamp = true #使用hdfs自己的本地时间而不是来自于event头里的时间戳
重启flume并检测:
[flume@localhost flume]$ flume-ng agent -n a1 -c conf -f conf/exec_hdfs1.conf -Dflume.root.logger=INFO,console
2017-12-01 20:08:02,857 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:171)] Starting Sink sink1 2017-12-01 20:08:02,857 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:182)] Starting Source source1 2017-12-01 20:08:02,858 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.ExecSource.start(ExecSource.java:168)] Exec source starting with command: tail -F /usr/local/nginx/logs/access.log 2017-12-01 20:08:02,859 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: source1: Successfully registered new MBean. 2017-12-01 20:08:02,859 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: source1 started 2017-12-01 20:08:02,860 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SINK, name: sink1: Successfully registered new MBean. 2017-12-01 20:08:02,860 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SINK, name: sink1 started 2017-12-01 20:08:05,992 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-01 20:08:06,356 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//127.0.0.1.1512130085993.log.tmp 2017-12-01 20:09:08,452 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:393)] Closing hdfs://192.168.14.50:8020/flumetest//127.0.0.1.1512130085993.log.tmp 2017-12-01 20:09:08,537 (hdfs-sink1-call-runner-2) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:655)] Renaming hdfs://192.168.14.50:8020/flumetest/127.0.0.1.1512130085993.log.tmp to hdfs://192.168.14.50:8020/flumetest/127.0.0.1.1512130085993.log 2017-12-01 20:09:08,582 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.HDFSEventSink$1.run(HDFSEventSink.java:382)] Writer callback called.

#可以看到啥玩意也没有写入,跟file_roll那种不一样,flume启动之前的日志不读取。
往旧的日志里面新加内容试试?
# cat /opt/lzotest1.log >>/usr/local/nginx/logs/access.log 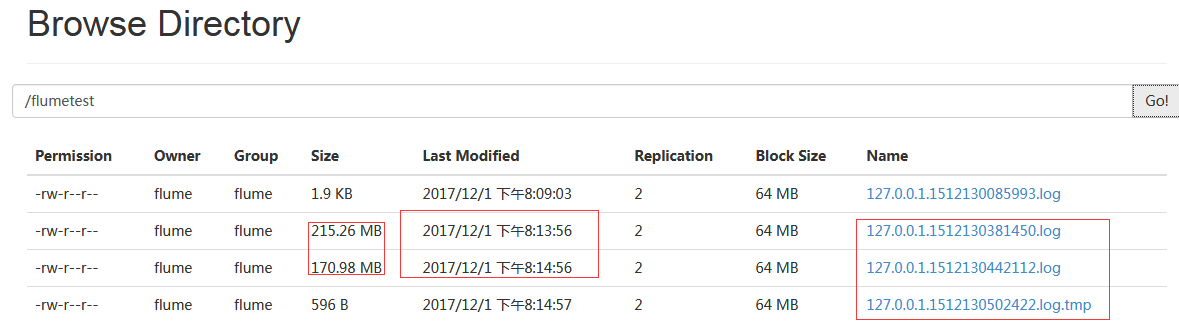
#从截图可以看出一分钟切割一个日志,并非按照大小进行切割,然后产生的日志前缀是127.0.0.1后缀是.log,临时文件当然还是.tmp后缀标识。
再做个蛋疼的测试:
[flume@localhost flume]$ ls -lh /usr/local/nginx/logs/access.log #我又向这个日志里面写了19G的日志
-rw-r--r--. 1 flume flume 20G 12月 1 20:15 /usr/local/nginx/logs/access.log
#然后我把flume关闭了然后再启动。
2017-12-01 20:21:54,492 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-01 20:21:54,862 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//127.0.0.1.1512130914493.log.tmp 2017-12-01 20:22:57,075 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:393)] Closing hdfs://192.168.14.50:8020/flumetest//127.0.0.1.1512130914493.log.tmp 2017-12-01 20:22:57,287 (hdfs-sink1-call-runner-2) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:655)] Renaming hdfs://192.168.14.50:8020/flumetest/127.0.0.1.1512130914493.log.tmp to hdfs://192.168.14.50:8020/flumetest/127.0.0.1.1512130914493.log 2017-12-01 20:22:57,339 (hdfs-sink1-roll-timer-0) [INFO - org.apache.flume.sink.hdfs.HDFSEventSink$1.run(HDFSEventSink.java:382)] Writer callback called.
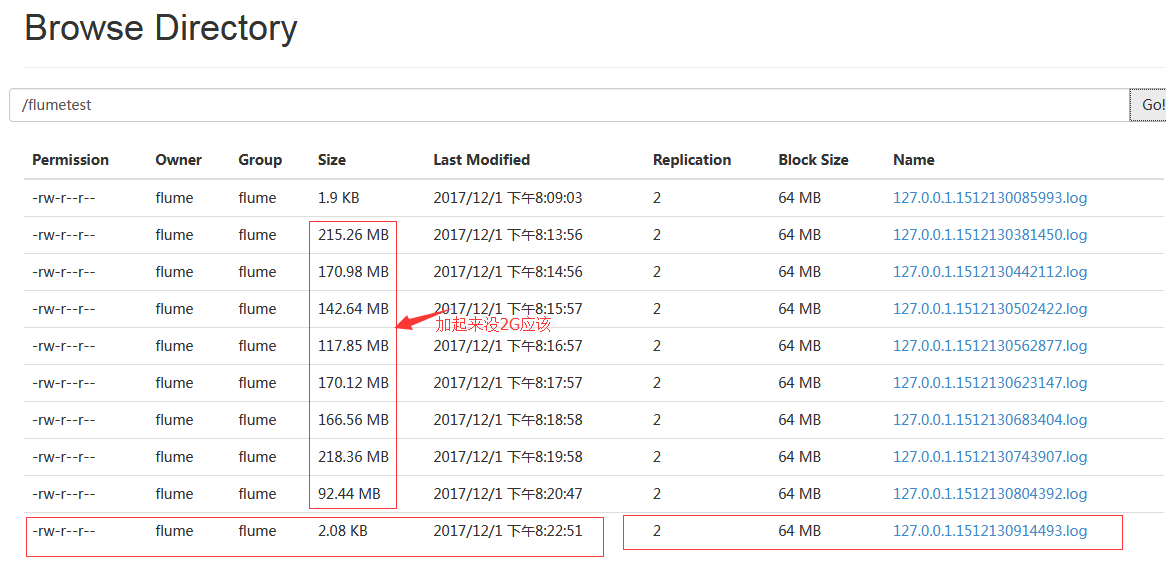
#测试发现一个蛋疼的问题,很重要:
官网也说了,你如果用内存通道的话,数据容易丢失(Memory Channel 是一个内存缓冲区,因此如果Java 虚拟机(JVM)或机器重新启动,任何缓冲区中的数据将丢失)。这就是活生生的例子,那么多日志写入,程序由于某种原因死了,你再把程序启动以来,哪些未发送的event事件不发送了,那你如果是实时事件的话,数据就丢了。
博文来自:www.51niux.com
1.3 使用 Taildir Source
#承接上面的例子,上面用的是exec源,只能对单个文件进行tail,无法监控多个文件的实时写入。这个组件是1.7版本新推出的,在早期研究1.5后来线上用的1.6都没接触到这个组件,所以这里也写不出多好的例子,只能照着官网改吧改吧。
还是先配置一个测试conf:
$ vim /home/flume/flume/conf/tail_hdfs1.conf
a1.sources = source1 a1.channels = channel1 a1.sinks = sink1 #Define a memory channel called channel1 on a1 a1.channels.channel1.type = memory a1.channels.channel1.capacity = 1000000 a1.channels.channel1.transactionCapacity = 100000 a1.channels.channel1.keep-alive = 30 # Define an Exec source called source1 on a1 and tell it a1.sources.source1.channels = channel1 a1.sources.source1.type = TAILDIR #还是选择组件类型为TAILDIR a1.sources.source1.positionFile = /home/flume/tail/taildir_position.json #这里有个坑,就是/home/flume/tail这个在第一次创建的时候这个tail目录一定不要存在,不然你启动的时候会有报错。 a1.sources.source1.filegroups = f1 f2 #定义了两个文件监控组,f1 f2,多组之间用空格隔开 a1.sources.source1.filegroups.f1 = /usr/local/nginx/logs/access.log #指定第一个监控组f1监控的文件,这里定义了一个绝对路径的文件 a1.sources.source1.headers.f1.headerKey1 = value1 #定义了f1组的标题值是value1 a1.sources.source1.filegroups.f2 = /opt/test2/test.*.log #定义了第二个监控组f2,所监控的文件时一个目录下面正则表达式以test开头以.log结尾的log日志文件 a1.sources.source1.headers.f2.headerKey1 = access a1.sources.source1.headers.f2.headerKey2 = test #标题值可以有多个,这里给f2监控组定义了两个标题值 a1.sources.source1.fileHeader = true #Define an File Roll Sink called sink1 on a1 a1.sinks.sink1.channel = channel1 a1.sinks.sink1.type = hdfs a1.sinks.sink1.hdfs.path = hdfs://192.168.14.50:8020/flumetest/ a1.sinks.sink1.hdfs.writeFormat = Text a1.sinks.sink1.hdfs.fileType = DataStream a1.sinks.sink1.hdfs.fileSuffix = .log a1.sinks.sink1.hdfs.filePrefix = web a1.sinks.sink1.hdfs.idleTimeout = 0 a1.sinks.sink1.hdfs.rollInterval = 60 #a1.sinks.sink1.hdfs.rollSize = 209715200 a1.sinks.sink1.hdfs.rollSize = 0 a1.sinks.sink1.hdfs.rollCount = 0 a1.sinks.sink1.hdfs.round = true a1.sinks.sink1.hdfs.roundUint = minute a1.sinks.sink1.hdfs.minBlockReplicas = 1 a1.sinks.sink1.hdfs.batchSize = 1000 a1.sinks.sink1.hdfs.callTimeout = 120000 a1.sinks.sink1.hdfs.useLocalTimeStamp = true
启动测试一下:
$ flume-ng agent -n a1 -c conf -f conf/tail_hdfs1.conf -Dflume.root.logger=INFO,console
2017-12-02 11:21:36,804 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.taildir.TaildirSource.start(TaildirSource.java:92)] source1 TaildirSource source starting with directory: {f1=/usr/local/nginx/logs/access.log, f2=/opt/test2/test.*.log}
2017-12-02 11:21:36,805 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SINK, name: sink1: Successfully registered new MBean.
2017-12-02 11:21:36,805 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SINK, name: sink1 started
2017-12-02 11:21:36,813 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.taildir.ReliableTaildirEventReader.<init>(ReliableTaildirEventReader.java:83)] taildirCache: [{filegroup='f1', filePattern='/usr/local/nginx/logs/access.log', cached=true}, {filegroup='f2', filePattern='/opt/test2/test.*.log', cached=true}]
2017-12-02 11:21:36,824 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.taildir.ReliableTaildirEventReader.<init>(ReliableTaildirEventReader.java:84)] headerTable: {f1={headerKey1=value1}, f2={headerKey1=access, headerKey2=test}}#从上面截取的部分输出信息可以看到,监控的日志也都监控上了,日志信息的传输是从最开始开始的,因为有一个/home/flume/tail/taildir_position.json计算偏移量嘛。
# cat /home/flume/tail/taildir_position.json #可以看到下面信息是inode号,偏移量(数据传输过程中是一直增大的),监控的文件名称
[{"inode":4591620,"pos":1048576000,"file":"/usr/local/nginx/logs/access.log"},
{"inode":2490370,"pos":1048575950,"file":"/opt/test2/test1.log"},
{"inode":2490371,"pos":1048575950,"file":"/opt/test2/test2.log"}]反复重启测试:
反复重启flume也会看到日志不像上面tail那种形式不会再传输日志信息了,这里还是会继续传输日志信息的,因为记录了传输日志的偏移量。而且可以看到可以监控多个文件,而且对于文件来说还支持正则表达式的方式。

#从hdfs的结果看,可以看到我中间改了三次配置文件然后重启flume,都不会上面exec那个例子一样就不会再发送剩下的日志信息了,因为是根据偏移量来发送信息的。
注意:a1.sources.source1.positionFile这里定义的最终的json文件的上一级目录一定不要事先存在,不然启动flume会有以下报错:
2017-12-02 11:36:55,446 (conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSources(AbstractConfigurationProvider.java:361)] Source source1 has been removed due to an error during configuration org.apache.flume.FlumeException: Error creating positionFile parent directories at org.apache.flume.source.taildir.TaildirSource.configure(TaildirSource.java:168) at org.apache.flume.conf.Configurables.configure(Configurables.java:41) at org.apache.flume.node.AbstractConfigurationProvider.loadSources(AbstractConfigurationProvider.java:326) at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:101) at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:141)
1.4 使用netcat做source源做个简单测试
还是先配置一个测试conf文件
$ cat /home/flume/flume/conf/netcat_hdfs1.conf
collect.sources = websrc collect.channels = wchannel collect.sinks = hdfssink # For each one of the sources, the type is defined collect.sources.websrc.type = netcat #指定websrc源的组件类似是netcat collect.sources.websrc.bind = localhost #这是监听在本地 collect.sources.websrc.port = 44444 #监听端口是44444 collect.sources.websrc.interceptors=itimestamp #定义了一个拦截器,拦截器的名称叫做itimestamp collect.sources.websrc.interceptors.itimestamp.type=timestamp #拦截器itimestamp的类型是拦截时间戳 # Each sink's type must be defined collect.sinks.hdfssink.type = hdfs collect.sinks.hdfssink.hdfs.path = hdfs://192.168.14.50:8020/flumetest collect.sinks.hdfssink.hdfs.writeFormat = Text collect.sinks.hdfssink.hdfs.fileType = DataStream #collect.sinks.hdfssink.hdfs.idleTimeout = 120 #这里应该开启的,为了测试下面的效果这里就先注释掉了,这句话在这里很有用。 collect.sinks.hdfssink.hdfs.filePrefix = nginx-%Y-%m-%d-%H #这里要注意如果上面websrc不定义时间戳的拦截器,这里是不用引用时间变量的。 collect.sinks.hdfssink.hdfs.rollInterval = 0 collect.sinks.hdfssink.hdfs.rollSize = 1000000 collect.sinks.hdfssink.hdfs.rollCount = 0 collect.sinks.hdfssink.hdfs.batchSize = 1000 collect.sinks.hdfssink.hdfs.callTimeout = 60000 # Each channel's type is defined. collect.channels.wchannel.type = memory agent.channels.wchannel.capacity = 100 collect.sources.websrc.channels = wchannel collect.sinks.hdfssink.channel = wchannel
注意:如上不定义时间戳的拦截器就让sink里面的前缀或者后缀的地方引用%Y之类的时间变量的话,在启动服务得时候会有下面的报错:
2017-12-02 17:18:02,413 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 2017-12-02 17:18:11,417 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:447)] process failed java.lang.NullPointerException: Expected timestamp in the Flume event headers, but it was null at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:204) at org.apache.flume.formatter.output.BucketPath.replaceShorthand(BucketPath.java:251) at org.apache.flume.formatter.output.BucketPath.escapeString(BucketPath.java:460) at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:370) at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67) at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145) at java.lang.Thread.run(Thread.java:745)
启动服务查看一下:
$ flume-ng agent -n collect -c conf -f conf/netcat_hdfs1.conf -Dflume.root.logger=INFO,console
2017-12-02 17:26:19,874 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SINK, name: hdfssink started 2017-12-02 17:26:19,880 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] 2017-12-02 17:32:25,921 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-02 17:32:26,277 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//nginx-2017-12-02-17-32.1512207145921.tmp 2017-12-02 17:33:01,836 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-02 17:33:01,884 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//nginx-2017-12-02-17-33.1512207181837.tmp 2017-12-02 17:34:13,079 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-02 17:34:13,122 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest//nginx-2017-12-02-17-34.1512207253080.tmp

#从hdfs上面可以看出,产生的文件时以我们定义的时间变量为前缀,因为你产生的日志名称走的时间变量的形式,如果日志的体积大小达不到我们上面设置的切割标准(也就相当于达不到标准它这个按大小切割就不生效),然后可以看到hdfs里面文件的创建时间是按照event时间插入的时间来的,然后就是关于.tmp临时文件,你看我截图前三个最后时间一样,是因为我把flume关闭了,如果不关闭的话,就算已经不写这个.tmp文件了,还还是未关闭状态,也就是还是.tmp临时文件的状态,只有手工关闭flume程序(或者在conf文件里面定义idleTimeout 这个参数,上面conf文件注释掉了),才会从临时文件状态退出来。当然是否等待一很长段时间就不是tmp文件了,我觉得不会因为就走默认0超时之后禁止关闭非活动文件了,这个我没测试。
二、使用spooldir
简单来说这种方式就是监控一个目录,如果这个目录里面出现了符合标准的文件就会触发发送。这种方式比较适合采集离线数据。
博文来自:www.51niux.com
2.1 先来个简单的示例
配置文件的编写:
# vim /home/flume/flume/conf/spooldir_hdfs1.conf
#list sources,channels,sinks a2.sources = spooldir1 a2.channels = channel1 a2.sinks = hdfssink1 #defined sources a2.sources.spooldir1.type = spoolDir #定义了source的类型是spooldir a2.sources.spooldir1.channels = channel1 a2.sources.spooldir1.spoolDir = /tmp/logs #读取文件的目录是/tmp/logs,这个目录要提前存在不然启动报错 a2.sources.spooldir1.batchSize = 100 a2.sources.spooldir1.fileSuffix = .comp #读完的文件给个后缀表示已经读取完毕了就不用在采集此文件的数据了,默认文件后缀会给个.COMPLETED a2.sources.spooldir1.deletePolicy = never #读完文件要不要删除,never是不删除默认也是不删除 a2.sources.spooldir1.ignorePattern = ^$ #这是忽略什么文件,默认就是^$ a2.sources.spooldir1.consumeOrder = oldest #默认也是oldtest模式,就是目录里面有新文件和旧文件,先发送时间戳较旧的文件再发送后面的。 a2.sources.spooldir1.batchSize = 9999 #批量发送到通道的事件数量 #defined channel a2.channels.channel1.type = memory a2.channels.channel1.capacity = 10000 a2.channels.channel1.transactionCapacity = 10000 a2.channels.channel1.keep-alive = 30 #defined e sink a2.sinks.hdfssink1.type = hdfs a2.sinks.hdfssink1.channel = channel1 a2.sinks.hdfssink1.hdfs.path = hdfs://192.168.14.50:8020/flumetest/spooldir1/%Y%m%d/ a2.sinks.hdfssink1.filePrefix = spooldir1 a2.sinks.hdfssink1.fileSuffix = .log a2.sinks.hdfssink1.hdfs.fileType = DataStream a2.sinks.hdfssink1.hdfs.writeFormat = Text a2.sinks.hdfssink1.hdfs.batchsize = 10000 a2.sinks.hdfssink1.hdfs.useLocalTimeStamp = true a2.sinks.hdfssink1.hdfs.rollCount = 0 a2.sinks.hdfssink1.hdfs.rollSize = 1048576500 a2.sinks.hdfssink1.hdfs.rollInterval= 0 a2.sinks.hdfssink1.hdfs.callTimeout = 60000
#注意spooldir监视的目录如果不存在启动会报错的,如下面的错误:
2017-12-02 18:29:52,640 (lifecycleSupervisor-1-3) [ERROR - org.apache.flume.lifecycle.LifecycleSupervisor$MonitorRunnable.run(LifecycleSupervisor.java:251)] Unable to start EventDrivenSourceRunner: { source:Spool Directory source spooldir1: { spoolDir: /tmp/logs } } - Exception follows.
java.lang.IllegalStateException: Directory does not exist: /tmp/logs
at com.google.common.base.Preconditions.checkState(Preconditions.java:145)
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.<init>(ReliableSpoolingFileEventReader.java:159)
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.<init>(ReliableSpoolingFileEventReader.java:85)
at org.apache.flume.client.avro.ReliableSpoolingFileEventReader$Builder.build(ReliableSpoolingFileEventReader.java:777)
at org.apache.flume.source.SpoolDirectorySource.start(SpoolDirectorySource.java:107)启动flume程序测试一波:
# mkdir /tmp/logs
# chown flume:flume /tmp/logs
$ flume-ng agent -n a2 -c conf -f conf/spooldir_hdfs1.conf -Dflume.root.logger=INFO,console
2017-12-02 19:09:45,385 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-12-02 19:09:45,806 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest/spooldir1/20171202//FlumeData.1512212985385.tmp 2017-12-02 19:18:03,523 (pool-4-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:324)] Last read took us just up to a file boundary. Rolling to the next file, if there is one. 2017-12-02 19:18:03,526 (pool-4-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:433)] Preparing to move file /tmp/logs/xaa to /tmp/logs/xaa.comp
#从上面最后的结果可以看到日志传完之后会把监控目录里面传输完的日志重命名成.comp结尾的文件。
# ls -lh /tmp/logs/
总用量 1001M -rw-r--r--. 1 root root 1000M 12月 2 19:08 xaa.comp
#现在如果你再xaa.comp文件里面插入内容的话是没用的,因为加了.comp后缀的就被认为是已经发送完毕了。
再发送过程中关闭flume程序再重启测试一波:
2017-12-02 21:43:58,097 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:251)] Creating hdfs://192.168.14.50:8020/flumetest/spooldir1/20171202//FlumeData.1512222237689.tmp 2017-12-02 21:50:08,543 (pool-5-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:324)] Last read took us just up to a file boundary. Rolling to the next file, if there is one. 2017-12-02 21:50:08,545 (pool-5-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:433)] Preparing to move file /tmp/logs/xab to /tmp/logs/xab.comp
#我这里把服务关闭了又启动了。
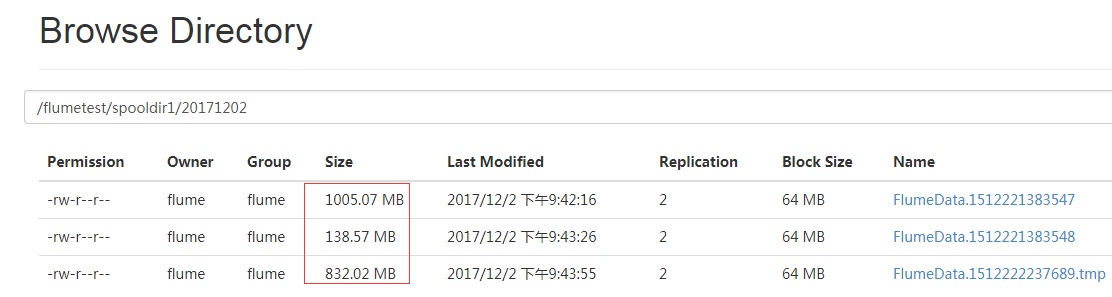
#从Hdfs上面可以看出一共是2G的日志文件,我拷贝了两个1G的文件到监控目录里面去。第一次是正常发送的,第二次是中断再发送的。由于定义了是到达指定大小再切割,所以这个尺寸上稍微差一点,但是大概的意思也可以看出来的是续传而非重新发送。
#可以看到如果flume程序因为什么原因意外关闭了,如果数据没有读,没有读完就不会重命名,不重命名,当你flume重新启动的时候,就会把监控目录里面不是.comp结尾的日志文件从断开的地方再重新发送,(我这里是拿1GB的日志文件来测试)。
#为什么是从程序死掉的地方而不是把文件重新发送一遍呢?是因为你如果使用spooldir这种格式,没当触发发送的时候会在spooldir监控的目录下面的隐藏目录下面产生一个记录文件之类的东西,记录你发送的文件名,发送的偏移量之类的。
# ls -l /tmp/logs/.flumespool/.flumespool-main.meta #这个文件只在发送成功前存在,一旦事件发送完毕就会自动消失
-rw-rw-r--. 1 flume flume 5067 12月 2 21:47 /tmp/logs/.flumespool/.flumespool-main.meta
三、使用avro来构建flume小集群
#上面已经展示了spooldir这种方式,比较适合采集离线数据,本来上面打算再写一个例子,后来想了想这里用一个完整点的例子展示一下吧。
#首先比如说你想把每天轮询的nginx日志发送到hdfs一份保存起来然后再去分析这些汇总上来的日志,那么多如果机器少,可以怎么玩呢?可以先把所有的日志打好压缩包然后放到一个汇聚节点的目录下,然后hadoop集群一台集群从汇聚节点拉节点,然后再根据固定规则将日志压缩包上传到hdfs集群。
#如果你想通过这种scp拉取的方式,想用flume来搞一下呢,那就不能单机玩了(当然也可以单机玩还是直接发送到hdfs里面白),搞个小集群试试吧。
3.1 一个比较low的方式
环境介绍
192.168.14.60为avro server端,接收来自于本地和另外两台机器192.168.14.61和192.168.14.62发来的nginx的log日志然后发送到hdfs集群上面。
先写个定时任务
# crontab -l #每个节点上面都有这么一个类似的定时任务
15 2 * * * /bin/sh /opt/scripts/flume_mvlog.sh >/dev/null 2>&1
# cat /opt/scripts/flume_mvlog.sh #这个脚本是实现后面的关键
#!/bin/bash
yesterday=`date -d -1day +%Y%m%d`
yestermon=`date -d -1day +%Y%m`
fifteendayago=`date -d -2day +%Y%m%d`
fifteenmonago=`date -d -2day +%Y%m`
ip=`ip addr|grep -i "inet "|awk 'NR==2{print $2}'|cut -d/ -f1`
nginx_logdir=/usr/local/nginx/logs
flume_conf=/home/flume/flume/conf
mkdir /songs/$yestermon/$yesterday -p
#比如说我们要将songs.access.log日志发送到hdfs上面,就创建/songs/昨天是属于哪个月/昨天的日期 的目录
ed -i "s#\.spoolDir=*.*#\.spoolDir=/songs/$yestermon/$yesterday#g" $flume_conf/avroclient.conf
#然后将监控的目录替换一下,让其监控去一个我们新创建的监控目录
sleep 60
#flume在运行的时候还会去检测自己所指定的conf文件是否发生了变化,如果发生了变化会动态的去加载配置文件,所以我这里让其sleep会
cd /songs/$yestermon/$yesterday
cp $nginx_logdir/$yesterday/songs.access.log /songs/$yestermon/$yesterday/$ip.tmp
#我这里把昨天的日志拷贝到我指定的监控目录,为了防止出问题,我先将其改为.tmp结尾的,这样此日志不符合标准就不会立马发送
sleep 30
mv /songs/$yestermon/$yesterday/$ip.tmp /songs/$yestermon/$yesterday/$ip
#然后将其重命名本地ip的日志名
sleep 30
cd /tmp
rm -Rf /songs/$fifteenmonago/$fifteendayago
#然后将大前天的日志目录删除掉,这里就无所谓了用find之类的也可以。客户端的配置文件的配置
# cat /home/flume/flume/conf/avroclient.conf
a1.sources = spooldir1 a1.channels = channel1 a1.sinks = avrosink1 Define a memory channel called channel1 on a1 a1.channels.channel1.type = memory a1.channels.channel1.capacity = 100000 a1.channels.channel1.transactionCapacity = 100000 a1.channels.channel1.keep-alive = 30 # Define an Avro source called avro-channel1 on a1 and tell it # to bind to 0.0.0.0:41414. Connect it to channel ch1. a1.sources.spooldir1.channels = channel1 a1.sources.spooldir1.type = spoolDir a1.sources.spooldir1.spoolDir= #配置文件也就第一次是这样的,然后上面的定时任务一执行这里就会变成绝对路径了 a1.sources.spooldir1.ignorePattern= ^(.)*\\.tmp$ #这里是忽略所有以tmp结尾的文件 a1.sources.spooldir1.deletePolicy = never a1.sources.spooldir1.batchSize = 100000 a1.sources.spooldir1.inputCharset = UTF-8 a1.sources.spooldir1.basenameHeader = true a1.sources.spooldir1.fileHeader = true a1.sources.spooldir1.basenameHeaderKey = basename #这里就是把主机名添加给了变量basename #a1.sources.spooldir1.interceptors = a #a1.sources.spooldir1.interceptors.a.type = org.apache.flume.interceptor.HostInterceptor$Builder #a1.sources.spooldir1.interceptors.a.preserveExisting = false #已经用不到拦截器了 a1.sources.spooldir1.fileSuffix = .comp # Define a logger sink that simply logs all events it receives # and connect it to the other end of the same channel. a1.sinks.avrosink1.channel = channel1 a1.sinks.avrosink1.type = avro a1.sinks.avrosink1.hostname = 192.168.14.60 #要把数据连接到哪个IP a1.sinks.avrosink1.port = 60000 #avro的哪个端口 a1.sinks.avrosink1.threads = 8 #产生工作线程的最大数量
# bin/flume-ng agent -n a1 -c conf -f conf/avroclient.conf -Dflume.root.logger=INFO,console #客户端启动flume服务
服务端的配置文件查看:
# cat /home/flume/flume/conf/avroserver.conf
a2.sources = avro_source1
a2.channels = channel1
a2.sinks = hdfs_sink1
#Define a memory channel called channel1 on a2
a2.channels.channel1.type = memory
a2.channels.channel1.capacity = 10000000
a2.channels.channel1.transactionCapacity = 10000000
#防止提交的事件太多造成通道阻塞,调大通道
a2.channels.channel1.keep-alive = 30
# Define an Avro source called avro-channel1 on a2 and tell it
# to bind to 0.0.0.0:41414. Connect it to channel ch1.
a2.sources.avro_source1.channels = channel1
a2.sources.avro_source1.type = avro
#指定源类型是avro
a2.sources.avro_source1.bind = 192.168.14.60
#指定自己源数据来源监听IP地址
a2.sources.avro_source1.port = 60000
#指定从哪个端口获取数据
a2.sources.avro_source1.batch-size = 1000000
a2.sources.avro_source1.connect-timeout = 120000
a2.sources.avro_source1.request-timeout = 120000
#将两个超时时间调大点省的客户端连接报错
# Define a logger sink that simply logs all events it receives
# and connect it to the other end of the same channel.
a2.sinks.hdfs_sink1.channel = channel1
a2.sinks.hdfs_sink1.type = hdfs
a2.sinks.hdfs_sink1.hdfs.path = hdfs://192.168.14.50:/flumetest/%{file}
#这个%{file}就是获取到客户端发来的绝对路径变量的值
a2.sinks.hdfs_sink1.hdfs.writeFormat = Text
a2.sinks.hdfs_sink1.hdfs.fileType = DataStream
a2.sinks.hdfs_sink1.hdfs.filePrefix = %{basename}
#这里是发送的文件名称
a2.sinks.hdfs_sink1.hdfs.fileType = CompressedStream
#启动压缩格式
a2.sinks.hdfs_sink1.hdfs.codeC = gzip
#压缩类型是gzip压缩
a2.sinks.hdfs_sink1.hdfs.idleTimeout = 0
a2.sinks.hdfs_sink1.hdfs.rollInterval = 600
a2.sinks.hdfs_sink1.hdfs.rollSize = 0
a2.sinks.hdfs_sink1.hdfs.rollCount = 0
a2.sinks.hdfs_sink1.hdfs.round = true
a2.sinks.hdfs_sink1.hdfs.roundUint = minute
a2.sinks.hdfs_sink1.hdfs.batchSize = 1000000
a2.sinks.hdfs_sink1.hdfs.callTimeout = 6000000
a2.sinks.hdfs_sink1.hdfs.useLocalTimeStamp = true$ flume-ng agent -n a2 -c conf -f conf/avroserver.conf -Dflume.root.logger=INFO,console #服务端启动flume服务
等到定时任务执行之后查看效果:

#从hdfs上面查看,可以看到我们按照日志的类型,以及日志产生的时间以及来源IP进行了目录划分,然后文件也是以IP命名的形式。
#因为hdfs里面哪里设置时间变量不能实现昨天的时间定义,因为我们传输的日志本来就是头一天的汇总日志嘛,通过这种方式呢就让其按照我们想要定义的时间格式来创建对应的目录并存放对应的日志文件了。
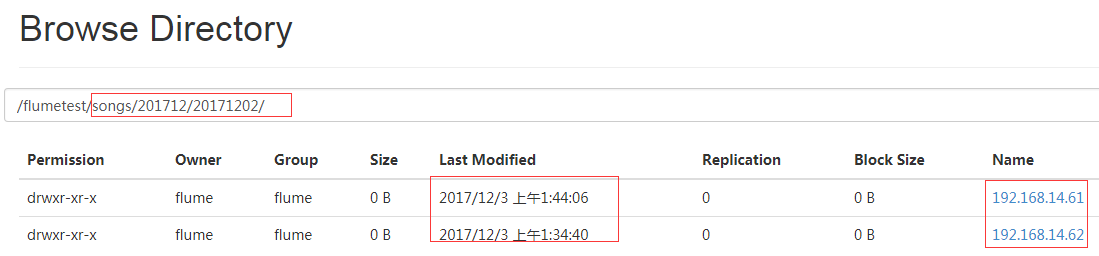
#再让另外一个客户端发送一下,可以看到我是12月3号提交的操作,但是日志目录是201712/20171202,这样又可以按月份区分日志又可以按日期来区分日志,虽然现在是12月3号,但是日志确实是12月2号全天的日志啊。另外,还可以让不同 IP的日志去对应的IP目录。
3.2 多channel多sink使用kafka sink
#还是接上面的例子配置文件继续向下写,按理说kafka是用来处理实时消息的,所以源应该是tail方式之类的实时读写消息的。
配置文件修改:
$ vim /home/flume/flume/conf/avroserver.conf
a2.sources = avro_source1
a2.channels = channel1 channel2
#多通道用空格隔开
a2.sinks = hdfs_sink1 kafka_sink2
#多sink用空格隔开
#Define a memory channel called channel1 on a2
a2.channels.channel1.type = memory
a2.channels.channel1.capacity = 10000000
a2.channels.channel1.transactionCapacity = 10000000
a2.channels.channel1.keep-alive = 30
# Define an Avro source called avro-channel1 on a2 and tell it
# to bind to 0.0.0.0:41414. Connect it to channel ch1.
a2.sources.avro_source1.channels = channel1 channel2
#源可以指向多个通道,这里指向了两个通道
a2.sources.avro_source1.type = avro
a2.sources.avro_source1.bind = 192.168.14.60
a2.sources.avro_source1.port = 60000
a2.sources.avro_source1.batch-size = 1000000
a2.sources.avro_source1.connect-timeout = 120000
a2.sources.avro_source1.request-timeout = 120000
# Define a logger sink that simply logs all events it receives
# and connect it to the other end of the same channel.
a2.sinks.hdfs_sink1.channel = channel1
a2.sinks.hdfs_sink1.type = hdfs
a2.sinks.hdfs_sink1.hdfs.path = hdfs://192.168.14.50:/flumetest/%{file}
a2.sinks.hdfs_sink1.hdfs.writeFormat = Text
a2.sinks.hdfs_sink1.hdfs.fileType = DataStream
a2.sinks.hdfs_sink1.hdfs.filePrefix = %{basename}
a2.sinks.hdfs_sink1.hdfs.fileType = CompressedStream
a2.sinks.hdfs_sink1.hdfs.codeC = gzip
a2.sinks.hdfs_sink1.hdfs.idleTimeout = 0
a2.sinks.hdfs_sink1.hdfs.rollInterval = 600
a2.sinks.hdfs_sink1.hdfs.rollSize = 0
a2.sinks.hdfs_sink1.hdfs.rollCount = 0
a2.sinks.hdfs_sink1.hdfs.round = true
a2.sinks.hdfs_sink1.hdfs.roundUint = minute
a2.sinks.hdfs_sink1.hdfs.batchSize = 1000000
a2.sinks.hdfs_sink1.hdfs.callTimeout = 6000000
a2.sinks.hdfs_sink1.hdfs.useLocalTimeStamp = true
#########kafka channel###########################
#Define a memory channel called channel2 on a2
a2.channels.channel2.type = memory
a2.channels.channel2.capacity = 10000000
a2.channels.channel2.transactionCapacity = 10000000
a2.channels.channel1.keep-alive = 30
#这里为kafka sink定义了一个内存通道
# Define a kafka sink for channel2
a2.sinks.kafka_sink2.channel = channel2
#让kafka连接内存通道channel2
a2.sinks.kafka_sink2.type = org.apache.flume.sink.kafka.KafkaSink
#定义sink2的类型是kafka类型
a2.sinks.kafka_sink2.topic = testflume
#连接的主题名称
a2.sinks.kafka_sink2.brokerList = 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092
#这里指定kakfa服务的IP和端口,多个用逗号隔开。官网这里指定的是bootstrap.servers参数,但是用这个参数启动报错,还是得用brokerList参数
a2.sinks.kafka_sink2.flumeBatchSize = 100
#一次处理多少条消息默认就是100
a2.sinks.kafka_sink2.producer.acks = 1
#默认值是1,领导节点的副本数写入成功就算成功了
a2.sinks.kafka_sink2.producer.linger.ms = 1
a2.sinks.kafka_sink2.producer.compression.type = snappy直接启动查看一下:
$ flume-ng agent -n a2 -c conf -f conf/avroserver.conf -Dflume.root.logger=INFO,console #输出太多只截取中间部分
2017-12-03 12:27:10,901 (lifecycleSupervisor-1-6) [INFO - org.apache.kafka.common.config.AbstractConfig.logAll(AbstractConfig.java:165)] ProducerConfig values: compression.type = none metric.reporters = [] metadata.max.age.ms = 300000 metadata.fetch.timeout.ms = 60000 reconnect.backoff.ms = 50 sasl.kerberos.ticket.renew.window.factor = 0.8 bootstrap.servers = [192.168.14.51:9092, 192.168.14.52:9092, 192.168.14.53:9092] retry.backoff.ms = 100 sasl.kerberos.kinit.cmd = /usr/bin/kinit buffer.memory = 33554432 timeout.ms = 30000 key.serializer = class org.apache.kafka.common.serialization.StringSerializer sasl.kerberos.service.name = null sasl.kerberos.ticket.renew.jitter = 0.05 ssl.keystore.type = JKS ssl.trustmanager.algorithm = PKIX block.on.buffer.full = false ssl.key.password = null max.block.ms = 60000 sasl.kerberos.min.time.before.relogin = 60000 connections.max.idle.ms = 540000 ssl.truststore.password = null max.in.flight.requests.per.connection = 5 metrics.num.samples = 2 client.id = ssl.endpoint.identification.algorithm = null ssl.protocol = TLS request.timeout.ms = 30000 ssl.provider = null ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1] acks = 1 batch.size = 16384 ssl.keystore.location = null receive.buffer.bytes = 32768 ssl.cipher.suites = null ssl.truststore.type = JKS security.protocol = PLAINTEXT retries = 0 max.request.size = 1048576 value.serializer = class org.apache.kafka.common.serialization.ByteArraySerializer ssl.truststore.location = null ssl.keystore.password = null ssl.keymanager.algorithm = SunX509 metrics.sample.window.ms = 30000 partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner send.buffer.bytes = 131072 linger.ms = 0 2017-12-03 12:27:11,167 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: avro_source1: Successfully registered new MBean. 2017-12-03 12:27:11,167 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: avro_source1 started 2017-12-03 12:27:11,169 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:260)] Avro source avro_source1 started. 2017-12-03 12:27:21,291 (lifecycleSupervisor-1-6) [INFO - org.apache.kafka.common.utils.AppInfoParser$AppInfo.<init>(AppInfoParser.java:82)] Kafka version : 0.9.0.1 2017-12-03 12:27:21,292 (lifecycleSupervisor-1-6) [INFO - org.apache.kafka.common.utils.AppInfoParser$AppInfo.<init>(AppInfoParser.java:83)] Kafka commitId : 23c69d62a0cabf06 2017-12-03 12:27:21,293 (lifecycleSupervisor-1-6) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SINK, name: kafka_sink2: Successfully registered new MBean. 2017-12-03 12:27:21,293 (lifecycleSupervisor-1-6) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SINK, name: kafka_sink2 started
#从上面的结果看是启动成功了,没有任何的ERROR和WARNING信息,只有INFO信息。
在客户端写入查看一下:
在192.168.14.62上面写入信息并查看:
# echo -e "nihaoma\n62 test\n flume to kafka" >>flume_kafka
在192.168.14.51(kafka)节点上面查看testtopic是否有信息生产出来:
# bin/kafka-console-consumer.sh --bootstrap-server 192.168.14.51:9092,192.168.14.52:9092,192.168.14.53:9092 --from-beginning --topic testflume
nihaoma 62 test flume to kafka
#从测试结果看可以了,如果现在是web日志格式的话,就会看到日志狂刷,就不粘贴web日志的测试结果了,太多了。

#hdfs写入也没问题,双通道双sink测试OK。
#还有很多其他的实现形式,例如做http sink来接受其他地方post提交的json数据(然后有开发能力通过写程序POST提交的方式来提交):
# curl -X POST -d '[{"server":"test","result":"haha"}]' http://192.168.14.60:9090#然后在将接收到的数据发布到不同的sink端(如写到hdfs,spark等)。通道方面可以试着采用:SPILLABLEMEMORY.
