Hadoop(一)介绍与部署
写博客被朋友喷,写个东西也不介绍下,谁知道你写的是个什么东西,干什么的。好的下面对hadoop好好介绍介绍。
Hadoop是Apache开源组织的一个分布式计算开源框架(http://hadoop.apache.org/),Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。hadoop的作者是Doug Cutting。
hadoop大家已经不陌生了,一提到hadoop大家就会想到那个小象然后就会想到分布式大数据处理之类的。从2014年开始接触hadoop到现在一晃也好几年过去了不过尴尬的是没有了解多深,当时网上想找篇靠谱点的博客都费劲,现在已经博客漫天飞,各种视频网上也都可以找到,现在大家要想去了解和部署以及使用都已经不是什么难事了。这才几年时间,当时用hadoop的公司并不想现在使用这么广泛,现在已经遍地使用hadoop以及相关组件的技术了。hadoop的使用也从1.0过渡到了2.0。以前只是整理成文档了,现在回顾一下顺便在这里记录一下。废话不多说,进入正题。
一、Hadoop的介绍
1.1 大数据的4V特征:
特征:
volumn: 数据的体量大
velocity: 速度快,获得数据的速度
variaty: 样式多,数据类型的多样性
value: 价值密度低,合理运用大数据,以低成本创造高价值
数据单位:
最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。
它们按照进率1024(2的十次方)来计算:
1 Byte =8 bit 1 KB = 1,024 Bytes = 8192 bit 1 MB = 1,024 KB = 1,048,576 Bytes 1 GB = 1,024 MB = 1,048,576 KB 1 TB = 1,024 GB = 1,048,576 MB 1 PB = 1,024 TB = 1,048,576 GB 1 EB = 1,024 PB = 1,048,576 TB 1 ZB = 1,024 EB = 1,048,576 PB 1 YB = 1,024 ZB = 1,048,576 EB 1 BB = 1,024 YB = 1,048,576 ZB 1 NB = 1,024 BB = 1,048,576 YB 1 DB = 1,024 NB = 1,048,576 BB
1.2 Hadoop的优缺点:
优点:
是一款可靠地、可伸缩的、分布式计算的开源软件,具有高可靠性(按位存储和处理处理数据)、高扩展性、高效性(节点之间动态的移动数据并保证各节点的动态平衡)、高容错性(能够自动保存数据的多个副本并且能够自动将失败的任务重新分配)、低成本(hadoop是开源的集群可由廉价的pc机组成)、扩容能力强(在不保证低延时的前提下,具有相当大的吞吐量非常适合海量数据的运算)。
是一个框架,允许跨越计算机群的大数据集分布式处理,使用简单的编程模型(Mapreduce)来完成这些任务。
可从单个服务器扩展到成千上万台主机,每个节点都提供计算和存储功能。
不依赖于硬件处理HA,在应用层面来实现HA。
不足之处:
1. Hadoop提供给我们的只是一个框架,而不是一套完整的解决方案。
2. 人力上的问题,Hadoop属于开源架构,而开源有它先天不足或无法解决的问题,市场上当前Hadoop方面的人才相对比较少,这些对于企业而言,都会增加不少部署和应用上的难度。
3. Hadoop不适合处理小文件,之所以说Hadoop不适合处理小文件是由HDFS中的namenode局限性决定的,每个文件都会在namenode中保存相应的元数据信息,为了提升效率,这些信息在使用的过程中都是被保存在内存中的,如果小文件很多,则会消耗大量的namenode节点的内存,而对于单节点来讲,内存的扩展是有其上限的。反之,如果是相对较大,例如上GB或更大的文件,相对消耗的内存则会比较少。同时,在数据处理的过程中,系统开销的占比会小很多。这些架构上的特点和限制,决定了Hadoop更适合于处理“大”数据。
4. 该框架设计的初衷是针对海量数据的运算处理的问题。因此对于一些数据量很小的处理没有任何优势可言,甚至还不如单机串行的效果,性能也完全体现不出来。
5. 其文件系统设计的前提是一次写入多次读取的情况,因此我们是无法修改某条详细的数据,只能overwrite全部的数据,或者是在文件末尾追加数据。
6. 集群内部是通过tcp/ip协议进行通信的,所以网络带宽也会成为系统的瓶颈之一。
7. 安全问题。如果对外提供服务就要对外开放端口,那就有可能成为被攻击的目标
8. Hadoop可以支持百亿的数据量,但很难应对秒级响应的需求
1.3 Hadoop相关的项目:
hadoop的官网:http://hadoop.apache.org/
hadoop项目包括的模块:
Hadoop Common: 公共模块,公共类库支出其他其他Hadoop模块的常用实用程序。
Hadoop Distributed File System (HDFS):分布式文件系统,提供对应用程序数据的高吞吐量访问。
Hadoop YARN:作业调度和集群资源管理的框架。
Hadoop MapReduce:一种基于YARN的大型数据集并行处理系统。
Apache的其他与Hadoop相关的项目包括:
Ambari:基于Web提供管理监控hadoop的软件。用于配置,管理和监控Apache Hadoop集群的基于Web的工具,包括支持Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop。 Ambari还提供了一个用于查看集群健康状况的仪表板,如热图和可视化查看MapReduce,Pig和Hive应用程序以及以用户友好的方式诊断其性能特征的功能。 Avro:数据序列化系统。是一种提供高效、跨语言RPC的数据序列系统,持久化数据存储。 Cassandra:可扩展的多主数据库,没有单点故障。 Chukwa:用于管理大型分布式系统的数据收集系统。Chukwa运行HDFS中存储数据的收集器,它使用MapReduce来生成报告。 HBase:可扩展的分布式数据库,支持大型表格的结构化数据存储。一个分布式的、列存储数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)、实时读/写访问。 Hive:数据仓库基础架构,提供数据汇总和查询。它提供了类似于SQL的查询语言,通过使用该语言,可以方便地进行数据汇总,特定查询以及分析存放在Hadoop兼容文件系统中的大数据。 Mahout: 可扩展的机器学习和数据挖掘库。一种基于Hadoop的机器学习和数据挖掘的分布式计算框架算法集,实现了多种MapReduce模式的数据挖掘算法。 Pig:用于并行计算的高级数据流语言和执行框架,用以检索非常大的数据集。 Spark:用于Hadoop数据的快速而通用的计算引擎。 Spark提供了一个简单而富有表现力的编程模型,支持各种应用,包括ETL,机器学习,流处理和图形计算。Spark采用Scala语言实现,使用Scala作为应用框架。 Tez:一个基于Hadoop YARN的通用数据流编程框架,它提供了强大且灵活的引擎来执行任意DAG的任务来处理批量和交互式用例的数据。Tez被Hive,Pig和Hadoop生态系统中的其他框架以及其他商业软件(例如ETL工具)采用,以替代Hadoop MapReduce作为底层执行引擎。 ZooKeeper:分布式应用程序的高性能协调服务。一种集中服务,其用于维护配置信息,命名,提供分布式同步,以及提供分组服务。
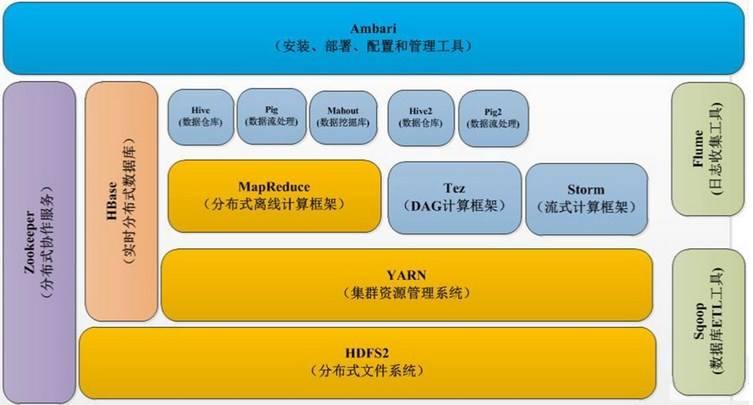
#上图是从网上找的hadoop 2.x生态系统组成图
1.4 Hadoop的版本发展:
hadoop的版本发展:http://hadoop.apache.org/releases.html #通过这个链接从页面最下方到最上面可以看到hadoop的版本发展
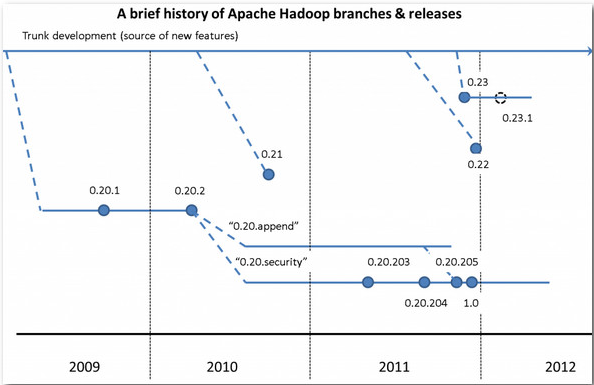
#上面是百度上面找的一张图片。
0.20.x版本最后演化成了现在的1.0.x版本
0.23.x版本最后演化成了现在的2.x版本
hadoop 1.0 指的是1.x(0.20.x),0.21,0.22
hadoop 2.0 指的是2.x,0.23.x
CDH3,CDH4分别对应了hadoop1.0 hadoop2.0
以前Hadoop版本比较混乱,让很多用户不知所措。实际上,当前Hadoop只有两个版本:Hadoop 1.0和Hadoop 2.0,其中,Hadoop 1.0由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成,而Hadoop 2.0则包含一个支持NameNode横向扩展的HDFS,一个资源管理系统YARN和一个运行在YARN上的离线计算框架MapReduce。相比于Hadoop 1.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。截止到写这篇博客如今Hadoop 2.0已经发布了最新的稳定版2.7.4。
1.5 Hadoop 1.0的框架:
Hadoop1.0架构包括HDFS架构与MapReduces架构。
HDFS架构:
NameNode: Hadoop集群中只有一个NameNode,它负责管理HDFS的目录树和相关文件的元数据信息,它是Hadoop守护进程中最重要的一个。Hadoop在分布式计算与分布式存储中都采用了主从结构。分布式存储系统被称为Hadoop文件系统(HDFS),NameNode位于HDFS的主端,它指导从端的DataNone执行底层的I/O任务。它跟踪文件如何被分割成文件块,而这些块又被哪些节点存储,以及分布式文件系统的整体运行状态是否正常。运行NameNode消耗大量的内存和I/O资源,因此驻留NameNode的服务器通常不会存储用户数据或者执行MapReduce程序的计算任务。也就是说NameNode服务器不会同时是DataNode或者TaskTracker.
DataNode: 每个集群上的从节点都会驻留一个DataNode守护进程,负责将HDFS数据库读取或者写入到本地文件系统的实际文件中。当希望对HDFS文件进行读写时,文件被分割为多个块,由NameNode告知客户端每个数据块驻留在哪个DataNode。客户端直接与DataNode守护进程通信,来处理与数据块相对应的本地文件。而后,DataNode会与其他DataNode进行通信,复制这些数据块以实现冗余。DataNode在初始化时,每个DataNode将当前存储的数据块告知NameNode,在这个初始映射完成后,DataNode扔会不断地更新NameNode,为之提供本地修改的相关信息,同时接收指令创建、移动或删除本地磁盘上的数据块。
Secondary NameNode(SNN): 有两个作用,一个是镜像备份,二是日志与镜像定期合并,并传输给NameNode。SNN是一个用于监测HDFS集群状态的辅助守护进程,每个集群有一个SNN通常也独占一台服务器,也不会运行其他的DataNode或TaskTracker守护进程。SNN与NameNode的不同在于它不接收或记录HDFS的任何实时变化,相反它与NameNode通信,根据集群所配置的时间间隔获取HDFS元数据的快照。
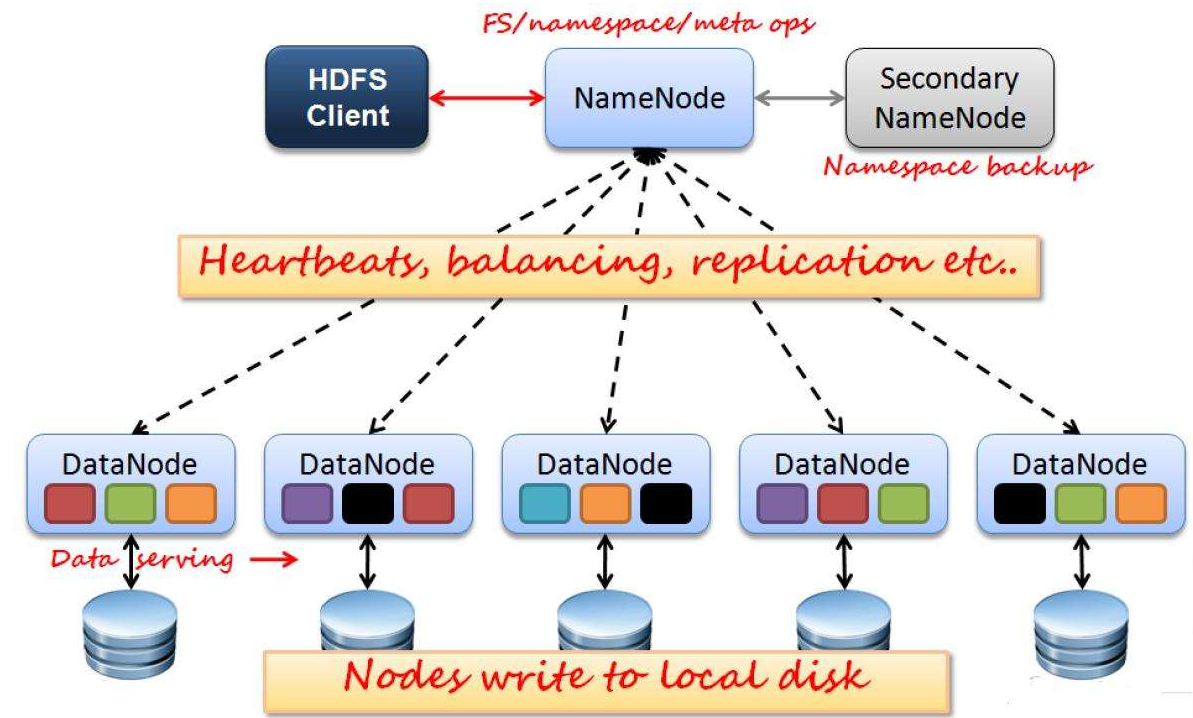
#上面是网上找的一张HDFS1.0的架构图
MapReduce架构:
MapReduce采用Master/Slave架构。Master: 是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等,即MapReduce中的JobTracker。Slave: 负责任务的执行和任务状态的汇报,即MapReduce中的TaskTracker。
JobTracker: JobTracker是一个后台服务进程,启动之后,会一直监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。JobTracker的主要功能一个是作业控制(在hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的作业控制模块则负责作业的分解和状态监控),另一个功能是状态监控(主要包括TaskTracker状态监控、作业状态监控和任务状态监控,主要作用是容错和为任务调度提供决策依据)。如果任务失败,JobTracker将自动重启任务但所分配的节点可能会不同,同时受到预定义的重试次数限制。每个Hadoop集群只有一个JobTracker守护进程,通常运行在集群的主节点上。
TaskTracker: 每个TaskTracker负责执行由JobTracker分配的单项任务。虽然每个从节点上仅有一个TaskTracker,但每个TaskTracker可以生成多个JVM(Java虚拟机)来并行地处理许多map或reduce任务。TaskTracker的一个职责是持续不断地与JobTracker通信。如果JobTracker在指定的时间内没有收到来自TaskTracker的“心跳”,它会假定TaskTracker已经崩溃进而重新提交相应的任务到集群中的其他节点中。TaskTracker的功能:第一个是汇报心跳,而信息包括机器级别信息(节点健康状况、资源使用情况等),任务级别信息(任务执行进度、任务运行状态等)。第二个是执行命令,JobTracker会给TaskTracker下达各种命令,主要包括:启动任务(LaunchTaskAction)、提交任务(CommitTaskAction)、杀死任务(KillTaskAction)、杀死作业(KillJobAction)和重新初始化(TaskTrackerReinitAction)。
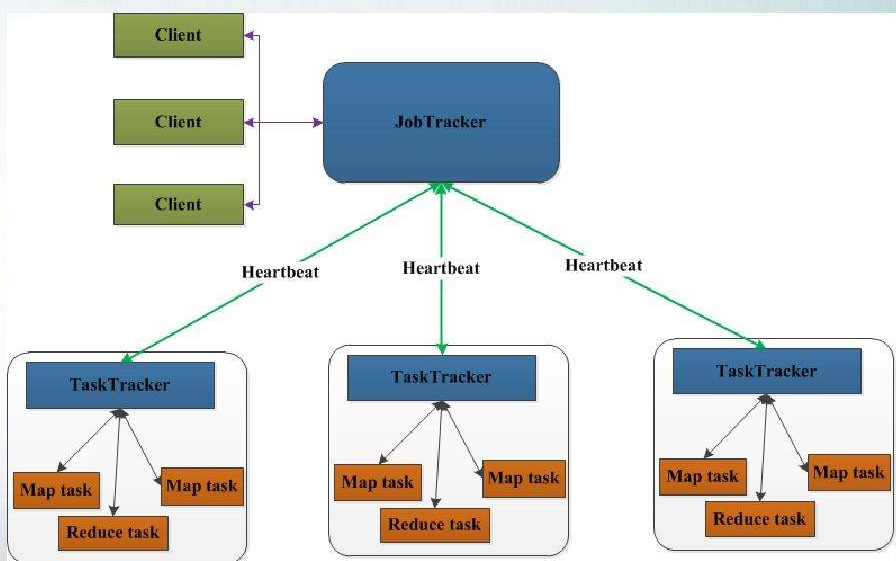
#上面是网上找的一张MapReduce的架构图
1.6 Hadoop 2.0的框架:
Hadoop2.0架构包括HDFS架构与MapReduce v2.0或Yarn架构(Hadoop0.23以后)。
HDFS架构:
NameNode:Hadoop集群中可以有两个NameNode(hadoop2.2以后),一个节点活跃一个处于待命状态,可自动切换与手工切换,它负责管理HDFS的目录树和相关文件的元数据信息。更高级结构,namenode的镜像文件存储在多节点。 在一个典型的HA集群中,每个NameNode是一台独立的服务 器。在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客 户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。两个NameNode为了数据同步,会通过一组称作 JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的 JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控Edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。其他节点的作用没变。
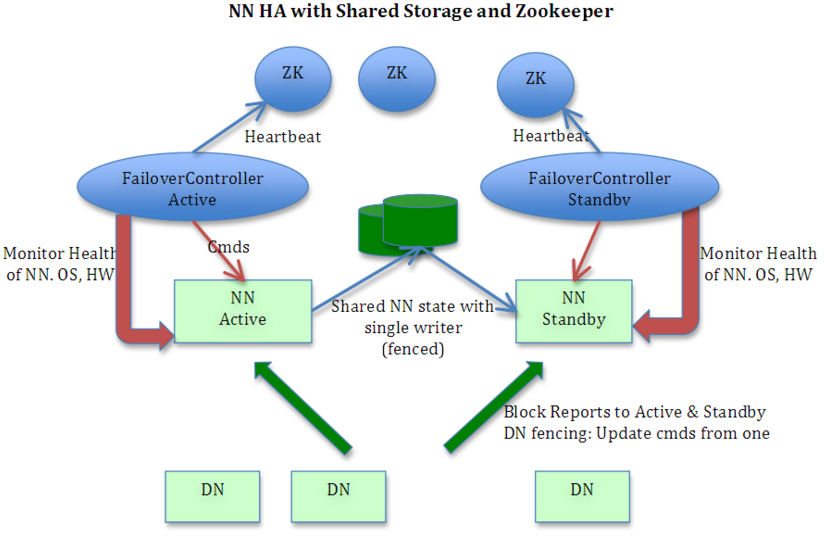
#上图是来源于网上,上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统.Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步.journalnode的作用是在HA的两个namenode之间保持editlog的共享同步。zookeeper用于两个namenode之间互相的错误感知(active的掉了,standby的可以看见)。
Yarn架构:
YARN是Master/Slave架构,主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。YARN可以将多种计算框架(如离线处理MapReduce、在线处理的Storm、内存计算框架Spark等)部署到一个公共集群中,公共集群的资源,并提供资源的统一管理和调度和资源隔离(YARN使用了轻量级资源隔离机制Cgroup进行资源隔离以避免相互干扰,一旦Container使用的资源量超过事先定义的上限值就将其杀死)。
1. ResourceManager(RM): 负责集群中的所有资源的统一管理和分配,接受来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各种应用程序(ApplicationMaster)并监控其运行状态。对AM申请的资源请求分配相应的空闲Container。其主要由两个组件构成:调度器和应用程序管理器。(hadoop2.4以后结合Zookeeper实现HA)。调度器(Scheduler):调度器根据容器、队列等限制条件,将系统中的资源分配给各个正在运行的应用程序。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位是Container,从而限定每个任务使用的资源量。应用程序管理器(Application Manager):应用程序管理器负责管理整个系统中所有的应用程序,包括应用程序提交,与调度器协商资源以启动AM,监控AM运行状态并在失败时重新启动等。
2. NodeManager(NM):与ApplicationMaster承担了MR1框架中的tasktracker角色,负责将本节点上的资源使用情况和任务运行进度汇报给ResourceManager。NM是每个节点上的资源和任务管理器。它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;同时会接收并处理来自AM的Container 启动/停止等请求。
3. ApplicationMaster(AM): 用户提交的应用程序均包含一个AM,负责应用的监控,跟踪应用程序执行状态,重启失败任务等。
4. Container: Container封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,是YARN对资源的抽象。当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的,YARN会为每个任务分配一个Container且该任务只能使用该Container中描述的资源。
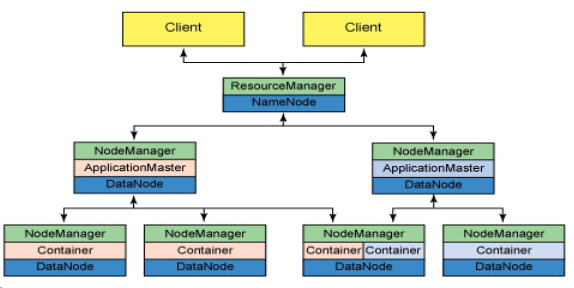
#上图是以前word里面保存的图。
YARN应用工作流程:
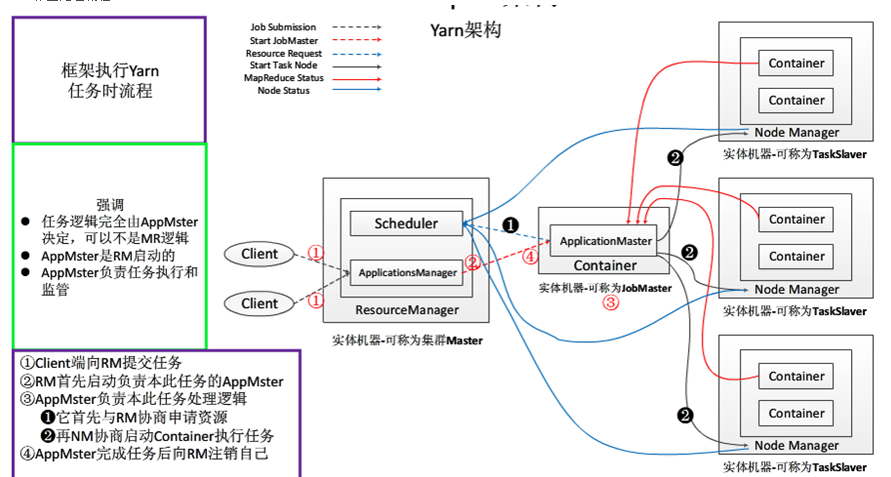
#此图来源博客:http://www.cnblogs.com/yangsy0915/p/4866995.html
用户向YARN中提交一个应用程序后,YARN将分两个节点运行该应用程序:启动AM(下面步骤1-3),由AM创建应用程序,申请资源并监控其整个运行过程,直到运行完成(下面步骤4-7).
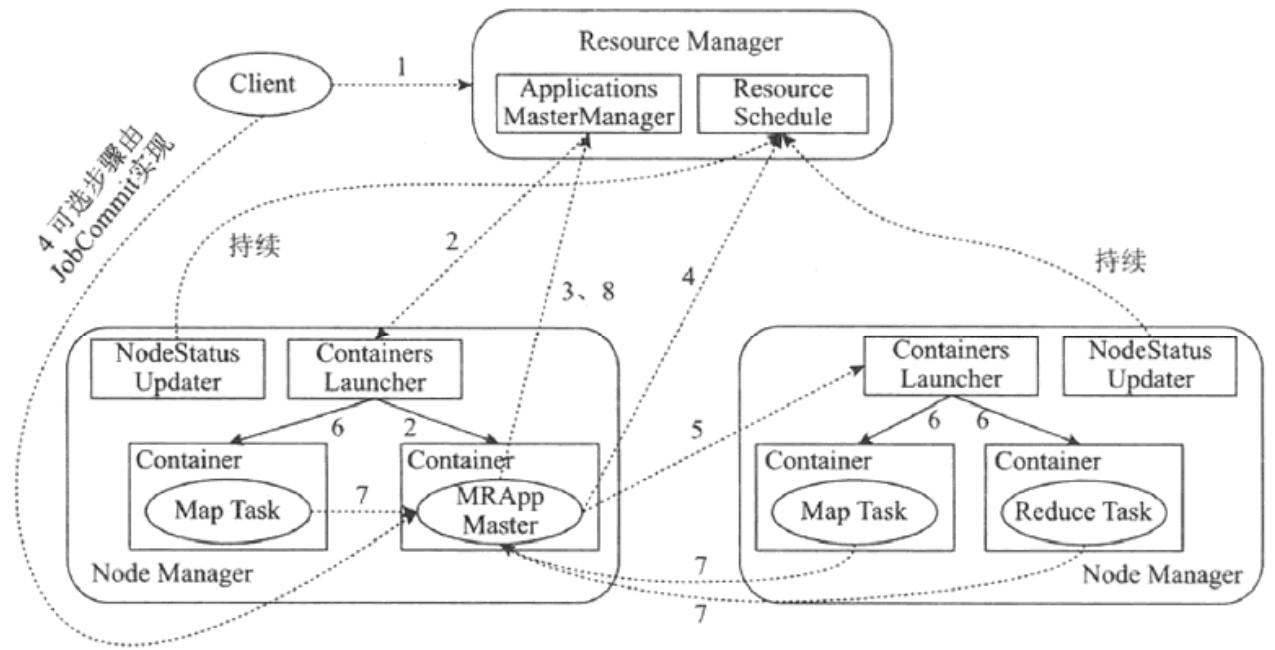
#上图以及下面的步骤说明来自《大数据架构师指南》
用户向YARN提供应用程序,其中包括AM程序、启动AM的命令、用户程序等;
RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container种启动AM;
AM首先向RM注册,这样用户可以直接通过RM查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束(重复上图中的步骤4-7)。
AM采用轮询的方式通过RPC协议向RM申请和领取资源;
一旦AM申请到资源后,便与对应的NM通信,要求它启动任务
NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
应用程序运行完成后,AM向RM注销并关闭自己。
YARN资源调度模型:
YARN提供了一个资源管理平台能够将集群中的资源统一进行管理。所有节点上的多维度资源都会根据申请抽象为一个个Container。
YARN采用了双层资源调度模型:
1. RM中的资源调度器将资源分配给各个AM:资源分配过从是异步的。资源调度器将资源分配给一个应用程序后,不会立刻push给对应的AM,而是暂时放到一个缓冲区中,等待AM通过周期性的心跳主动来取。 2. AM领取到资源后再进一步分配给它内部的各个任务:不属于YARN平台的范畴,由用户自行实现。
YARN目前采用的资源分配算法有三种:
1. 先来先调度FIFO: 先按照优先级高低调度,如优先级相同则按照提交时间先后顺序调度,如提交时间相同则按照队列名或Application ID比较顺序调度。 2. 公平调度FAIR: 该算法的思想是尽可能地公平调度,即已分配资源量少的优先级高。 3. 主资源公平调度DRF: 该算法扩展了最大最小公平算法,使之能够支持多维资源,算法是配置资源百分比小的优先级高。
1.7 分布式计算框架MapReduce
MapReduce致力于解决大规模数据处理的问题,利用局部性原理将整个问题分而治之。MapReduce在处理之前,将数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(Map),将处理后的数据进行合并(Combine)、排序(Shuffle and Sort)后再分发(至Reduce节点),避免了大量数据的传输,提高了处理效率。配合数据复制(Replication)策略,集群可以具有良好的容错性,一部分节点的宕机对集群的正常工作不会造成影响。当然MapReduce框架也从最初MRv1由(一个)JobTracker和(若干)TaskTracker构成演变成了现在MRv2的YARN(由ResourceManager、NodeManager,YARN提供一个资源管理和调度的平台)和MRAppmaster(作为运行在YARN资源管理平台上的一个应用,仅负责一个作业的管理)构成。MRv1仅是一个独立的离线计算框架,而MRv2解决了MRv1的扩展性差、可靠性差、资源利用率低等问题,同时兼容MRv1的API.
MapReduce作为分布式计算框架主要组成部分:
编程模型: 为用户提供易用的编程接口,用户只需要考虑如何使用MapReduce模型描述问题,实现几个简单的hook函数即可实现一个分布式程序。
数据处理引擎:由MapTask和ReduceTask组成,分别负责Map阶段逻辑核Reduce节点逻辑的处理。
运行时环境: 用以执行MapReduce程序,并行程序执行的诸多细节,如分发、合并、同步、监测等功能均交由执行框架负责,用户无须关心这些细节。
MapReduce可编程组件:
MapReduce提供了5个可编程组件,实际上可编程组件全部属于回调接口。当用户按照约定实现这几个接口后,MapReduce运行时环境会自动调用以实现用户定制的效果。
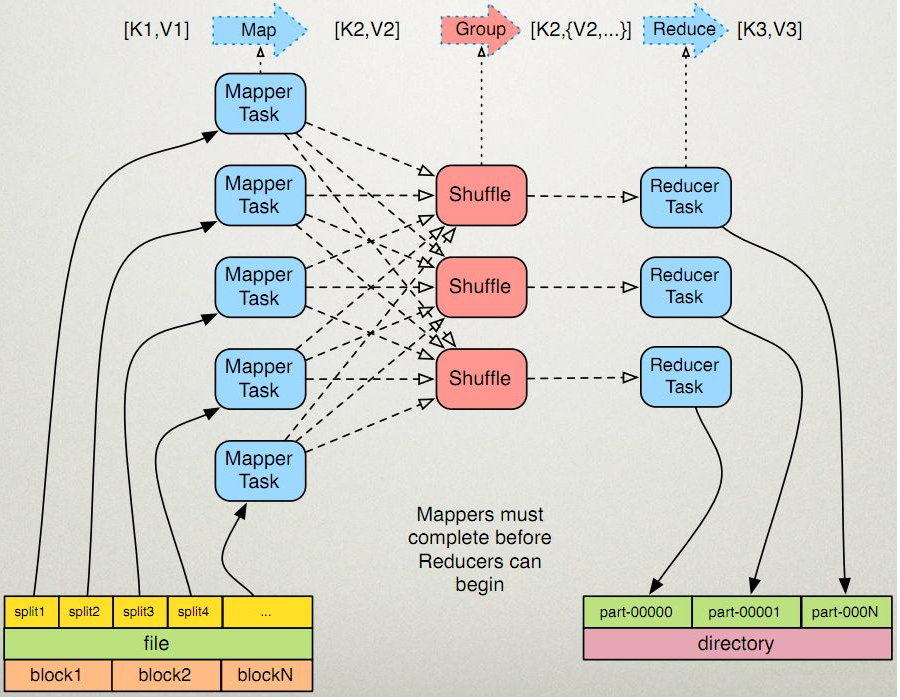
#此图来源于:http://www.cnblogs.com/sharpxiajun/p/3151395.html
MapReduce可编程组件:
InputFormat: 主要用于描述输入数据的格式,其按照某个策略将输入数据切分成若干个split,并为Mapper提供输入数据,将split解析成一个个key/value对。
Mapper: 对split传入的key1/value1对进行处理,产生新的键值key2/value2对,即Map:(k1,v1)=>(k2,v2)。
Partitioner: 作用是对Mapper产生的中间结果进行区分,以便将key有耦合关系的数据交给同一个Reducer处理,它直接影响Reduce阶段的负载均衡。
Reducer: 以Map的输出作为输入,对其进行排序和分组,再进行处理产生新的数据集,即Reducer: (k2,list(v2)) =》(k3, v3)。
OutputFormat: 主要用于描述输出数据的格式,它能够将用户提供的key/value对写入特定格式的文件中。
编程流程的运行流程如下:
作业提交后,InputFormat按照策略将输入数据切分若干个Split;
各Map任务节点上根据分配的Split元信息获取相应数据,并将其迭代解析成一个个key1/value1对;
迭代的key1/value1对由Mapper处理为新的key2/value2对;
新的key2/value2对先进行排序,然后由Partitioner将有耦合关系的数据分到同一个Reducer上进行处理,中间数据存入本地磁盘;
各Reduce任务节点根据已的Map节点远程获取数据(只获取属于该Reduce的数据,该过程称为Shuffle);
对数据进行排序,并进行分组(将相同key的数据分为一组);
迭代key/value对,并由Reducer合并处理为新的key3/value3对;
新的key3/value3对由OutputFormat保存到输出文件中。
MapReduce数据处理引擎
在MapReduce计算框架中,一个Job被划分为Map何Reduce两个计算阶段,它们分别由多个Map Task和Reduce Task组成,这两种服务构成了MapReduce数据处理引擎,入下图:
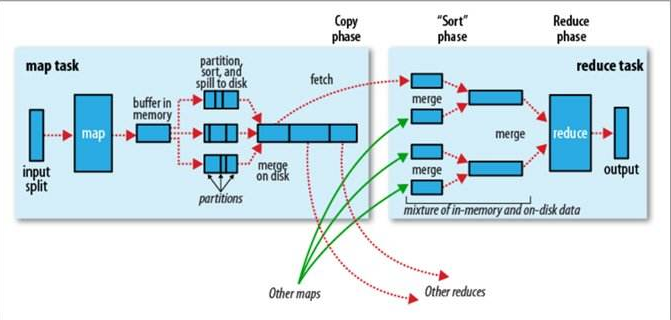
Map Task的整体计算流程共分为5个阶段:
Read阶段: MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
Map阶段: 将解析出的key/value交给用户编写的Map函数处理,并产生一系列新的key/value。
Collect阶段:Map函数生成的key/value通过调用Partitioner进行分片,并写入一个环形内存缓冲区中。
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。
Combine阶段:所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
Reduce Task的整体计算流程共分为5个阶段:
Shuffle阶段:Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如其大小超过一定阀值则写到磁盘上,否则直接放到内存中。
Merge阶段:在远程拷贝数据的同时,Reduce Task启动了3个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
Sort阶段:采用了基于排序的策略将key相同的数据聚在一起,由于各个Map Task已经实现对自己的处理结果进行了局部排序,因为Reduce Task只需对所有数据进行一次归并排序即可。
Reduce阶段: 将每组数据依次交给用户编写的reduce函数处理。
Write阶段: reduce函数将计算结果写到HDFS上。
博文来自:www.51niux.com
二、Hadoop测试集群的搭建
这里先搭建一个简单的最传统的hadoop集群,然后再一点点丰富起来。
官网文档:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
1.1 软件说明以及节点说明

节点名称 | 应用角色 | IP地址 |
master.hadoop | ResourceManager,namenode | 192.168.14.49 |
smaster.hadoop | SecondaryNameNode | 192.168.14.50 |
slave01.hadoop | DataNode , NodeManager | 192.168.14.51 |
slave02.hadoop | DataNode , NodeManager | 192.168.14.52 |
slave03.hadoop | DataNode , NodeManager | 192.168.14.53 |
slave04.hadoop | DataNode , NodeManager | 192.168.14.54 |
1.2 安装前准备(所有节点)
所有节点之间做好时间同步,关闭防火墙,关闭selinux,并修改成对应的主机名(如:hostnamectl set-hostname master.hadoop)。
所有节点修改打开文件数限制:
# cat /etc/security/limits.conf #在尾部添加四行,加大打开文件数的限制(open files)
* soft nofile 1024000 * hard nofile 1024000 hadoop - nofile 1024000 hadoop - nproc 1024000 # End of file
#不过,在CentOS 7/RHEL 7的系统中,使用Systemd替代了之前的SysV,因此/etc/security/limits.conf文件的配置作用域缩小了一些。limits.conf这里的配置,只适用于通过PAM认证登录用户的资源限制,它对systemd的service的资源限制不生效。登录用户的限制,与上面讲的一样,通过/etc/security/limits.conf和limits.d来配置即可。
# cat /etc/systemd/system.conf
DefaultLimitCORE=infinity DefaultLimitNOFILE=1024000 DefaultLimitNPROC=1024000
#systemd service的资源限制的配置,全局的配置,放在文件/etc/systemd/system.conf和/etc/systemd/user.conf。同时,也会加载两个对应的目录中的所有.conf文件/etc/systemd/system.conf.d/*.conf和/etc/systemd/user.conf.d/*.conf。其中,system.conf是系统实例使用的,user.conf用户实例使用的。一般的sevice,使用system.conf中的配置即可。systemd.conf.d/*.conf中配置会覆盖system.conf。
#注意:修改了system.conf后,需要重启系统才会生效。
#查看一个进程的limit设置:cat /proc/YOUR-PID/limits
每个节点创建hadoop用户与创建目录并授权:
# useradd -u 2527 hadoop #所有节点执行创建hadoop用户操作
# chown hadoop:hadoop /etc/hosts #方便后面的操作,不然还老需要root用户来改这个文件
# mkdir /data{01..10} #datanode节点执行挂载目录的创建
# for num in `lsblk -l|grep -v sda|grep sd|awk {'print $1'}`;do mkfs.ext4 /dev/$num;done #对挂载盘批量格式化
#cat>>/etc/rc.local<<EOF
mount /dev/sdb /data01
mount /dev/sdc /data02
mount /dev/sdd /data03
mount /dev/sde /data04
mount /dev/sdf /data05
mount /dev/sdg /data06
mount /dev/sdh /data07
mount /dev/sdi /data08
mount /dev/sdj /data09
mount /dev/sdk /data10
EOF
#上面是datanode节点上硬盘挂载添加开机自启动,然后把里面内容复制出来手工执行一下
# chown -R hadoop:hadoop /data*
每个节点上面都要做好/etc/hosts:
# cat /etc/hosts
192.168.14.49 master.hadoop 192.168.14.50 smaster.hadoop 192.168.14.51 slave01.hadoop 192.168.14.52 slave02.hadoop 192.168.14.53 slave03.hadoop 192.168.14.54 slave04.hadoop
做master.hadoop到其他节点的hadoop用户的无密钥登录(主节点的操作):
# su - hadoop
$ ssh-keygen -t rsa
$ ssh-copy-id smaster.hadoop
$ ssh-copy-id slave01.hadoop
$ ssh-copy-id slave02.hadoop
$ ssh-copy-id slave03.hadoop
$ ssh-copy-id slave04.hadoop
所有节点安装jdk环境:
# rpm -ivh jdk-8u74-linux-x64.rpm
# ln -s /usr/java/jdk1.8.0_74 /usr/java/jdk
# vim /etc/profile
###########java############################ export JAVA_HOME=/usr/java/jdk export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=$JAVA_HOME/lib/*.jar:$JAVA_HOME/jre/lib/*.jar
# java -version #查看一下java版本
1.3 Hadoop的安装与配置(在主节点上面配置好再发送就可以了):
#wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
# tar zxf hadoop-2.7.4.tar.gz
# cp -r hadoop-2.7.4 /home/hadoop/
# chown -R hadoop:hadoop /home/hadoop
# ln -s /home/hadoop/hadoop-2.7.4 /home/hadoop/hadoo
# vi /etc/profile #这个环境是所有节点都要配置的
#############hadoop##########################################
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin/:$HADOOP_HOME/bin/# source /etc/profile
hadoop-env.sh文件配置:
#格式是bash脚本,是在运行Hadoop的脚本中使用的环境变量。
# vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh #在hadoop-env.sh文件中还包含定义Hadoop环境的其他变量
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk #指定hdk的安装路径
#export HADOOP_HEAPSIZE=
export export HADOOP_HEAPSIZE=2000 #给HADOOP后台进程用的内存大小,默认是1000M,大型集群一般设置2000M或以上,开发环境中设置500M足够了。
#export HADOOP_NAMENODE_INIT_HEAPSIZE=""
export HADOOP_NAMENODE_INIT_HEAPSIZE="10240"
export HADOOP_PORTMAP_OPTS="-Xmx2048m $HADOOP_PORTMAP_OPTS" #内存调优从512调到2048
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS" #设定hadoop提交程序时client的jvm大小,从512跳到2048
export LD_LIBRARY_PATH=/usr/local/lzo-2.06/lib #这个lzo后面就会用到,以lzo压缩格式存到hdfs中,然后hadoop可以对lzo格式的压缩文件进行分析汇总yarn-env.sh文件配置:
# vim /home/hadoop/hadoop/etc/hadoop/yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ export JAVA_HOME=/usr/java/jdk #指定jdk的位置
core-site.xml文件配置:
#Hadoop配置的XML文件,Hadoop核心的配置。
# vim /home/hadoop/hadoop/etc/hadoop/core-site.xml #默认配置文件里面是空的,完全自己填。#http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml #官网提供的参数
<configuration>
<property>
<name>fs.defaultFS</name> #定义HDFS文件系统的的URI和端口,接收Client连接的RPC端口,用于获取文件系统metadata信息。
<value>hdfs://master.hadoop</value> #默认是8020,如果设置成hdfs://master.hadoop:9000,就是将8020端口改为9000端口
</property>
<property>
<name>io.file.buffer.size</name> #用作序列化文件处理时读写buffer的大小,这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以设置为64KB(65536byte)或更大。
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name> #文件系统依赖的基础配置,很多路径都依赖它。它默认的位置是在/tmp/hadoop-${user.name}下面,但是在/tmp路径下的存储是不安全的,因为linux一次重启,文件就可能被删除
<value>file:/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>io.compression.codecs</name> #可用于压缩/解压缩的压缩编解码器类的逗号分隔的列表。除了与这个属性(优先)指定的任何类,在类路径中的编解码器类使用Java的ServiceLoader发现的。
<value>org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name> #LZO所使用的压缩编码器
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
</property>
</configuration>#如:fs.trash.interval这个是开启hdfs文件删除自动转移到垃圾箱的选项,值为垃圾箱文件清除时间。一般开启这个会比较好,以防错误删除重要文件。单位是分钟。默认值是0.等一些配置就看需求了。
#如果你想看xml文件里面最全的配置文件呢,就以core-site.xml文件和hdfs-site.xml配置文件为例(这就得借助windows机器了):
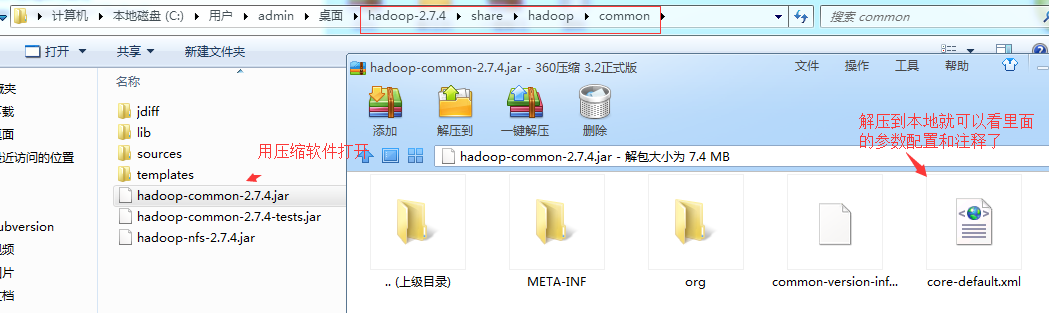
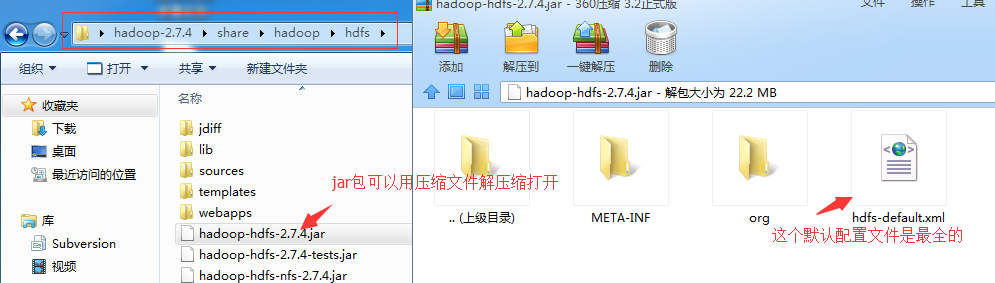
#按照上面的方式,不仅可以得到最全最新跟安装包匹配的配置参数,而且注释也较为详细点,有兴趣可以解压出来都看一看。
博文来自:www.51niux.com
hdfs-site.xml文件的配置:
# vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml #hdfs的配置
<configuration> <!--property> #这是另一种注释方式在这里展示一下 <name>dfs.namenode.secondary.http-address</name> <value>smaster.hadoop:9001</value> </property--> <property> <name>dfs.namenode.name.dir</name> #namenode元数据的存储目录,多个可以以逗号隔开,这样第二个目录可以采取远程挂载,DRBD等形式保证服务器出现问题,至少还有一份完整的元数据 <value>file:/home/hadoop/dfs/name,file:/home/hadoop/dfs/name1</value> </property> <property> <name>dfs.datanode.data.dir</name> #data node的数据目录,以,号隔开,hdfs会把数据存在这些目录下,一般这些目录是不同的块设备,不存在的目录会被忽略掉 <value>file:/data01,file:/data02,file:/data03,file:/data04,file:/data05,file:/data06,file:/data07,file:/data08,file:/data09,file:/data10</value> </property> <property> <name>dfs.replication</name> #默认的块复制。在创建文件时,可以指定复制的实际数量。默认值是3.当然如果想多空出点空间存储更多的东西可将副本数改为2. <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> #namenode的hdfs-site.xml是必须将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的 LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的。 <value>true</value> </property> <property> <name>dfs.block.size</name> #这个就是hdfs里一个文件块的大小了,默认128M,也就是134217728。块太大的话会有较少map同时计算,太小的话也浪费可用map个数资源,而且文件太小namenode就浪费内存多。根据需要进行设置。 <value>67108864</value> </property> <property> <name>dfs.balance.bandwidthPerSec</name> <value>104857600</value> </property> #这里默认是1MB/S,所以要根据自己的生产场景调大这个值。比如你新增节点了或者datanode节点间的空间占用差距过大了就要用到balance均衡来调节一下了。 #HDFS 平衡器检测集群中使用过度或者使用不足的DataNode,并在这些DataNode之间移动数据块来保证负载均衡。如果不对平衡操作进行带宽限制,那么 它会很快就会抢占所有的网络资源,不会为Mapreduce作业或者数据输入预留资源。 #参数dfs.balance.bandwidthPerSec定义 了每个DataNode平衡操作所允许的最大使用带宽,这个值的单位是byte,这是很不直观的,因为网络带宽一般都是用bit来描述的。因此,在设置的 时候,要先计算好。 #DataNode使用这个参数来控制网络带宽的使用,但不幸的是,这个参数在守护进程启动的时候就读入,导致管理员没办法在平衡运行时 来修改这个值。 <property> <name>dfs.namenode.secondary.http-address</name> <value> smaster.hadoop:9001</value> </property> </configuration>
mapred-site.xml文件配置:
# vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml #mapre的局部配置
<configuration>
<property>
<name>mapreduce.framework.name</name> #表示执行mapreduce任务所使用的运行框架,默认为local,需要将其改为yarn
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
#上面的参数是在mapred-site.xml文件中进行配置,mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address默认的值分别是0.0.0.0:10020和0.0.0.0:19888,
#大家可以根据自己的情况进行相应的配置,参数的格式是host:port。配置完上述的参数之后,重新启动Hadoop jobhistory,这样我们就可以在mapreduce.jobhistory.webapp.address参数配置的主机上对Hadoop历史作业情况经行查看。
<property>
<name>mapred.child.env</name> #指定mapreduce的task子进程启动时加载第三方jars,而不是让所有的hadoop子进程都加载
<value>LD_LIBRARY_PATH =/usr/local/lzo-2.06/lib </value>
</property>
<property>
<name>mapreduce.map.output.compress</name> #map输出是否进行压缩,如果压缩就会多耗cpu,但是减少传输时间,如果不压缩,就需要较多的传输带宽。默认值是false.
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name> #用那种压缩格式压缩
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name> #job输出结果压缩类型,如果你要将序列文件做为输出,你需要设置mapred.output.compression.type属性来指定压缩类型,默认是RECORD类型,它会按单个的record压缩,如果指定为BLOCK类型,它将一组record压缩,压缩效果自然是BLOCK好
<value>BLOCK</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name> #启用job输出压缩
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name> #指定压缩器,每种压缩对应一个压缩器
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name> #默认1024
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name> #默认1024
<value>2048</value>
</property>
#上面这两个参数指定用于MapReduce的两个任务(Map and Reduce task)的内存大小,其值应该在RM中的最大最小container之间。如果没有配置则通过如下简单公式获得:max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
#一般的reduce应该是map的2倍。注:这两个值可以在应用启动时通过参数改变;
<property>
<name>mapreduce.jobhistory.done-dir</name> #是在什么目录下存放已经运行完的Hadoop作业记录;默认值:${yarn.app.mapreduce.am.staging-dir}/history/done
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name> #正在运行的Hadoop作业记录,默认值:${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
<value>/history/done_intermediate</value>
</property>
<property>
<name>mapreduce.map.java.opts</name> #启动JVM虚拟机时,传递给虚拟机的启动参数,而默认值 -Xmx200m表示Map任务JVM的堆空间大小,一旦超过这个大小,JVM 就会抛出 Out of Memory 异常,并终止进程。
<value>-Xmx1024m</value> #mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb
</property>
<property>
<name>mapreduce.reduce.java.opts</name> #mapreduce.reduce.java.opts同mapreduce.map.java.opts一样的道理
<value>-Xmx1024m</value>
</property>
</configuration>粘贴一些链接记录一下:
https://www.iteblog.com/archives/981.html
http://www.cnblogs.com/sunxucool/p/4459006.html
yarn-site.xml文件配置:
# vim /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
#NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序(配置yarn.nodemanager.aux-services 一定要小心,hadoop2.2.0对应的value值已经从mapreduce.shuffle改为了mapreduce_shuffle)
<property>
<name>yarn.resourcemanager.address</name> #ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。默认值:${yarn.resourcemanager.hostname}:8032
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name> #ResourceManager 对 ApplicationMaster 暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。
<value>master.hadoop:8030</value> #默认值是:${yarn.resourcemanager.hostname}:8030
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name> #ResourceManager 对 NodeManager 暴露的地址.。NodeManager 通过该地址向 RM 汇报心跳,领取任务等
<value>master.hadoop:8031</value> #默认值是:${yarn.resourcemanager.hostname}:8031
</property>
<property>
<name>yarn.resourcemanager.admin.address</name> #ResourceManager 对管理员暴露的访问地址。管理员通过该地址向 RM 发送管理命令等。
<value>master.hadoop:8033</value> #${yarn.resourcemanager.hostname}:8033
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name> #ResourceManager 对外 web ui 地址。RM Web应用程序的http地址。 如果只提供一个主机作为值,webapp将在随机端口上提供。用户可通过该地址在浏览器中查看集群各类信息
<value>master.hadoop:8088</value> #默认值是:${yarn.resourcemanager.hostname}:8088
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name> #NodeManager 总的可用物理内存。注意,该参数是不可修改的,一旦设置,整个运行过程中不 可动态修改。
<value>57344</value> #物理内存量(MB),可以分配给容器。 如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true,则会自动计算(在Windows和Linux的情况下)。 在其他情况下,默认值为8192MB。
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>57344</value>
</property>
#单个任务可申请的最多物理内存量,默认是8192(MB)。RM中每个容器请求的最大分配以MB为单位。 高于此的内存请求将抛出InvalidResourceRequestException异常。
#默认情况下,YARN 采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于 Cgroups 对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报 OOM),
#而 Java 进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此 YARN 未提供 Cgroups 内存隔离机制。
<property>
<name>yarn.scheduler.minimum-allocation-mb</name> #RM中每个容器请求的最小配置为MB。 低于此值的内存请求将被设置为此属性的值。 此外,配置为具有比该值少的内存的节点管理器将被资源管理器关闭。
<value>512</value> #默认值是1024
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>20</value>
</property>
#可以为NodeManager分配的虚拟CPU数量。RM分配资源用于容器时使用。 这不是用来限制YARN容器使用的CPU数量。
#如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities是true的,则在Windows和Linux的情况下,它将从硬件自动确定。 在其他情况下,默认值为8。
<property>
</configuration>#我线上的datanode节点的配置都是24C,64G内存。
slaves文件的配置:
# vim /home/hadoop/hadoop/etc/hadoop/slaves #指定该集群的各个Slave节点的位置
slave01.hadoop slave02.hadoop slave03.hadoop slave04.hadoop
把配置好的hadoop目录拷贝到所有节点:
用hadoop用户将配置好的hadoop目录拷贝到其他节点上面去(如:scp -r hadoop-2.7.4 192.168.14.50:/home/hadoop/),当然如果早已经软件包已经安装到各节点了,直接拷贝conf目录就行了。
$ ln -s /home/hadoop/hadoop-2.7.4 /home/hadoop/hadoop
启动hadoop集群:
#su - hadoop
$ /home/hadoop/hadoop/bin/hadoop namenode -format #初始化镜像,不执行这步启动集群是要失败的。
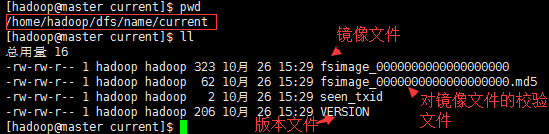
$ cat /home/hadoop/dfs/name/current/VERSION
#Thu Oct 26 15:29:26 CST 2017 namespaceID=1387077749 clusterID=CID-d7138891-ac1f-4ae5-9f9b-e37e60d57e1f cTime=0 storageType=NAME_NODE blockpoolID=BP-1166799008-192.168.14.49-1509002966357 layoutVersion=-63
$/home/hadoop/hadoop/sbin/start-all.sh #启动所有节点的服务
$ /home/hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver #打开历史服务器服务(哪个节点要打开监听端口就执行下这个命令,不执行默认是不起历史服务进行,不会有监听端口的。)
博文来自:www.51niux.com
集群状态查看:
#当然如果你开着所有窗口的话可以执行: tail -f /home/hadoop/hadoop/logs/* #查看有没有报错日志
http://192.168.14.49:50070 #可以直接url方式查看
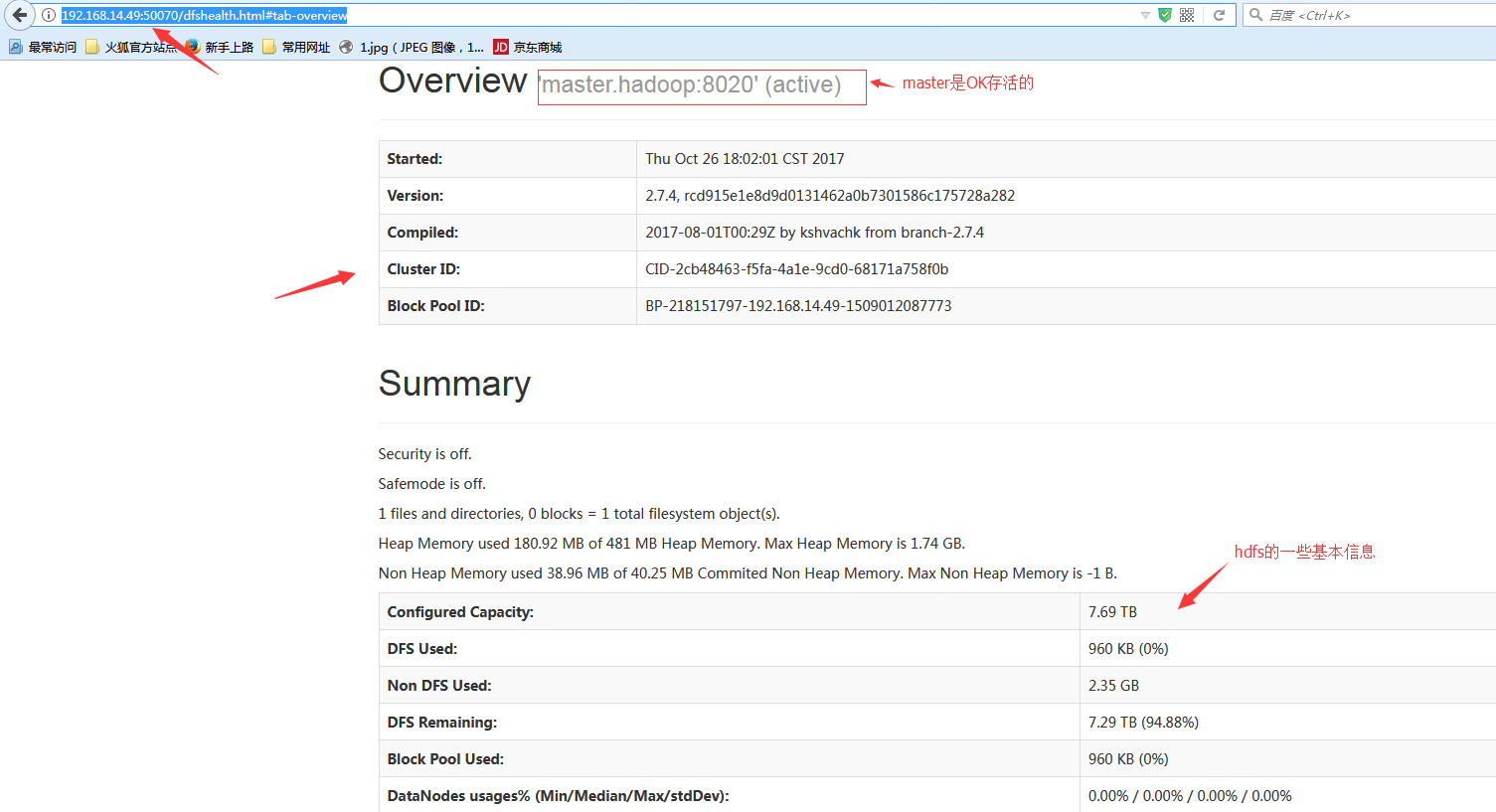
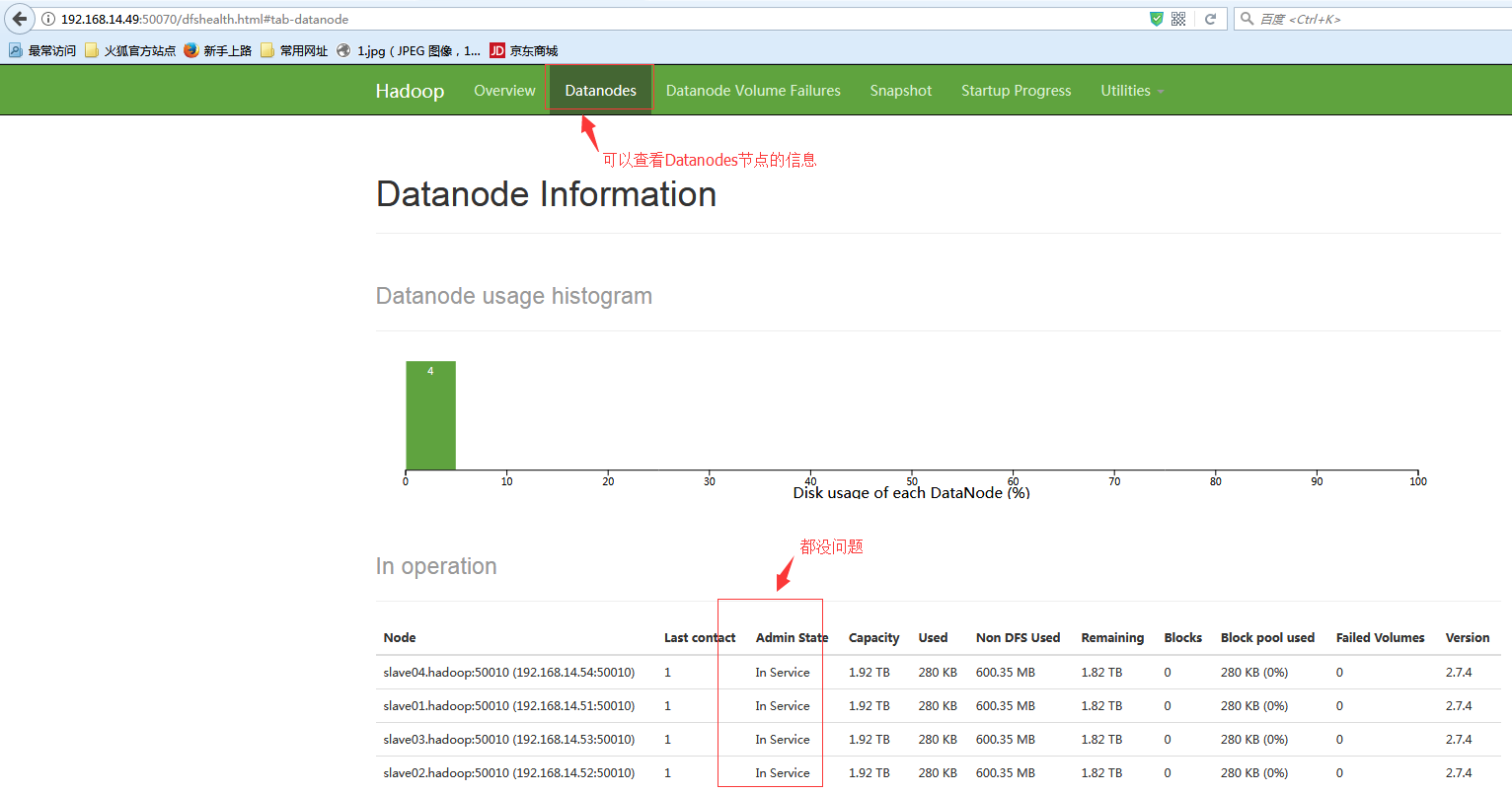
#我这测试环境是每个节点都是10块200G的虚拟磁盘
NN节点的查看:
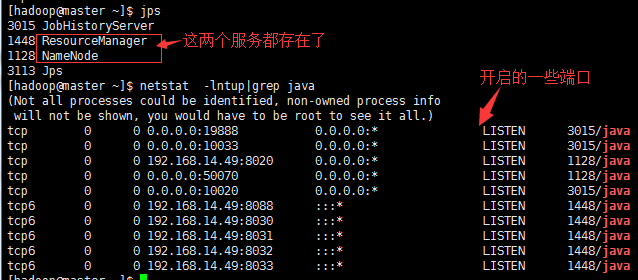
#端口 8033 #RM管理界面的地址。 8032 #RM中应用程序管理器接口的地址。 8031 #NodeManager通过该端口向RM汇报心跳,领取任务等 8030 #调度器端口,ApplicationMaster通过该地址向RM申请资源、释放资源等。 8088 #RM Web应用程序的http地址端口。 10020和19888 #jobhistory的端口 50070 #dfs namenode web ui侦听本端口。 8020 #HDFS文件系统的的URI和端口 10033 #历史服务器管理界面的地址端口。
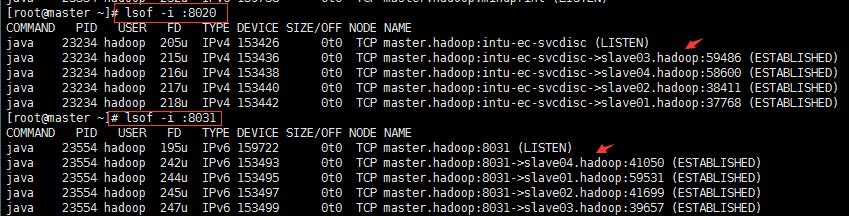
#上图是8031和8020的长连接状态,可见datanode节点是一直连接的。
SNN节点查看:

#端口 9001 #SNN节点的监听端口
DN节点查看:
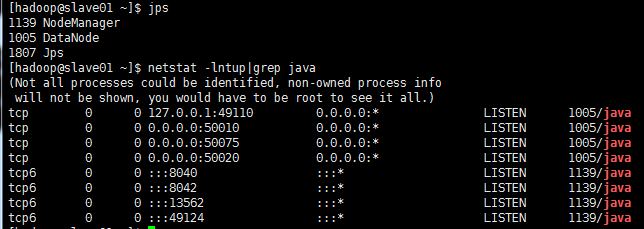
#端口 50010 #用于数据传输的datanode服务器地址和端口。 50075 #datanode的http服务器地址和端口. 50020 #datanode ipc服务器地址和端口。 8042 #NM Webapp地址。 8040 #Hadoop IPC端口
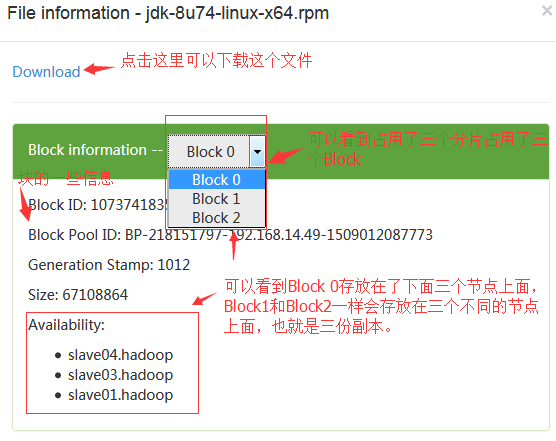
上传一个大文件查看文件切分状态:
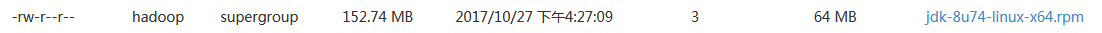
#这里上传了一个jdk文件上去,因为我们设置的是64MB的块大小,所以一个jdk文件应该切分成3个分片,然后3个副本,也就相当于占用9个block。
namenode内存全景请参考:
http://www.cnblogs.com/sky-sql/p/6849034.html
http://blog.csdn.net/guohecang/article/details/52356748
#另外hadoop与apache-mahout-distribution:http://lxw1234.com/archives/2015/08/432.htm ,mahout提供了一些经典的机器学习算法,用来做数据挖掘,是hadoop的高级用法,安装很简单,安装在namenode节点就行了。
Mahout的主要目标是建立针对大规模数据集可伸缩的机器学习算法,主要包括以下五个部分:
1)频繁模式挖掘:挖掘数据中频繁出现的项集; 2)聚类:将诸如文本、文档之类的数据分成局部相关的组; 3)分类:利用已经存在的分类文档训练分类器,对未分类的文档进行分类; 4)推荐引擎(协同过滤):获取用户的行为并从中发现用户可能喜欢的事务; 5)频繁子项挖掘:利用一个项集(查询记录或购物记录)去识别经常一起出现的项目。
