大数据(六)Zookeeper分布式集群的搭建
一、Zookeeper介绍
官网介绍文档:http://zookeeper.apache.org/doc/trunk/zookeeperOver.html
1.1 Zookeerper简介
ZooKeeper本质上是一个分布式的小文件存储系统。原本是Apache Hadoop的一个组件,后来被拆分为一个Hadoop的独立子项目,现已经成为 Apache 的顶级项目。
Zookeeper是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。分布式协调技术 主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成"脏数据"的后果。分布式锁是分布式协调技术实现的核心内容。
Zookeeper 是为分布式应用程序提供高性能协调服务的工具集合,也是Google的Chubby一个开源的实现,是apache软件基金会的开源软件,是Hadoop 的分布式协调服务。它包含一个简单的原语集5,分布式应用程序可以基于它实现配置维护、命名服务、分布式同步、组服务等。Zookeeper可以用来保证数据在ZK集群之间的数据的事务性一致6。其中ZooKeeper提供通用的分布式锁服务7,用以协调分布式应用。
Zookeeper作为Hadoop项目中的一个子项目,是 Hadoop集群管理的一个必不可少的模块,它主要用来解决分布式应用中经常遇到的数据管理问题,如集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等。在Hadoop中,它管理Hadoop集群中的NameNode,还有在Hbase中Master Election、Server 之间状态同状步等。
Zookeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。
ZooKeeper性能上的特点决定了它能够用在大型的、分布式的系统当中。从可靠性方面来说,它并不会因为一个节点的错误而崩溃。除此之外,它严格的序列访问控制意味着复杂的控制原语可以应用在客户端上。ZooKeeper在一致性、可用性、容错性的保证,也是ZooKeeper的成功之处,它获得的一切成功都与它采用的协议——Zab协议是密不可分的。
1.2 Zookeeper的设计目标
简单化: ZooKeeper允许各分布式进程通过一个共享的命名空间相互联系,该命名空间类似于一个标准的层次型的文件系统:由若干注册了的数据节点构成(用Zookeeper的术语叫znode),这些节点类似于文件和目录。典型的文件系统是基于存储设备的,文传统的文件系统主要用于存储功能,然而ZooKepper的数据是保存在内存中的。也就是说,可以获得高吞吐和低延迟。ZooKeeper的实现非常重视高性能、高可靠,以及严格的有序访问。高性能保证了ZooKeeper可以用于大型的分布式系统,高可靠保证了ZooKeeper不会发生单点故障,严格的顺序访问保证了客户端可以获得复杂的同步操作原语。
健壮性: 它本身就是具有冗余结构,它构建在一系列主机之上,叫做一个”ensemble”。构成ZooKeeper服务的各服务器之间必须相互知道,它们维护着一个状态信息的内存映像,以及在持久化存储中维护着事务日志和快照。只要大部分服务器正常工作,ZooKeeper服务就能正常工作。客户端连接到一台ZooKeeper服务器。客户端维护这个TCP连接,通过这个连接,客户端可以发送请求、得到应答,得到监视事件以及发送心跳。如果这个连接断了,客户端可以连接到另一个ZooKeeper服务器。
有序性:ZooKeeper给每次更新附加一个数字标签,表明ZooKeeper中的事务顺序,后续操作可以利用这个顺序来完成更高层次的抽象功能。
速度优势:ZooKeeper特别适合于以读为主要负荷的场合。ZooKeeper可以运行在数千台机器上,如果大部分操作为读,例如读写比例为10:1,ZooKeeper的效率会很高。
ZooKeeper非常快速,非常简单。 既然它的目标是构建比较复杂的服务,比如同步,就提供了一套保证。 这些是:
顺序一致性 :来自客户端的更新将按照它们发送的顺序进行应用。
原子性 :更新成功或失败。 没有部分结果。
单系统映像 : 无论服务器连接到哪个服务器,客户端都将看到相同的服务视图。
可靠性 :一旦更新被应用,它将一直持续到客户覆盖更新。
及时性 :系统的客户观点在一定的时间范围内保证是最新的。
1.3 Zookerper的集群
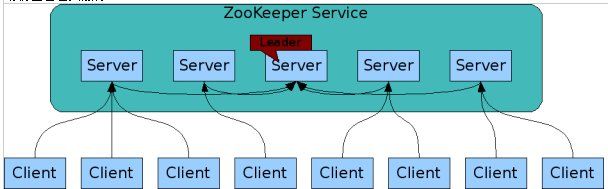
#如上图,ZK集群有五台服务器,有两种角色,除了一个领导者(Leader)以外其他的都是学习者(learner),其中领导者负责进行投票的发起和决议以及更新系统状态,学习者包括跟随者(follower)和观察者(observer),follower用于接收客户端请求并给客户端返回结果,并在选主过程中参与投票,observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
#客户端分别连在不同的ZK服务器上,如果当数据通过客户端在某一个Server服务器上做了一次数据变更,他会把这个数据的变化同步到其他所有的服务器,同步结束之后,其他客户端都会获得这个数据的变化。
#通常Zookerper由2n+1台server组成,每个server都知道彼此的存在。每个server都维护的内存状态镜像以及持久化存储的事务日志和快照。为了保证Leader选举能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。对于2n+1台server,只要有n+1台(大多数)server可用,整个系统保持可用。
1.4 Zookerper数据模型
ZooKeeper提供的名称空间与标准文件系统非常相似。 名称是由斜杠(/)分隔的一系列路径元素。 ZooKeeper名称空间中的每个节点都由一个路径标识。
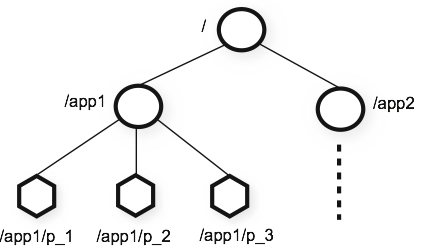
#上图是ZooKeeper的分层命名空间。从图中我们可以看出ZooKeeper的数据模型,在结构上和标准文件系统的非常相似,都是采用这种树形层次结构,ZooKeeper树中的每个节点被称为—Znode。和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。
引用方式:
与标准文件系统不同,ZooKeeper名称空间中的每个节点都可以有与其相关的数据以及子节点。这就像有一个文件系统,允许一个文件也是一个目录。 (ZooKeeper被设计用于存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点的数据通常很小,在字节到千字节范围内)。znode通过路径引用,路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在ZooKeeper中,路径由Unicode字符串组成,并且有一些限制。字符串"/zookeeper"用以保存管理信息,比如关键配额信息。
Znode结构:
Znodes维护一个统计结构,其中包括数据更改的版本号,ACL更改和时间戳,以允许缓存验证和协调更新。每当一个znode的数据发生变化,版本号就会增加。例如,每当客户端检索数据时,它也会收到数据的版本。
上图中每个节点称为一个znode,每个znode由3部分组成(stat:此为状态信息, 描述该znode的版本, 权限等信息。data:与该znode关联的数据。children:该znode下的子节点。)
ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多1M,但常规使用中应该远小于此值。
数据访问:
存储在名称空间中每个节点上的数据是以原子方式读取和写入的。读取获得与znode关联的所有数据字节,写入将替换所有数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么。
节点类型:
Zookeeper中的节点有两种,分为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
永久节点(Nodes):该节点的声明周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能删除。
临时节点(也成短暂节点ephemeral nodes): 该节点的生命周期依赖于创建它们的会话。只要创建znode的会话处于活动状态,就会存在这些znode。当会话结束时,znode被删除当然也可以手动删除。虽然每个临时的znode都会绑定到一个客户端会话,但它们对所有的客户端还是可见的,另外临时节点不允许拥有子节点。
#ZooKeeper目录树中每一个节点对应一个Znode。每个Znode维护着一个属性结构,它包含着版本号(dataVersion),时间戳(ctime,mtime)等状态信息。ZooKeeper正是使用节点的这些特性来实现它的某些特定功能。每当Znode的数据改变时,他相应的版本号将会增加。每当客户端检索数据时,它将同时检索数据的版本号。并且如果一个客户端执行了某个节点的更新或删除操作,他也必须提供要被操作的数据版本号。如果所提供的数据版本号与实际不匹配,那么这个操作将会失败。
观察(watches):
ZooKeeper支持watches的概念。 客户可以在znode上设置一个监视器。 当znode状态发生改变(znode的增、删、改)时将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
顺序节点(唯一性的保证):
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为“%10d”(10位数字,没有数值的数位用0补充,例如“0000000001”)。当计数值大于232-1时,计数器将溢出。
org.apache.zookeeper.CreateMode中定义了四种节点类型,分别对应:
PERSISTENT:永久节点
EPHEMERAL:临时节点
PERSISTENT_SEQUENTIAL:永久节点、序列化
EPHEMERAL_SEQUENTIAL:临时节点、序列化
1.5 简单的API
ZooKeeper的一个设计目标是提供一个非常简单的编程接口。 因此,它只支持这些操作:
1. create :在树中的一个位置创建一个节点
2. delete :删除一个节点
3. exists :测试节点是否存在于某个位置
4. get data :从节点读取数据
5. set data :将数据写入节点
6. get children :检索一个节点的子节点列表
7. sync :等待数据传播
1.6 读写请求
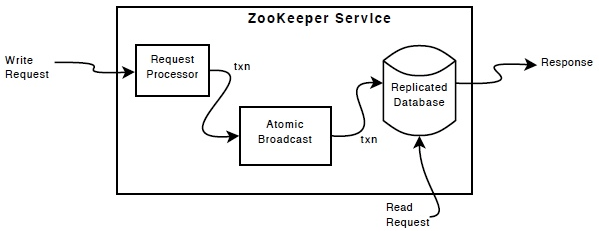
#ZooKeeper被设计为高性能的。在读取数量大于写入的应用程序中,性能特别高,因为写入操作涉及到同步所有服务器的状态。 (读出次数写入通常是协调服务的情况。)
#ZooKeeper的组件图中给出了ZooKeeper服务的高层次的组件。除了请求处理器(requestprocessor)外,构成ZooKeeper服务的每个服务器都有一个备份。复制的数据库(replicateddatabase)是一个内存数据库,包含整个数据树。为了可恢复,更新会被log到磁盘,并且在更新这个内存数据库之前,先序列化到磁盘。
#每个ZooKeeper都为客户端提供服务。客户端只连接到一个服务器,并提交请求。读请求直接由本地的复制数据库提供数据。对服务状态进行修改的请求、写请求通过一个约定的协议进行通讯。作为这个协议的一部分,所有的写请求都被传送到一个叫“首领(leader)”的服务器,而其他的服务器,叫做“(随从)followers”,follower从leader接收信息修改的提议,并同意进行。当leader发生故障时,协议的信息层(messaginglayer)关注leader的替换,并同步到所有的follower。
#ZooKeeper采用一个自定义的信息原子操作协议,由于信息层的操作是原子性的,ZooKeeper能保证本地的复制数据库不会产生不一致。当leader接收到一个写请求,它计算出写之后系统的状态,把它变成一个事务。
#与之前的3.1版本相比,3.2版本的r/w性能提高了约2倍。
博文来自:www.51niux.com
二、Zookeeper集群的搭建部署
现在我搞了3台测试机,192.168.1.38到192.168.1.40,都是Centos 7.2的操作系统,同步时间关闭selinux和firewalld这些就不说了。
Zookeeper运行需要java环境,需要安装jdk,注:每台服务器上面都需要安装zookeeper、jdk(jdk的安装部署就不写了,hadoop已经写了).
#注意:搭建zookeeper集群时,一定要先停止已经启动的zookeeper节点。
2.1 Zookeeper安装
#这是所有节点都要做的
# wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
# tar zxf zookeeper-3.4.10.tar.gz -C /home/hadoop/
# ln -s /home/hadoop/zookeeper-3.4.10 /home/hadoop/zookeeper
#cd /home/hadoop/zookeeper
# cp conf/zoo_sample.cfg conf/zoo.cfg
# vim /etc/profile #添加环境变量
############zookeeper############################### export ZOOKEEPER_HOME=/home/hadoop/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin
# source /etc/profile
2.2 配置文件修改
# vim /home/hadoop/zookeeper/conf/zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/zookeeperdata clientPort=2181 dataLogDir=/home/hadoop/zookeeperdata/zoolog server.1=192.168.1.38:2888:3888 server.2=192.168.1.39:2888:3888 server.3=192.168.1.40:2888:3888
# mkdir -p /home/hadoop/zookeeperdata
# mkdir -p /home/hadoop/zookeeperdata/zoolog
# chown -R hadoop:hadoop /home/hadoop/
#上面的参数说明:
tickTime #作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是说每个tickTime时间就会发送一个心跳,单位是毫秒。 initLimit #zookeeper接受客户端(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。 #当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 10*2000=20秒。 syncLimit #标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。 dataDir #zookeeper保存数据的目录,默认情况下zookeeper将写数据的日志文件也保存在这个目录里 clientPort #客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求 dataLogDir #如果没提供的话使用的则是dataDir。zookeeper的持久化都存储在这两个目录里。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。 server.A=B:C:D #A是一个数字,表示这个是第几号服务器,B是这个服务器的IP地址或者主机名,C第一个端口用来集群成员的信息交换,表示这个服务器与集群中的leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用的端口。
2.3 创建ServerID标识
#除了修改zoo.cfg配置文件外,zookeeper集群模式下还要配置一个myid文件,这个文件需要放在dataDir目录下。这个文件里面有一个数据就是A的值(该A就是zoo.cfg文件中server.A=B:C:D中的A),在zoo.cfg文件中配置的dataDir路径中创建myid文件。
#在192.168.1.38服务器上面创建myid文件,并设置值为1,与zoo.cfg文件里面的server.1保持一致,如下:
# echo "1">/home/hadoop/zookeeperdata/myid
#在192.168.1.39服务器上面创建myid文件,并设置值为2,与zoo.cfg文件里面的server.2保持一致,如下:
# echo "2">/home/hadoop/zookeeperdata/myid
#在192.168.1.40服务器上面创建myid文件,并设置值为3,与zoo.cfg文件里面的server.3保持一致,如下:
# echo "3">/home/hadoop/zookeeperdata/myid
2.4 启动集群并查看
#所有节点的操作
#su - hadoop -c "/home/hadoop/zookeeper/bin/zkServer.sh start" #通过hadoop用户启动zk服务
# /home/hadoop/zookeeper/bin/zkServer.sh status #查看zk状态
ZooKeeper JMX enabled by default Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg Mode: follower
#可以看出本节点是一个追随者节点。
# /home/hadoop/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg Mode: leader
#可以看到另一个节点是一个领导者
# jps
3718 QuorumPeerMain #QuorumPeerMain是zookeeper 进程
# tail -f /home/hadoop/zookeeper.out #可以看服务的启动输出
2.5 关于端口的连接
#lsof -i :2888
#这个如果是在leader节点的话,除了自己Listen外还有其他节点跟自己连接。如果是follower节点的话,只有自己的一个随机端口跟leader节点的2888连接的信息。
# lsof -i :3888
#都是除了自己的LISTEN外,还有跟其他zookeeper节点的ESTABLISHED状态的连接。
博文来自:www.51niux.com
三、使用
3.1 使用客户端连接
# /home/hadoop/zookeeper/bin/zkCli.sh -server localhost:2181 #命令行客户端连接zookeeper,连接成功后,会输出 ZooKeeper 的相关环境以及配置信息
[zk: localhost:2181(CONNECTED) 0] help #可以查看帮助说明,如下图:
# /home/hadoop/zookeeper-3.4.10/bin/zkCli.sh -server 192.168.1.40:2181 #远程客户端的连接测试
[zk: 192.168.1.40:2181(CONNECTED) 1] ls / [zookeeper]
3.2 客户端的一些操作
创建节点:
格式:create [-s] [-e] path data acl
#使用create命令,可以创建一个Zookeeper节点。其中,-s或-e分别指定节点特性,顺序或临时节点,若不指定,则表示持久节点;acl用来进行权限控制
] create -s /test "nihaoma" #创建了一个/test的永久顺序节点,关联的字符串nihaoma
Created /test0000000007 #顺序节点嘛后面的一串数字是顺序递增的
] create -e /temp "buhaoa" #创建一个临时节点/temp,关联的字符串buhaoa
Created /temp
] create /yongjiu "zouyibo" #创建了一个永久节点/yongjiu,关联的字符串zouyibo
Created /yongjiu
] create /yongjiu/feiqi "feiyibo"
Created /yongjiu/feiqi
] quit #退出
# /home/hadoop/zookeeper-3.4.10/bin/zkCli.sh -server 192.168.1.40:2181 #r然后重新登录
] ls / #查询根节点,会发现创建的临时节点不存在了,而其他的节点还存在,可以看到永久节点不同于顺序节点,后面不添加数字
[zookeeper, test0000000007, yongjiu]
] ls /yongjiu #ls命令可以列出Zookeeper指定节点下的所有子节点,只能查看指定节点下的第一级的所有子节点
[feiqi]
读取节点:
] get / #想获取根节点数据内容和属性信息
cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x100000021 cversion = 17 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 3 #根目录下面有几个子节点
] ls2 / #也可以通过ls2命令查看
[ceshi, zookeeper, test0000000007, yongjiu] cZxid = 0x0 ctime = Thu Jan 01 08:00:00 CST 1970 mZxid = 0x0 mtime = Thu Jan 01 08:00:00 CST 1970 pZxid = 0x100000023 cversion = 18 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 0 numChildren = 4
] get /yongjiu #可以看到子节点/yongjiu的数据内容和属性
zouyibo #可以看到起数据内容是zouyibo,我们创建节点的时候后面跟的字符串 cZxid = 0x10000001f ctime = Sun Nov 12 00:04:15 CST 2017 mZxid = 0x10000001f mtime = Sun Nov 12 00:04:15 CST 2017 pZxid = 0x100000020 cversion = 1 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 7 numChildren = 1
更新节点:
格式:set path data [version]
] set /yongjiu "zouliangbo" #更新/yongjiu节点的新内容为zouliangbo
cZxid = 0x10000001f ctime = Sun Nov 12 00:04:15 CST 2017 mZxid = 0x100000024 mtime = Sun Nov 12 00:20:10 CST 2017 #mtime时间也变化了 pZxid = 0x100000020 cversion = 1 dataVersion = 1 #这里从0变为1说明数据已经变化了 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 10 #数据长度也变化了 numChildren = 1
删除节点:
格式:delete path [version] # 使用delete命令可以删除Zookeeper上的指定节点,其中version也是表示数据版本
] delete /yongjiu #若删除节点存在子节点,那么无法删除该节点,必须先删除子节点,再删除父节点。
Node not empty: /yongjiu
] delete /yongjiu/feiqi #删除yongjiu节点下的子节点
] delete /yongjiu #再删除节点没有提示了
] ls / #可以看到/yongjiu节点删除掉了
[ceshi, zookeeper, test0000000007]
] rmr /ceshi #这个rmr命令就是不管要删除的节点下面有没有子节点都删除。
3.3 ZooKeeper 常用四字命令
ZooKeeper 支持某些特定的四字命令字母与其的交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令
# echo stat|nc 127.0.0.1 2181 #可以看到当前连接2181端口的IP以及其他的一些信息,以及自己是什么节点
Mode: leader #以及自己是leader节点还是follower节点
# echo dump| nc 127.0.0.1 2181 #列出未经处理的回话和临时节点
# echo ruok|nc 127.0.0.1 2181 #测试是否启动了该Server
imok #表示已经启动
# echo conf | nc 127.0.0.1 2181 #输出相关服务配置的详细信息
# echo cons | nc 127.0.0.1 2181 #列出所有连接到服务器的客户端的完全连接/会话的详细信息。
# echo envi |nc 127.0.0.1 2181 #输出关于服务的环境的详细信息,就相当于env
# echo reqs | nc 127.0.0.1 2181 #列出未经处理的请求
# echo wchs | nc 127.0.0.1 2181 #列出watch的详细信息
# echo mntr|nc 127.0.0.1 2181 #列出一些监控信息
zk_version 3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT #版本 zk_avg_latency 4 #平均延时 zk_max_latency 143 #最大延时 zk_min_latency 0 #最小延时 zk_packets_received 493 #接收到客户端请求的包数量 zk_packets_sent 492 #发送给客户单的包数量,主要是响应和通知 zk_num_alive_connections 2 #检测存活连接的节点数量 zk_outstanding_requests 0 #排队请求的数量,当ZooKeeper超过了它的处理能力时,这个值会增大,建议设置报警阀值为10 zk_server_state leader #本zk是什么节点 zk_znode_count 5 #znodes的数量 zk_watch_count 0 #watches的数量 zk_ephemerals_count 0 #临时节点的数量 zk_approximate_data_size 49 #数据大小 zk_open_file_descriptor_count 34 #打开文件描述符数量 zk_max_file_descriptor_count 4096 #最大文件描述符数量 zk_followers 2 #follower数量,leader角色才会有这个输出 zk_synced_followers 2 #同步的follower数量,leader角色才会有这个输出 zk_pending_syncs 0 #准备同步数 #zk_avg/min/max_latency :响应一个客户端请求的时间,建议这个时间大于10个Tick就报警
zabbix_api的使用请参阅链接:http://www.cnblogs.com/leesf456/p/6028416.html
