Kibana详细记录(九)
#基本全是翻译官网可略过。
一、开始
1.1 加载示例数据
提取文件:
$ wget https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
$ wget https://download.elastic.co/demos/kibana/gettingstarted/logs.jsonl.gz
$ wget https://download.elastic.co/demos/kibana/gettingstarted/shakespeare_6.0.json
$ unzip accounts.zip
$ gunzip logs.jsonl.gz
加载数据集:
$ curl -H 'Content-Type: application/x-ndjson' -XPOST '192.168.14.60:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
$ curl -H 'Content-Type: application/x-ndjson' -XPOST '192.168.14.60:9200/shakespeare/doc/_bulk?pretty' --data-binary @shakespeare_6.0.json
$ curl -H 'Content-Type: application/x-ndjson' -XPOST '192.168.14.60:9200/_bulk?pretty' --data-binary @logs.jsonl
#bulk的api:https://www.elastic.co/guide/en/elasticsearch/reference/6.0/docs-bulk.html
$ curl -H 'Content-Type: application/x-ndjson' -XGET '192.168.14.60:9200/_cat/indices?v'

1.2 定义你的索引模式
加载到Elasticsearch的每一组数据都有一个索引模式。帐户数据集有一个名为bank的索引。索引模式是带有可选通配符的字符串,可以匹配多个索引。例如,在公用日志记录用例中,一个典型的索引名称包含yyyy . mm中的日期。DD格式,可能看起来像logstash -2015.05 *的索引模式。在定义索引模式时,与Elasticsearch匹配的索引必须存在于Elasticsearch中。 这些指数必须包含数据。
1.3 发现数据
点击侧面导航中的Discover以显示Kibana的数据发现功能。在查询栏中,可以输入Elasticsearch查询来搜索数据。 可以在“Discover”中浏览结果,并在“Visualize”中创建已保存搜索的可视化。
当前索引模式显示在查询栏下方。 索引模式确定提交查询时搜索哪些索引。 要搜索一组不同的索引,请从下拉菜单中选择不同的模式。 要添加索引模式,请转至Management/Kibana/Index,然后单击添加新的索引。可以使用字段名称和感兴趣的值构建搜索。对于数字字段,可以使用比较运算符,如大于(>),小于(<)或等于(=)。 可以将逻辑运算符AND,OR和NOT与元素进行链接,全部使用大写字母。要试用它,请选择ba *索引模式并在查询栏中输入以下查询字符串:
account_number:<100 AND balance:>47500
#这个查询返回0到99之间的所有帐户号码,余额超过47,500。在搜索示例银行数据时,它返回5个结果:帐户号8、32、78、85和97。

#默认情况下,每个匹配文档都显示所有字段。 要选择要显示的文档字段,请将鼠标悬停在“account_number”列表上,然后单击要包含的每个字段旁边的添加按钮。 例如,如果只添加account_number,则显示将更改为五个帐号的简单列表:
1.4 可视化数据
要开始可视化数据,请单击侧面导航栏中的“Visualize”。可视化工具使您能够以多种方式查看您的数据。 例如,让我们使用古老的可视化(饼图)来了解样本银行账户数据中的账户余额。 要开始使用,请点击屏幕中央的大蓝色创建可视化按钮。
有许多可视化类型可供选择。 我们点击一个叫做Pie的。
可以从保存的搜索中构建可视化文件,也可以输入新的搜索条件。 要输入新的搜索条件,首先需要选择一个索引模式来指定要搜索的索引。 我们要搜索账户数据,所以选择ba *索引模式。默认搜索匹配所有文档。 最初,一个“切片”包含整个饼图。
要指定要在图表中显示的切片,请使用Elasticsearch存储桶聚合。 分组汇总只是将符合搜索条件的文档分类到不同的分类中,也称为分组。 例如,账户数据包括每个账户的余额。 使用存储桶聚合,您可以建立多个帐户余额范围,并找出有多少个帐户落入每个范围。为每个范围定义一个桶:
单击Split Slices (分片切片)桶类型。 从“Aggregation”列表中选择“Range”。 从Field 列表中选择balance 字段。 单击Add Range四次以使总数范围为six。 定义以下范围: 0 999 1000 2999 3000 6999 7000 14999 15000 30999 31000 50000
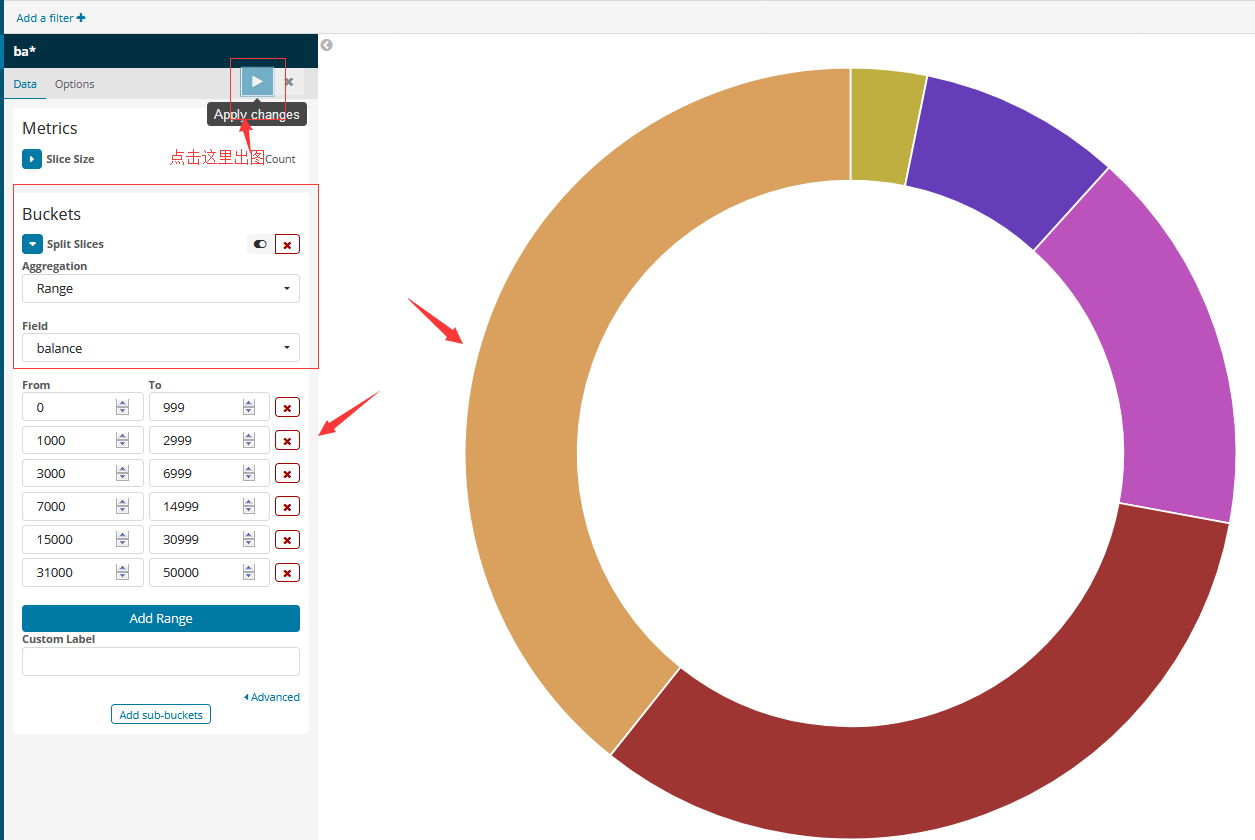
让我们来看看数据的另一个维度:账户持有人的年龄。通过添加另一个bucket聚合,可以看到每个平衡范围内帐户持有人的年龄:
Add sub-buckets列表下的Add子桶。 单击bucket类型列表中的Split Slices。 从聚合列表中选择Terms 。 从字段列表中选择age。 单击 Apply changes。
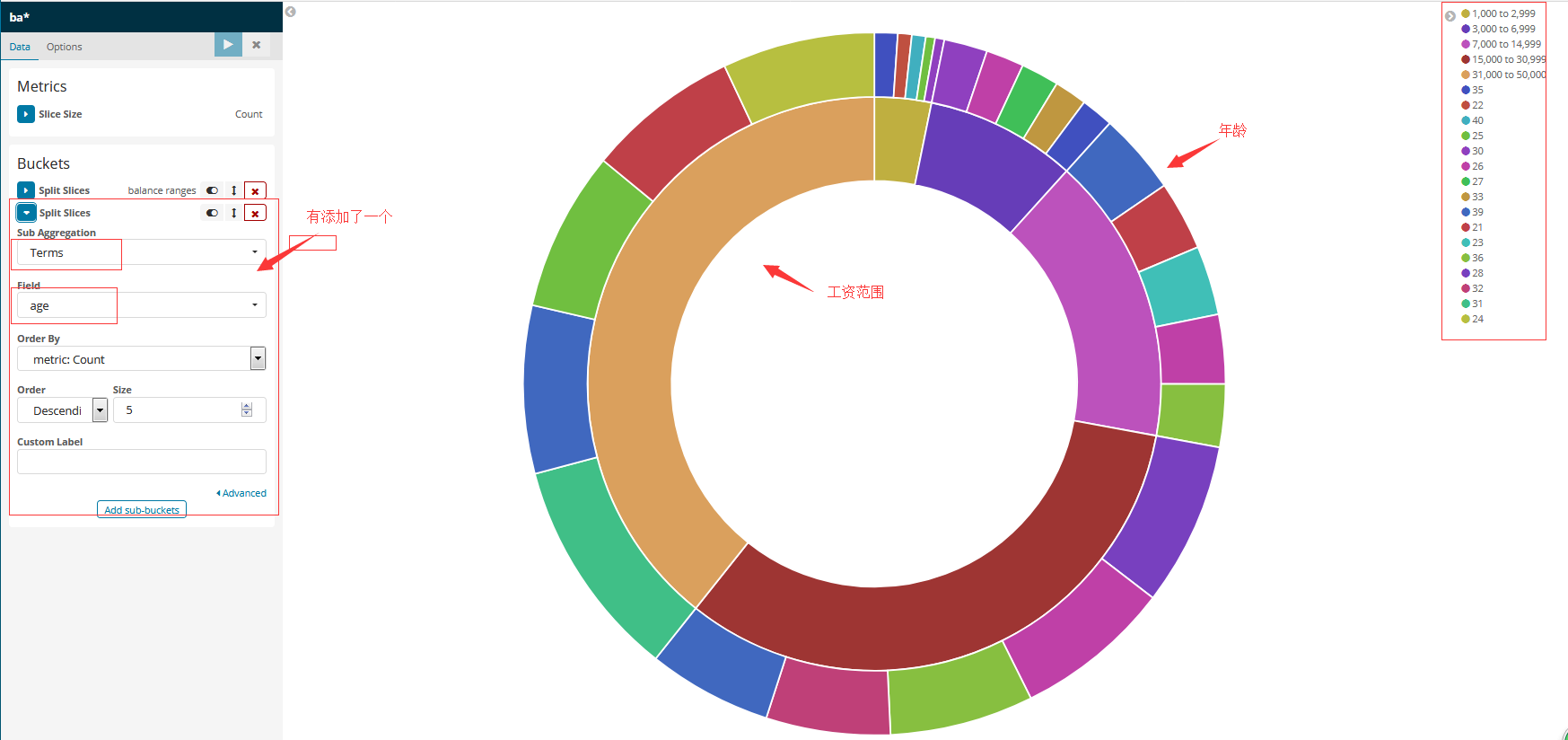
#要保存此图表以便稍后使用,请单击“Save”并输入名称“Pie Example”。
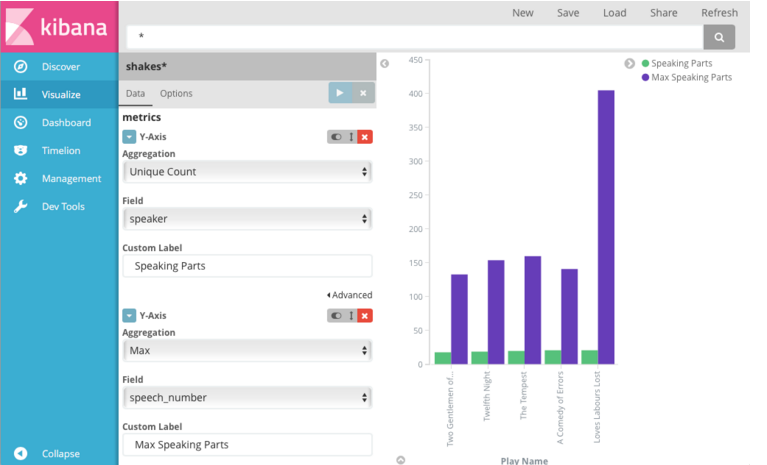
接下来,我们将看看Shakespeare集中的数据。 来看看当comes to的数量如何比较,并在条形图中显示信息:
单击New并选择Vertical bar chart。 选择shakes*索引模式。由于还没有定义任何bucket,因此您将看到一个大的bar,它显示了与默认通配符查询匹配的文档总数。 为了显示在y轴上每个play speaking parts per的数量,需要配置y轴度量聚合。度量聚合基于从搜索结果中提取的值计算度量。为了获得每个 play的speaking 部分的数量,选择Unique Count 聚合,并从字段列表中选择speaker。也可以给axis一个自定义的标签,speaking 的部分。 要显示长x轴的不同plays,请选择X轴桶类型,从聚合列表中选择Terms ,然后从字段列表中选择play_name。 要按字母顺序列出,请选择 Ascending order.也可以给该轴一个自定义标签,Play Name。 点击Apply查看结果。
接下来,我们将使用坐标映射图来显示日志文件示例数据中的地理信息。
点击New。 选择Coordinate map。 选择logstash- *索引模式。 为我们正在探索的事件设置时间窗口: 单击Kibana工具栏中的时间选择器。 点击Absolute。 将开始时间设置为2015年5月18日,结束时间为2015年5月20日。
#https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html
1.5 把它与仪表板结合在一起
仪表板是可以安排和共享的可视化集合。
点击侧面导航中的Dashboard。 单击Add以显示保存的可视化列表。 单击Markdown Example, Pie Example, Bar Example, and Map Example,然后通过单击列表底部的小向上箭头关闭可视化列表。
将鼠标悬停在可视化对象上将显示容器控件,使您可以编辑,移动,删除和调整可视化对象的大小。示例仪表板应该最终看起来像这样:
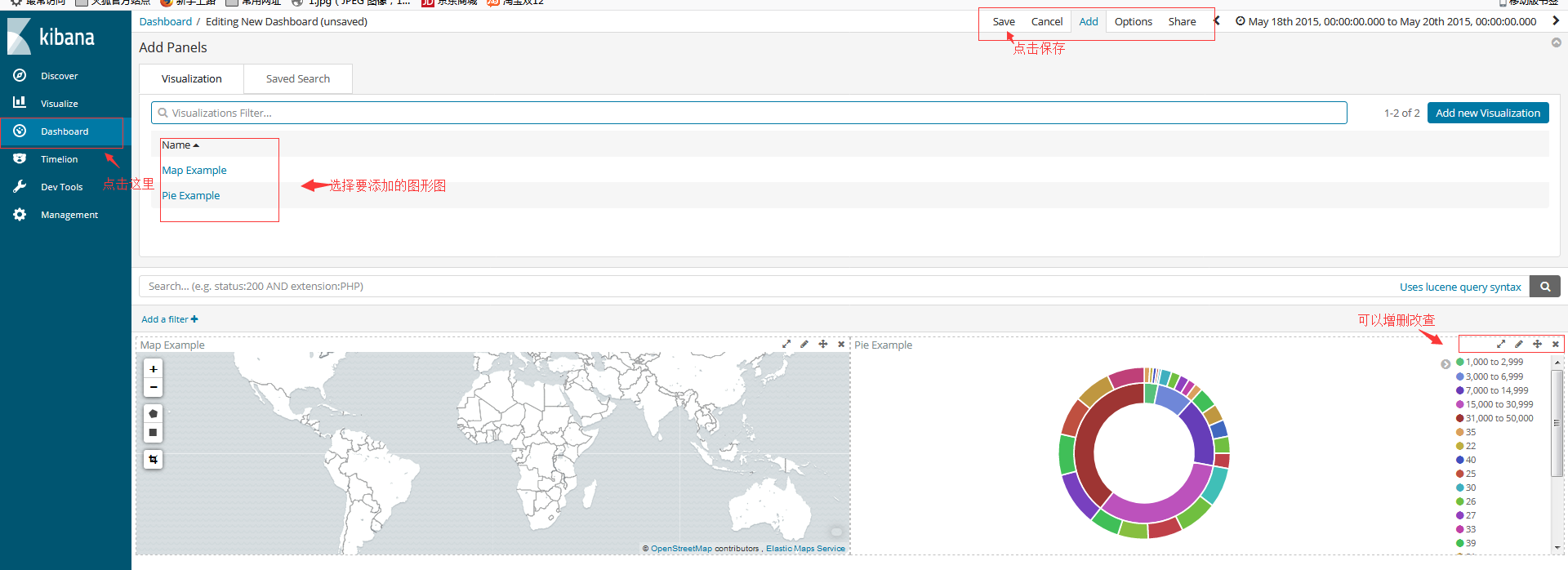
要获取共享链接或HTML代码以将仪表板嵌入到网页中,请保存仪表板并单击Share。
博文来自:www.51niux.com
二、发现
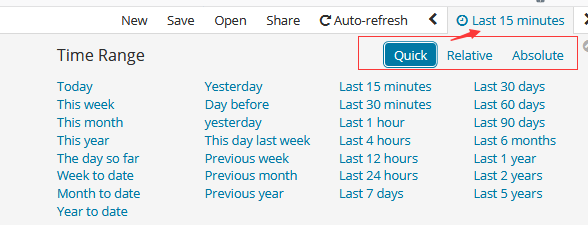
2.1 设置时间过滤器
时间过滤器将搜索结果限制在特定时间段。 如果您的索引包含基于时间的事件并且为所选索引模式配置了时间字段,则可以设置时间过滤器。
默认情况下,时间过滤器设置为最后15分钟。 您可以使用时间选取器更改时间过滤器,或在页面顶部的直方图中选择特定的时间间隔或时间范围。
使用时间选取器设置时间过滤器:
2.2 搜索数据
Lucene查询语法
要执行自由文本搜索,只需输入一个文本字符串。 例如,如果您正在搜索Web服务器日志,则可以进入Safari浏览器来搜索Safari字词的所有字段。 要在特定字段中搜索值,请使用该字段的名称前缀该值。 例如,您可以输入status:200来查找状态字段中包含值200的所有条目。 要搜索一系列值,可以使用括号内的范围语法[START_VALUE TO END_VALUE]。 例如,要查找具有4xx状态码的条目,可以输入状态:[400 TO 499]。 要指定更复杂的搜索条件,可以使用布尔运算符AND,OR和NOT。 例如,要查找具有4xx状态代码并具有php或html扩展名的条目,可以输入状态:[400 TO 499] AND(extension:php OR extension:html)。 有关Lucene查询语法的更多详细信息,请参阅查询字符串查询文档。
这些示例使用Lucene查询语法。 当选择lucene作为查询语言时,您也可以使用Elasticsearch Query DSL提交查询。
Kuery
Kuery是专门为Kibana打造的一种新的查询语言。 它旨在简化Kibana中的搜索体验,并创建有用的功能,如自动完成,已保存搜索的无缝迁移,其他查询类型等。 库里是今天的基本体验,但我们正努力在库里提供的基础之上构建这些附加功能。
https://www.elastic.co/guide/en/kibana/current/kuery-query.html
保存和打开搜索
保存搜索使您可以将其重新加载到Discover中,并将其用作可视化的基础。 保存搜索同时保存搜索查询字符串和当前选择的索引模式。
要保存当前搜索:

您可以从Management/Kibana/Saved Objects导入,导出和删除保存的搜索。
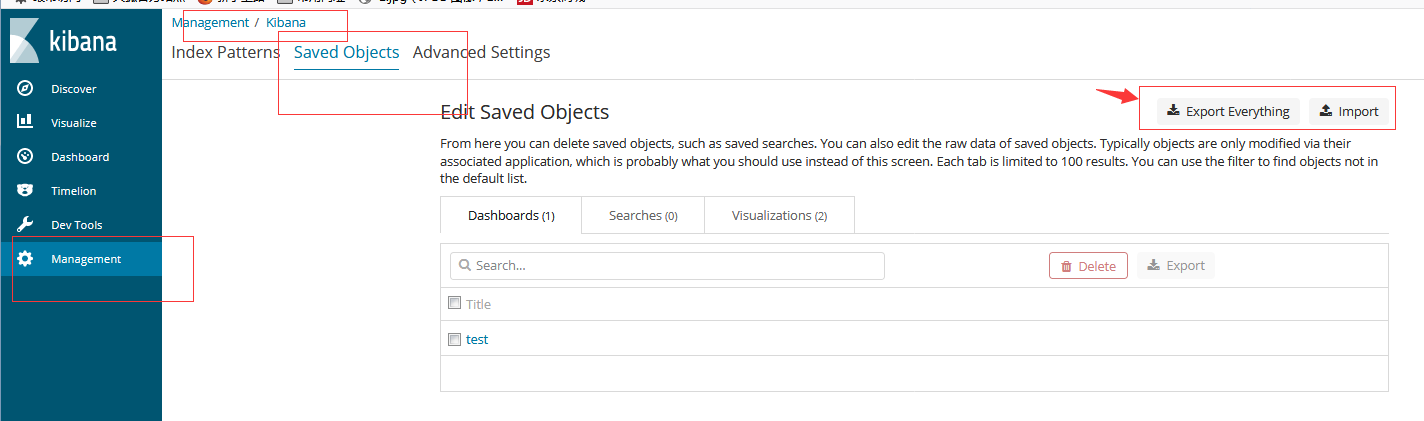
将保存的搜索加载到Discover:
单击Kibana工具栏上的打开。 选择您想要打开的搜索。
如果保存的搜索与当前选定的索引模式不同,则打开保存的搜索会更改所选的索引模式。 用于保存的搜索的查询语言也将被自动选择。

当您提交一个搜索请求时,搜索与当前选择的索引模式匹配的索引。当前的索引模式显示在工具栏下面。要更改您正在搜索的索引,请单击index模式并选择一个不同的索引模式。https://www.elastic.co/guide/en/kibana/current/index-patterns.html#settings-create-pattern
刷新搜索结果
随着更多文档被添加到您正在搜索的索引中,Discover中显示的用于显示可视化的搜索结果将变得过时。 您可以配置刷新间隔以定期重新提交搜索以检索最新结果。
启用自动刷新:

启用自动刷新时,刷新时间间隔显示在时间选择器旁边,同时显示一个暂停按钮。 要暂时禁用自动刷新,请单击Pause。
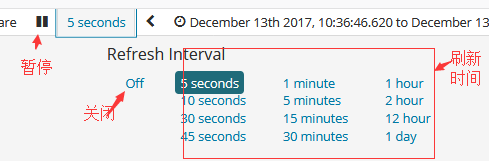
如果未启用自动刷新,则可以通过单击Refresh来手动刷新可视化。
2.3 按字段筛选
可以过滤搜索结果以仅显示在字段中包含特定值的文档。 您还可以创建排除包含指定字段值的文档的否定过滤器。可以从“Fields”列表,“Documents”表中添加字段过滤器,也可以手动添加过滤器。 除了创建正面和负面的过滤器之外,“Fields”表还允许您过滤是否存在字段。 查询栏下面显示了应用的过滤器。 负滤镜显示为红色。从“Fields”列表添加过滤器:
点击您要过滤的字段的名称。 这将显示该字段的前五个值。
要添加正过滤器,请单击“正过滤器”按钮“正过滤器”。 这仅包括那些在该字段中包含该值的文档。
要添加否定过滤器,请单击“否定过滤器”按钮负过滤器。 这不包括在该字段中包含该值的文档。
从“Documents”表添加过滤器:
单击文档表格条目左侧的“展开”按钮展开按钮,展开“document”表格中的文档。
要添加正过滤器,请单击字段名称右侧的“正过滤器”按钮“正过滤器”按钮。 这仅包括那些在该字段中包含该值的文档。
要添加否定过滤器,请单击字段名称右侧的负过滤器按钮负过滤器按钮。 这不包括在该字段中包含该值的文档。
要过滤文档是否包含该字段,请单击字段名称右侧的Exists按钮*按钮。 这只包含那些包含该字段的文档。
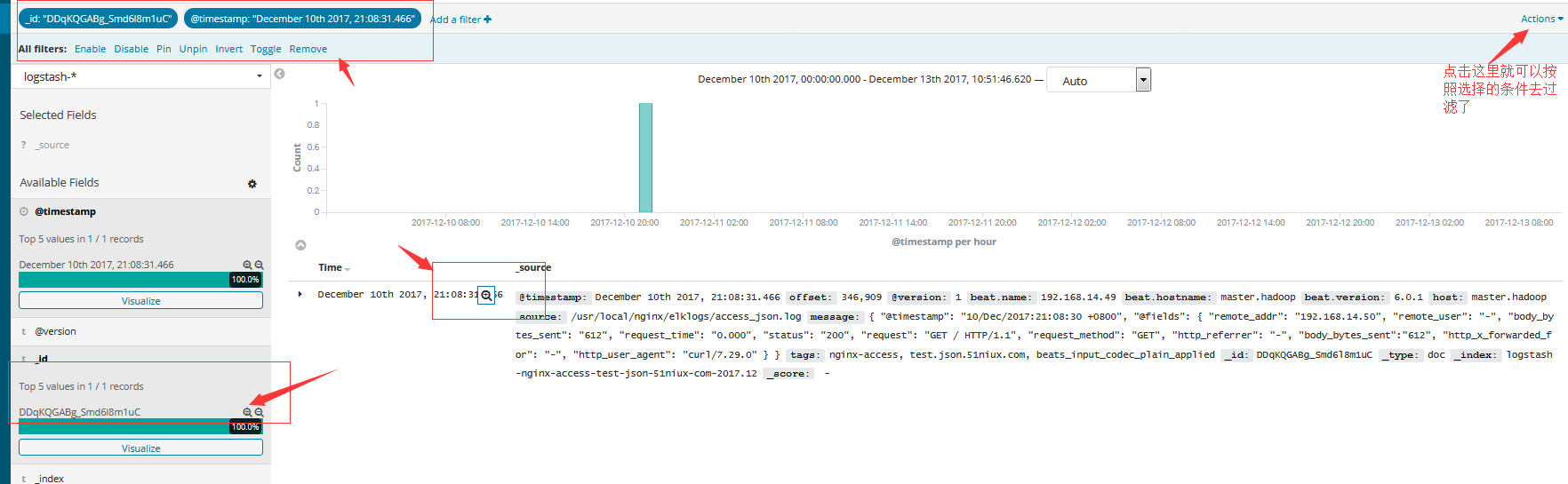
要手动添加过滤器:
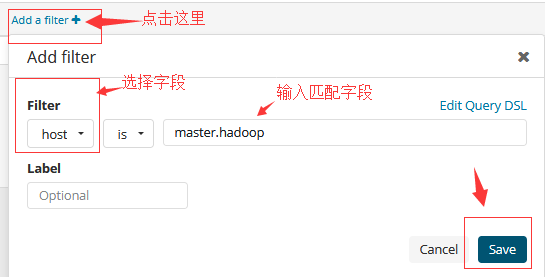
点击添加Add Filter。 弹出窗口将显示给您创建过滤器。
选择要过滤的字段。 这个字段列表将包括您正在查询的索引模式的字段。
为您的过滤器选择一项操作。可以选择以下操作符:
is #过滤该字段的值与给定值匹配的位置。 is not #过滤该字段的值与给定值不匹配的位置。 is one of #过滤该字段的值与指定值之一匹配的位置。 is not one of #过滤该字段的值与指定的任何值不匹配的位置。 is between #过滤该字段的值在给定范围内的位置。 is not between #过滤该字段的值不在给定范围内的位置。 exists #过滤该字段的任何值。 does not exist #过滤该字段中没有值的地方。
选择您的过滤器的值。 如果您针对可聚合字段进行过滤,则可能会将您的索引值指定为选项。
(可选)为过滤器指定一个标签。 如果您指定一个标签,它将显示在查询栏下方而不是过滤器定义。
点击Save。 该过滤器将应用于您的搜索并显示在查询栏下方。
如果由于值建议而遇到长时间运行的查询,则可以通过将高级设置filterEditor:suggestValues设置为false来关闭建议。
 #从左至右依旧是
#从左至右依旧是
Enable Filter #禁用筛选器而不删除它。 再次点击重新启用过滤器。 斜条纹表示禁用了过滤器。 Pin Filter #固定过滤器。 在Kibana中切换上下文时,固定的过滤器保持不变。 例如,您可以在“发现”中固定一个过滤器,并在切换到“可视化”时保持原样。 请注意,过滤器基于特定的索引字段,如果搜索的索引不包含固定过滤器中的字段,则不起作用。 Invert Filter #从正滤镜切换到负滤镜,反之亦然。 Remove Filter #删除过滤器。 Edit Filter #编辑过滤器定义。 使您能够手动更新过滤器并指定过滤器的标签。
要将筛选器操作应用于所有应用的筛选器,请单击“Actions”并选择操作。

启用 禁用 固定 取消固定 倒置 切换 去掉
2.4 查看文档数据
提交搜索查询时,与“查询”匹配的500个最新文档将在“文档”表中列出。 您可以通过在“高级设置”中设置discover:sampleSize属性来配置表中显示的文档数量。 默认情况下,该表显示为所选索引模式和文档_source配置的时间字段的本地化版本。 您可以从“字段”列表中将字段添加到“文档”表中。 您可以通过表中包含的任何索引字段对列出的文档进行排序。
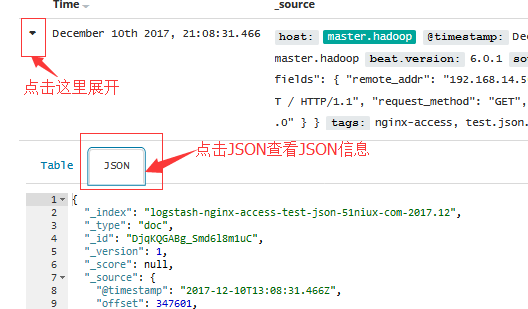
要查看文档的字段数据,请单击文档的表格条目左侧的“展开”按钮“展开”按钮。
要查看原始JSON文档(pretty-printed),请单击JSON选项卡。
要将文档数据作为单独页面查看,请单击“查看单个文档”链接。 您可以收藏并共享此链接,以便直接访问特定的文档。
要显示或隐藏“文档”表中的字段列,请单击表格按钮中的“添加列切换”列。
要折叠文档详细信息,请单击“折叠”按钮“折叠”按钮。
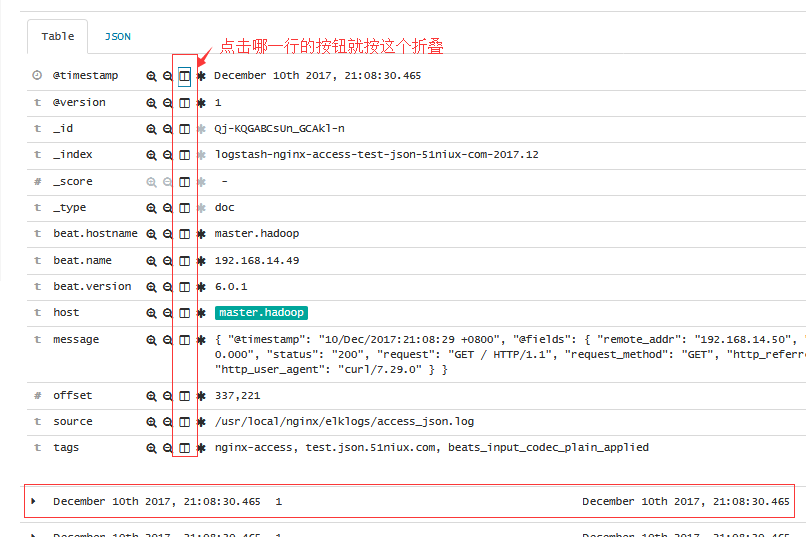

您可以使用任何索引字段中的值对“文档”表中的文档进行排序。 如果为当前索引模式配置了时间字段,则默认情况下按照时间顺序排序文档。要更改排序顺序,请将鼠标悬停在要排序的字段名称上,然后单击排序按钮。 再次单击以反转排序顺序。
默认情况下,“表”显示为所选索引模式和文档_source配置的时间字段的本地化版本。 您可以从“字段”列表或文档的字段数据向表中添加字段。要从“字段”列表添加字段列,请将鼠标悬停在字段上并单击其add按钮。要从文档的字段数据添加字段列,Toggle column in table,然后单击表格按钮中字段的“添加列切换”列。添加的字段列替换“文档”表中的_source列。 添加的字段也被添加到Selected Fields列表中。要重新排列字段列,请将鼠标悬停在要移动的列的标题上,然后单击Move left or Move right按钮。
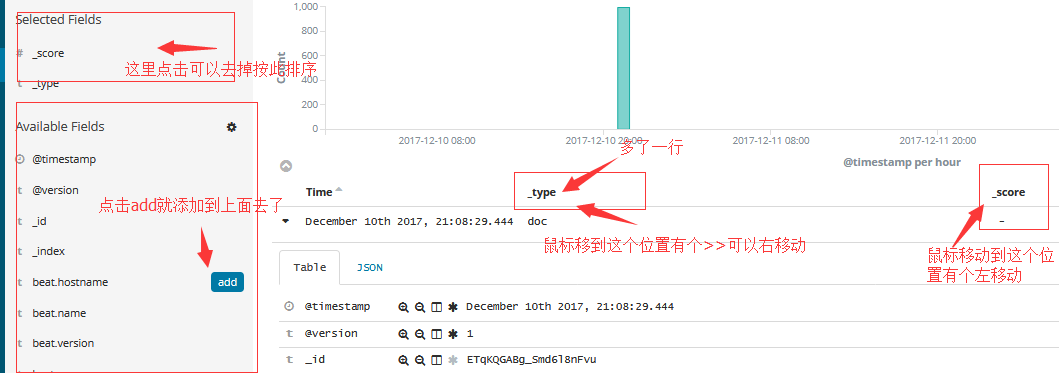
要从“文档”表中删除字段列,请将鼠标悬停在要删除的列的标题上,然后单击“叉号”按钮删除字段按钮。
2.5 查看文档上下文
对于某些应用程序来说,查看围绕特定事件的文档窗口可能很有用。 上下文视图使您可以为配置为包含基于时间的事件的索引模式做到这一点。就是那个View surrounding documents按钮。
要显示锚文档周围的上下文,请单击展开按钮在文档的表格条目左侧,然后单击View surrounding documents链接。
虽然不是必需的,但建议只使用启用了doc值的字段来实现良好的性能,并避免不必要的现场数据使用。 适合的领域的常见例子包括登录行号,单调递增计数器和高精度时间戳。
他默认显示的文档数量可以通过Management > Advanced Settings的context:defaultSize设置。
2.6 过滤上下文
根据文档如何分区为索引模式,上下文视图可能包含大量与正在调查的事件无关的文档。 为了使上下文视图的焦点适应当前的任务,可以使用过滤器来限制Kibana在上下文视图中显示的文档。
当从发现视图切换到上下文视图时,先前应用的过滤器被结转。 固定过滤器在禁用状态下被复制时保持活动状态。 您可以选择性地重新启用它们以优化您的上下文视图。
2.7 查看现场数据统计
从“字段”列表中,可以看到“文档”表中有多少个文档包含特定的字段,前5个值是多少以及文档中包含每个值的百分比。要查看字段数据统计信息,请单击“字段”列表中字段的名称。

博文来自:www.51niux.com
三、可视化
Visualize使您能够在Elasticsearch索引中创建数据的可视化。 然后,您可以构建显示相关可视化的仪表盘。Kibana可视化基于Elasticsearch查询。 通过使用一系列Elasticsearch聚合来提取和处理您的数据,您可以创建图表来显示您需要了解的趋势,尖峰和淹没。您可以通过从“Discover”保存的搜索创建可视化,或者从新的搜索查询开始。
3.1 创建可视化
要创建一个可视化:
点击侧面导航中的可视化。
点击创建新的可视化按钮或+按钮。
选择可视化类型:
Basic charts(基本图标):
Line, Area and Bar charts #比较X / Y图表中的不同系列。 Heat maps #矩阵内的阴影细胞。 Pie chart #显示每个来源的贡献总数。
Data(数据):
Data table #显示合成聚合的原始数据。 Metric #显示一个号码。 Goal and Gauge #显示一个表
Maps(地图):
Coordinate map #将聚合的结果与地理位置相关联。 Region map #形状的颜色强度对应于度量值的专题图。位置。
Time Series(时间序列):
Timelion #计算和组合来自多个时间序列数据集的数据。 Time Series Visual Builder #使用流水线聚合来可视化时间序列数据。
Other:
Tag cloud #将单词显示为单词的大小对应于其重要性的云 Markdown widget #显示自由格式的信息或说明。
指定一个搜索查询来检索可视化的数据:
要输入新的搜索条件,请选择包含要显示的数据的索引的索引模式。 这将打开可视化构建器,其中包含与所选索引中的所有文档相匹配的通配符查询。 要从已保存的搜索中构建可视化文件,请单击要使用的已保存搜索的名称。 这将打开可视化构建器并加载所选查询。
#从保存的搜索中构建可视化文件时,对保存的搜索的任何后续修改都会自动反映到可视化文件中。 要禁用自动更新,可以从已保存的搜索中断开可视化。
在可视化构建器中,为可视化的Y轴选择度量标准聚合:
#度量聚合 count #计数 average #平均 sum #和 min #最小 max #最大 standard deviation #标准偏差 unique count #独特的计数 median (50th percentile) #中位数(第50百分位) percentiles #百分 percentile ranks #百分登记 top hit #点击top geo centroid #地理位置 #父级管道聚合: derivative #导数 cumulative sum #累计综合 moving average #移动平均线 serial diff #串行差异 #同级管道聚合: average bucket #平均水桶 sum bucket #总和通 min bucket #分钟桶 max bucket #最大桶
对于可视化X轴,选择一个桶聚合:
date histogram #日期直方图 range #范围 terms #条款 filters #过滤器 significant terms #重要条款
例如,如果您将Apache服务器日志编入索引,则可以通过在geo.src字段中指定术语聚合来构建条形图,以显示按地理位置分布的传入请求:
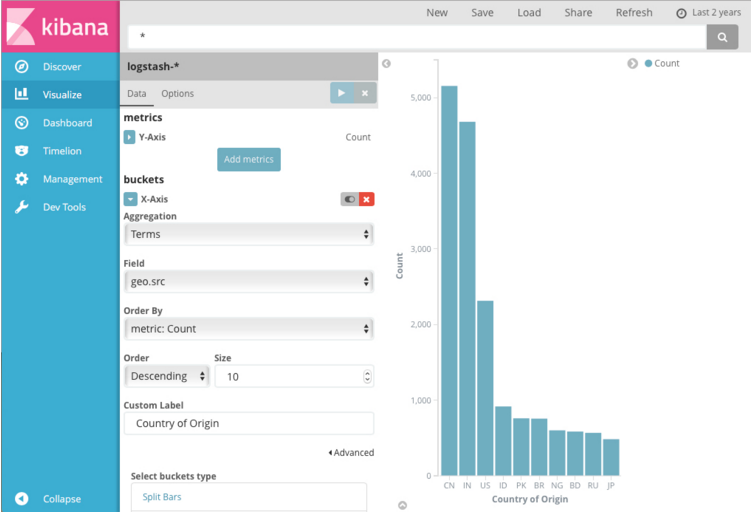
y轴显示从每个国家收到的请求数量,并且这些国家显示在x轴上。条形图,线条或面积图可视化使用y轴的度量标准和x轴的存储桶。 存储桶类似于SQL GROUP BY语句。 饼图,使用切片大小的度量标准和切片的数量使用桶。
您可以通过指定子聚合来进一步分解数据。 第一个聚合确定任何后续聚合的数据集。 子聚合按顺序应用 - 您可以拖动聚合以更改它们的应用顺序。
例如,您可以将geo.dest字段中的条款子聚合添加到原始国家/地区条形图中,以查看这些请求所针对的位置。
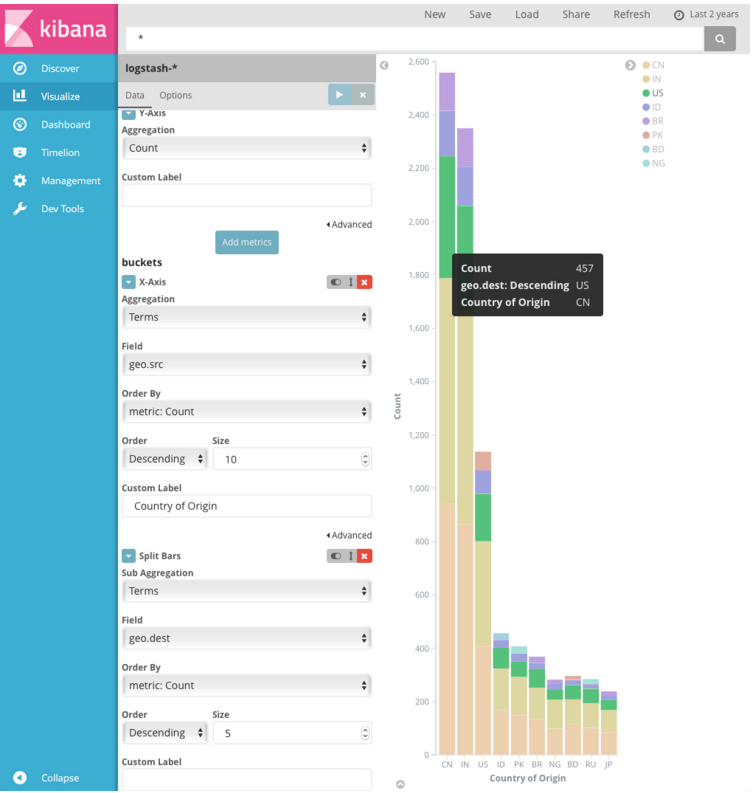
有关使用子聚合的更多信息,请参阅Kibana,聚合执行顺序和您。https://www.elastic.co/blog/kibana-aggregation-execution-order-and-you
3.2 Line, Area, and Bar charts(线,面积和条形图)
线,面积和条形图允许您在X / Y轴上绘制数据。首先,您需要选择定义值轴的度量。
度量聚合:
Count #计数聚合返回所选索引模式中元素的原始计数。 Average #此聚合返回数字字段的平均值。从下拉菜单中选择一个字段。 Sum #总和聚合返回数字字段的总和。从下拉菜单中选择一个字段。 Min #聚合返回数字字段的最小值。从下拉菜单中选择一个字段。 Max #最大聚合返回数字字段的最大值。从下拉菜单中选择一个字段。 Unique Count #基数聚合返回字段中唯一值的数量。从下拉菜单中选择一个字段。 Standard Deviation #扩展的stats聚合返回数字字段中数据的标准偏差。从下拉菜单中选择一个字段。 Percentiles #百分位聚合将数字字段中的值分成您指定的百分位数条带。 从下拉列表中选择一个字段,然后在“Percentiles”字段中指定一个或多个范围。 点击X删除百分位数字段。 点击+添加以添加百分比字段。 Percentile Rank #百分位数聚合返回您指定的数字字段中的值的百分位数。 从下拉列表中选择一个数字字段,然后在“值”字段中指定一个或多个百分比等级值。 单击X以删除值字段。 点击+添加以添加值字段。
Parent Pipeline Aggregations(父级管道聚合):
对于每个父管道聚合,必须定义计算聚合的度量。 这可能是现有的指标之一或新的指标。 你也可以嵌套这个聚合(例如产生三阶导数)
Derivative #派生聚合计算特定度量的派生。 Cumulative Sum #累计和汇总计算父直方图中指定度量的累计和 Moving Average #移动平均值聚合将滑动数据窗口并发出该窗口的平均值 Serial Diff #串行差分是一种技术,其中时间序列中的值在不同的时滞或周期内从自身中减去
Sibling Pipeline Aggregations(同级管道聚合):
就像使用父级管道聚合一样,您需要提供一个用于计算同级聚合的度量。 最重要的是,您还需要提供一个桶聚合,它将定义兄弟聚合将运行的桶
Average Bucket #平均桶计算同级聚合中指定度量的(均值)平均值 Sum Bucket #总和桶计算同级聚合中指定度量值的总和 Min Bucket #min分桶计算同级聚合中指定度量的最小值 Max Bucket #最大桶计算同级聚合中指定度量的最大值
可以通过单击+ Add Metrics 按钮来添加聚合。在Custom Label 字段中输入一个字符串来更改显示标签。
存储桶聚合确定从数据集中检索哪些信息。在选择存储桶聚合之前,请指定是在单个图表中拆分切片还是拆分为多个图表。 多个图表拆分必须在任何其他汇总之前运行。 在拆分图表时,可以通过单击“行”|来更改拆分显示在行或列中的情况 列选择器。这个图表的X轴是水平轴。 您可以为X轴,图表上的拆分区域或拆分图表定义存储区。该图表的X轴支持以下聚合。 单击每个聚合的链接名称以访问该聚合的主要Elasticsearch文档。
Date Histogram #日期直方图是从数字字段构建的,并按日期组织。 您可以以秒,分,小时,天,周,月或年为单位指定时间间隔。 您还可以通过选择“自定义”作为间隔并在文本字段中指定数字和时间单位来指定自定义间隔帧。 自定义间隔时间单位是秒为秒,m为分钟,h为小时,d为天,w为星期,y为年。 不同的单位支持不同级别的精度,下降到一秒钟。 间隔开始时使用Elasticsearch返回的日期键来标记时间间隔。 例如,每月间隔的工具提示将显示该月的第一天。 Histogram #标准直方图是从数字字段构建的。 为此字段指定一个整数间隔。 选择“Show empty buckets”复选框以在柱状图中包含空白区间。 Range #使用范围聚合,您可以为数字字段指定值的范围。 单击Add Range以添加一组范围端点。 点击红色(x)符号删除一个范围。 Date Range #日期范围聚合报告在您指定的日期范围内的值。 您可以使用日期数学表达式来指定日期的范围。 单击Add Range以添加一组范围端点。 点击红色(x)符号删除一个范围。 IPv4 Range #IPv4范围聚合使您能够指定IPv4地址的范围。 单击 Add Range 以添加一组范围端点。 点击红色(x)符号删除一个范围。 Terms #术语聚合使您可以指定要显示的给定字段的顶部或底部的n个元素,按数量或自定义度量标准进行排序。 Filters #您可以为数据指定一组过滤器。 您可以将过滤器指定为查询字符串或JSON格式,就像在发现搜索栏中一样。 点击Add Filter添加另一个过滤器。 单击“标签label ”按钮图标标签按钮以打开标签字段,您可以在其中输入要在图表上显示的名称。 Significant Terms #显示实验重要术语聚合的结果。
一旦您指定了X轴聚合,您可以定义子聚合来优化可视化。 单击+ Add Sub Aggregation来定义子聚合,然后选择Split Area or Split Chart(拆分区域或拆分图表),然后从类型列表中选择一个子聚合。
在图表轴上定义多个聚合时,可以使用聚合类型右侧的向上或向下箭头更改聚合的优先级。在自定义标签字段中输入一个字符串来更改显示标签。您可以通过单击每个标签旁边的颜色点来自定义可视化的颜色以显示颜色选择器。
在Custom Label 字段中输入一个字符串来更改显示标签。
您可以点击 Advanced 为您的指标或存储桶聚合显示更多自定义选项:
Exclude Pattern #在此字段中指定一个模式以从结果中排除。
Include Pattern #在此字段中指定一个模式以包含在结果中。
JSON Input #一个文本字段,您可以在其中添加特定的JSON格式的属性以与聚合定义进行合并,如:{ "script" : "doc['grade'].value * 1.2" }在Elasticsearch版本1.4.3及更高版本中,此功能要求您启用动态Groovy脚本。https://www.elastic.co/guide/en/elasticsearch/reference/6.0/modules-scripting.html
这些选项的可用性取决于您选择的聚合。
3.3 Metrics & Axes(指标和轴)
选择“指标和轴”选项卡可以更改图表上显示的每个指标的方式。 数据系列在“度量”部分中进行了样式设置,而轴在X和Y轴部分进行了样式设置。
Metrics:
修改数据面板中每个指标在图表上的可视化方式。
Chart type #在Area, Line, and Bar types之间选择 Mode #堆叠不同的指标,或将它们彼此相邻 Value Axis #选择要绘制这些数据的轴(每个轴的属性都在Y轴下进行配置)。 Line mode #线条或条纹的轮廓应该是平滑的,笔直的还是阶梯状的。
Y-axes:
设计图表的所有Y轴。
Position #Y轴的位置(垂直图的左侧或右侧,水平图的顶部或底部)。 Scale type #这些值的缩放(线性,对数或平方根) Advanced Options #Labels - Show Labels(允许您隐藏轴标签) Labels - Filter Labels(如果启用了过滤器标签,则在没有足够空间显示这些标签的情况下会隐藏一些标签) Labels - Rotate(您可以输入您想旋转标签的数量) #Labels - Truncate(您可以输入标签被截断的像素大小) Scale to Data Bounds(默认的Y轴边界是零,并且是数据中返回的最大值。 选中此框可更改上限和下限,以匹配数据中返回的值。) Custom Extents (您可以为每个轴定义自定义的最小值和最大值)
X-Axis:
Position #位置。X轴的位置(水平图表的左侧或右侧,垂直图表的顶部或底部)。 Advanced Options #高级选项。Labels - Show Labels(允许您隐藏轴标签) Labels - Filter Labels(如果过滤器标签被启用,一些标签将被隐藏以防没有足够的spave来显示它们) Labels - Rotate(您可以输入您想旋转标签的数量) Labels - Truncate(您可以输入标签被截断的像素大小)
面板设置:
这些选项适用于整个图表,而不仅仅是单个数据系列。
命令选项:
Legend Position #将图例移动到左侧,右侧,顶部或底部 Show Tooltip #启用或禁用悬停在统计图对象上的工具提示的显示 Current Time Marker #显示一条线表示当前时间
网格选项:
您可以在图表上启用网格。 默认情况下,网格仅显示在类别轴上。
X-axis #您可以禁用类别轴上的网格线显示 Y-axis #您可以选择想要显示网格线的值轴(如果有的话)
四、指示板
4.1 建立一个Dashboard
建立一个指示板:
点击侧面导航中的Dashboard。 如果您之前没有查看过仪表板,则Kibana会显示一个登录页面,您可以点击+。 否则,请点击仪表板导航栏导航回目标页面。
要向仪表板添加可视化文件,请单击Edit模式。 全新的仪表盘将自动处于Edit模式。
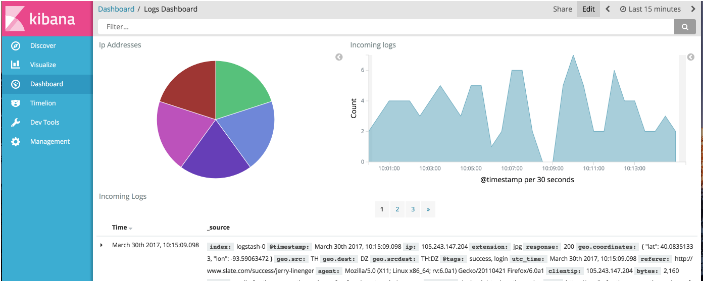
进入编辑模式后,点击Add,然后选择图表。 如果您有大量的可视化对象,则可以输入Filter字符串来过滤列表。
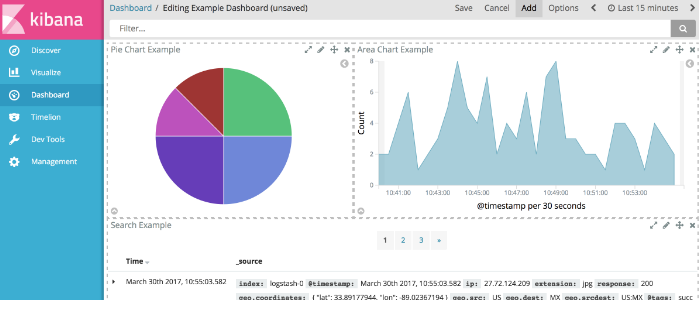
Kibana将所选可视化显示在仪表板的容器中。 如果看到容器太小的消息,则可以调整可视化的大小。
#默认情况下,Kibana仪表板使用浅色主题。 要使用深色主题,请单击选项,然后选择使用深色主题。 要更改默认主题,请转至Management/Kibana/Advanced Settings,并将控制板:defaultDarkTheme设置为true。
4. 完成添加和排列可视化对象后,单击保存以保存仪表板:
a. 在编辑模式中,仪表板中的可视化文件存储在可调整大小的可移动容器中。
b. 要使用仪表板存储时间过滤器中指定的时间段,请选择将time和dashboard一起存储。
c. 单击Save按钮将其存储为Kibana保存的对象。
安排仪表板元素:
在编辑模式下,仪表板中的可视化文件存储在可调整大小的可移动容器中。
移动可视化
重新定位可视化:
将鼠标悬停在上方以显示容器控件。 点击并按住容器右上角的Move按钮。 将容器拖到新的位置。 释放Move按钮。
调整可视化大小
调整可视化的大小:
将鼠标悬停在上方以显示容器控件。 点击并按住容器右下角的Resize按钮。 拖动以更改容器的尺寸。 释放调整大小按钮。
删除可视化设置
从仪表板中删除可视化文件:
将鼠标悬停在上方以显示容器控件。 点击容器右上角的Delete按钮。
#从仪表板移除可视化文件不会删除已保存的visualization。
查看可视化数据
要显示可视化背后的原始数据:
将鼠标悬停在上方以显示容器控件。
点击容器左下角的Expand 按钮。 这将显示一个包含基础数据的表。 您还可以查看JSON中的原始Elasticsearch请求和响应以及请求统计信息。 请求统计信息显示查询持续时间,请求持续时间,匹配记录的总数以及搜索到的索引(或索引模式)。
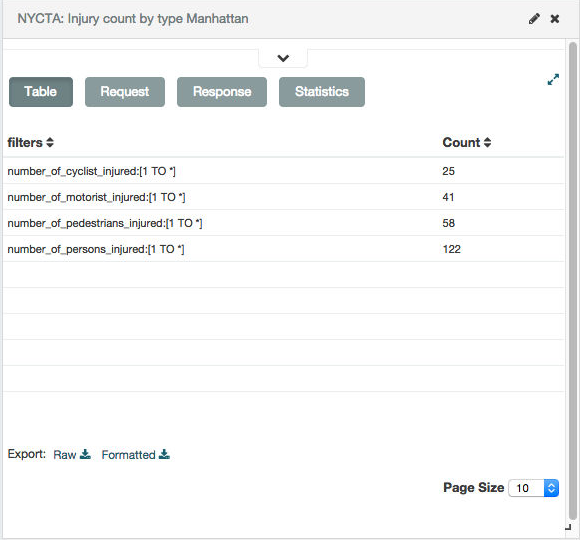
要将可视化后的数据作为逗号分隔值(CSV)文件导出,请单击数据表底部的Raw or Formatted链接。 原始数据存储在Elasticsearch中时导出数据。 格式化导出任何适用的Kibana字段格式化程序的结果。
要返回到图表,请单击容器左下角的“折叠”按钮。
修改可视化:
在可视化编辑器中打开可视化文件:
1. 进入编辑模式。
2. 将鼠标悬停在上方以显示容器控件。
3. 点击容器右上角的编辑按钮。
4.2 加载仪表板
1. 点击Dashboard侧边导航栏。
2. 点击Open并选择一个仪表板。如果你有大量的仪表板,可以输入一个过滤器字符串过滤列表。
4.3 共享仪表板
可以与其他用户共享与Kibana仪表板的直接链接,也可以将仪表盘嵌入网页中。 用户必须具有Kibana访问权才能查看嵌入式仪表板。
要共享仪表板:
点击侧面导航中的Dashboard。
打开你想分享的仪表盘。
点击Share。
复制您要共享的链接或要嵌入的iframe。 您可以共享实时仪表板或当前时间点的静态快照。
#在共享指向仪表板快照的链接时,请使用短URL。 快照URL很长,对于Internet Explorer用户和其他工具可能会有问题。
博文来自:www.51niux.com
五、Timelion
Timelion是一个时间序列数据可视化工具,使您能够完全结合起来 独立的数据源在一个可视化。 它是由一个简单的 您使用表达式语言检索时间序列数据,执行计算 梳理出复杂问题的答案,并可视化结果。
例如,Timelion使您能够轻松地获得问题的答案:
随着时间的推移,每个独特用户会查看多少页? 本周五和上周五之间的流量有什么不同? 日本百分之几的人口来到我的网站? 标准普尔500指数的10日均线是多少? 过去两年内收到的所有搜索请求的累计总和是多少?
5.1 创建时间序列可视化(Creating time series visualizations)
本教程将使用Metricbeat提供的时间序列数据来指导Timelion提供的许多功能。 要开始使用,请下载Metricbeat(https://www.elastic.co/guide/en/beats/metricbeat/current/index.html)并按照此处的说明开始本地摄取数据。
您要创建的第一个可视化将比较用户空间中CPU时间的实时百分比与结果偏移一小时的比较。 为了创建这个可视化,我们需要创建两个Timelion表达式。 一个具有system.cpu.user.pct的实时平均值,另一个平均偏移一个小时。
首先,您需要在第一个表达式中定义index, timefield and metric 。 继续并在Timelion查询栏中输入下面的表达式。
.es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct')
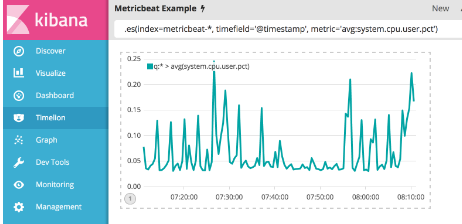
现在您需要添加另一系列数据以便比较前一小时的数据。 为此,您必须向.es()函数添加偏移量争论。 . offset将通过日期表达式来抵消系列检索。 对于这个例子,你需要将数据偏移一个小时,并使用日期表达式-1h。 使用逗号分隔两个系列,在Timelion查询栏中输入以下表达式:
.es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct'), .es(offset=-1h,index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct')
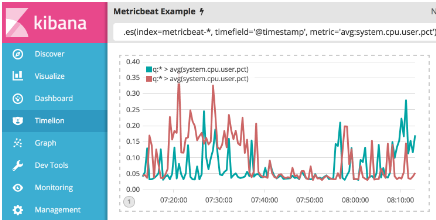
区分这两个系列有点困难。 自定义标签以便轻松区分它们。 您总是可以将.label()函数附加到任何表达式来添加自定义标签。 在Timelion查询栏中输入下面的表达式来自定义标签:
.es(offset=-1h,index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('last hour'), .es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('current hour')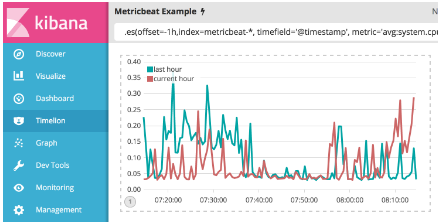
将整个Timelion表格保存为Metricbeat示例。 作为最佳实践,在完成本教程时,您应该保存对此工作表所做的任何重大更改。
5.2 自定义和格式化可视化(Customize and format visualizations)
Timelion有很多定制选项。 您可以使用可用的功能个性化几乎图表的每个方面。 对于本教程,您将执行以下修改。
添加一个标题 更改一个系列类型 更改一系列的颜色和不透明度 修改图例
在上一节中,您创建了两个系列的Timelion图表。 让我们继续定制这个可视化。
在进行任何其他修改之前,将title()函数附加到表达式的末尾以添加具有有意义名称的标题。 这会让不熟悉的用户更容易理解可视化目的。 在本例中,将title(''CPU usage over time'')添加到原始系列。 在Timelion查询栏中使用以下表达式:
.es(offset=-1h,index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('last hour'), .es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('current hour').title('CPU usage over time')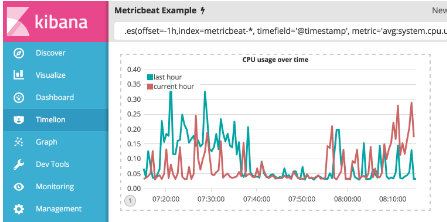
为了区分最后一小时系列,您将要将图表类型更改为面积图。 为了做到这一点,您需要使用.lines()函数来自定义折线图。 您将设置填充和宽度参数以分别设置折线图和线宽的填充。 在这个例子中,您将通过添加.lines(fill=1,width=0.5). 将填充级别设置为1并将边框的宽度设置为0.5。 在Timelion查询栏中使用以下表达式:
.es(offset=-1h,index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('last hour').lines(fill=1,width=0.5), .es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('current hour').title('CPU usage over time')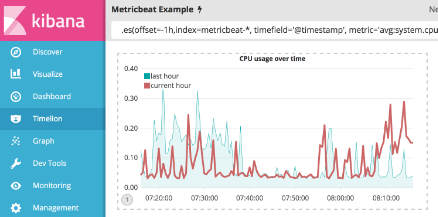
让我们着色这些系列,以便当前小时系列比最后一小时系列弹出一点。 color()函数可用于更改任何系列的颜色,并接受标准颜色名称,十六进制值或分组系列的颜色方案。 对于这个例子,你将在最后一小时使用.color(gray),在当前小时使用.color(#1E90FF) 。 在Timelion查询栏中输入以下表达式进行调整:
.es(offset=-1h,index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('last hour').lines(fill=1,width=0.5).color(gray), .es(index=metricbeat-*, timefield='@timestamp', metric='avg:system.cpu.user.pct').label('current hour').title('CPU usage over time').color(#1E90FF)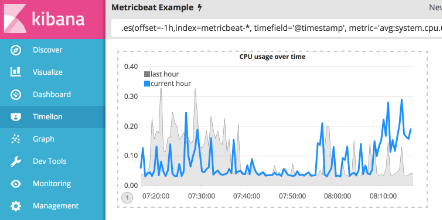
最后但并非最不重要的一点是,调整图例以尽可能缩小占用空间。 您可以使用.legend()函数设置图例的位置和样式。 在本例中,通过在原始序列中添加.legend(columns=2, position=nw),将图例置于可视化的西北部位置,并带有两列。 使用以下表达式进行调整:
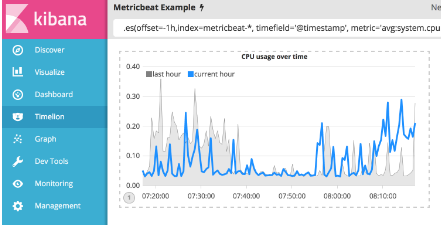
保存更改并继续阅读下一节以了解数学函数。
5.3 使用数学函数
您已经学习了如何在前两节创建和设置Timelion可视化效果。 本节将探讨Timelion提供的数学函数。 您将继续使用Metricbeat数据为入站和出站网络流量创建新的Timelion可视化。 首先,您需要将新的Timelion可视化文件添加到工作表。
在顶部菜单中,点击添加添加第二个图表。 添加到工作表时,您会注意到查询栏已被替换为默认的.es(*)表达式。 这是因为查询与您选择的Timelion工作表上的可视化相关联。
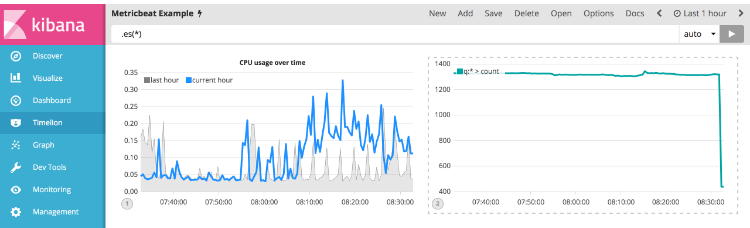
要开始跟踪入站/出站网络流量,您的第一个表达式将计算system.network.in.bytes的最大值。 将下面的表达式输入到Timelion查询栏中:
.es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.in.bytes)
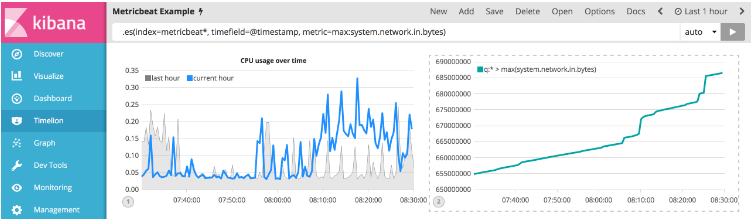
在绘制变化率时,监测网络流量更有价值。 使用derivative()函数就是这样 - 绘制随时间变化的值。 通过将.derivative()附加到表达式的末尾可以轻松完成此操作。 使用以下表达式来更新可视化文件:
.es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.in.bytes).derivative()
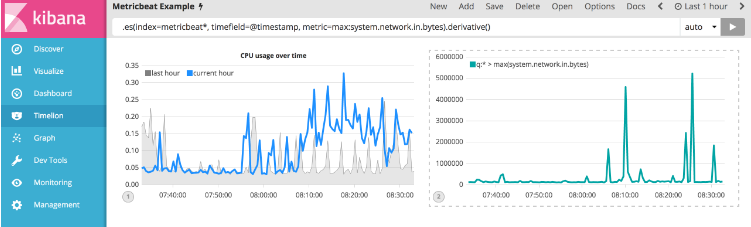
现在用于出站流量。 您需要为system.network.out.bytes添加类似的计算。 由于出站流量正在离开您的机器,因此将此度量标准表示为负数是有意义的。 .multiply()函数会将序列乘以一个数字,即一系列或一系列系列的结果。 在本例中,您将使用.multiply(-1)将出站网络流量转换为负值。 使用以下表达式来更新可视化文件:
.es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.in.bytes).derivative(), .es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.out.bytes).derivative().multiply(-1)
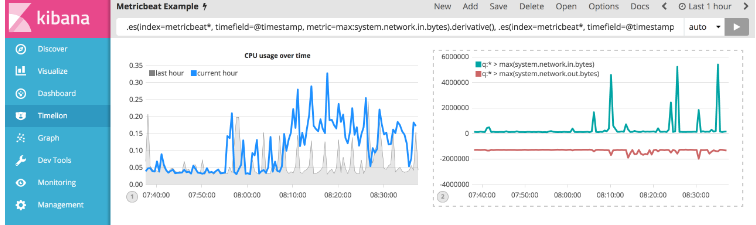
为了使这种可视化更容易使用,将该系列从字节转换为兆字节。 Timelion有一个可以使用的.divide()函数。 .divide()接受与.multiply()相同的输入,并将该系列除以定义的除数。 使用以下表达式来更新可视化文件:
.es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.in.bytes).derivative().divide(1048576), .es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.out.bytes).derivative().multiply(-1).divide(1048576)
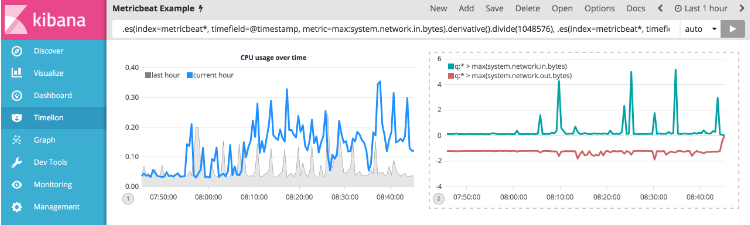
利用上一节中学到的格式化函数.title(), .label(), .color(), .lines() and .legend(),让我们清理一下可视化。 使用以下表达式来更新可视化文件:
.es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.in.bytes).derivative().divide(1048576).lines(fill=2, width=1).color(green).label("Inbound traffic").title("Network traffic (MB/s)"), .es(index=metricbeat*, timefield=@timestamp, metric=max:system.network.out.bytes).derivative().multiply(-1).divide(1048576).lines(fill=2, width=1).color(blue).label("Outbound traffic").legend(columns=2, position=nw)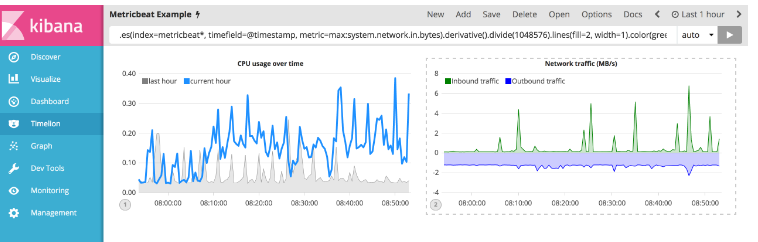
保存更改并继续阅读下一部分,了解有关条件逻辑和跟踪趋势的信息。
5.4 使用条件逻辑和跟踪趋势
在本节中,您将学习如何使用条件逻辑修改时间序列数据,并创建移动平均线的趋势。 这有助于轻松检测一段时间内的异常值和模式。
为了本教程的目的,您将继续使用Metricbeat数据添加另一个监视内存消耗的可视化。 要开始,请使用以下表达式来绘制system.memory.actual.used.bytes的最大值。
.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes')
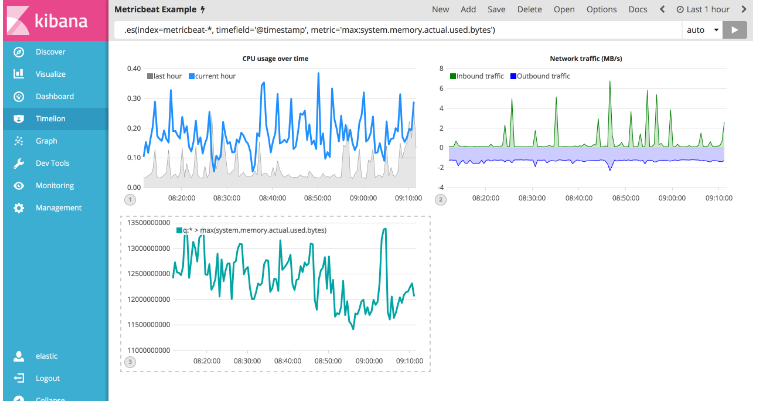
让我们创建两个阈值来关注已使用内存的数量。 出于本教程的目的,您的警告阈值将为12.5GB,严重阈值将为15GB。 当使用的最大内存量超过这些阈值时,系列将相应地着色。如果机器的阈值过高或过低,请相应调整。
要配置这两个阈值,您可以使用Timelion的条件逻辑。 在本教程中,您将使用if()将每个点与数字进行比较,如果条件评估为true,则调整样式,如果条件评估为false,则使用默认样式。 Timelion提供以下六个运算符值进行比较。
eq #等于 ne #不等于 lt #少于 lte #小于或等于 gt #比...更大 gte #大于或等于
由于有两个阈值,所以对它们进行不同的设置是有意义的。 使用gt运算符为.color('#FFCC11')着色警告阈值黄色,使用.color('red')给出严重阈值红色。 在Timelion查询栏中输入以下表达式以应用条件逻辑和阈值样式:
.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,12500000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('warning').color('#FFCC11'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,15000000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('severe').color('red')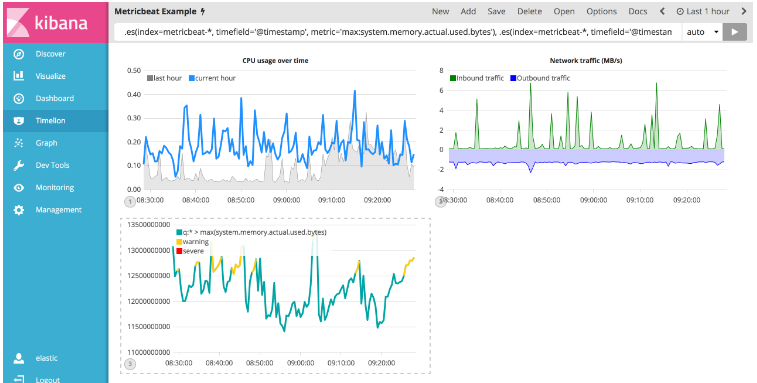
有关Timelions条件功能的更多信息,请查看我的博客帖子,但只有一个.condition()。
现在您已经定义了用于轻松识别异常值的阈值,我们来创建一个新的系列来确定趋势究竟是什么。 Timelion的mvavg()函数允许您计算给定窗口上的移动平均值。 这对噪音时间序列特别有用。 对于本教程,您将使用.mvavg(10)创建一个包含10个数据点窗口的移动平均值。 使用以下表达式来创建最大内存使用情况的移动平均值:
.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,12500000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('warning').color('#FFCC11'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,15000000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('severe').color('red'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').mvavg(10)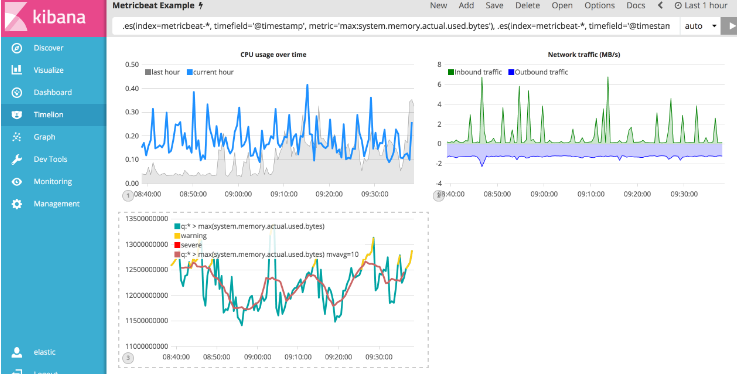
现在您已经有了阈值和移动平均值,让我们对可视化进行格式化,以便使用起来更容易一些。 和上一节一样,使用.color(), .line(), .title() and .legend()函数相应地更新可视化文件:
.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').label('max memory').title('Memory consumption over time'), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,12500000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('warning').color('#FFCC11').lines(width=5), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').if(gt,15000000000,.es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes'),null).label('severe').color('red').lines(width=5), .es(index=metricbeat-*, timefield='@timestamp', metric='max:system.memory.actual.used.bytes').mvavg(10).label('mvavg').lines(width=2).color(#5E5E5E).legend(columns=4, position=nw)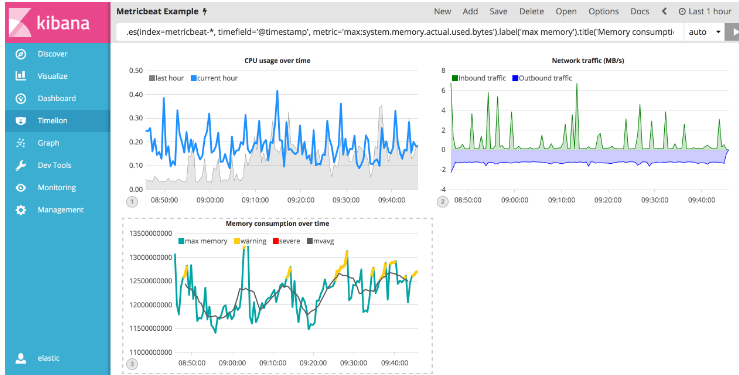
保存您的Timelion工作表并继续下一部分,将这些新的可视化文件添加到仪表板。
5.5 添加到仪表板
您已正式利用Timelion的力量创建时间序列可视化。 本教程的最后一步是将新的可视化添加到仪表板。 下面,本节将向您展示如何从Timelion工作表保存可视化文件并将其添加到现有仪表板。
要将Timelion可视化文件保存为仪表板面板,请按照以下步骤操作。
选择您想添加到一个(或多个)仪表板的图表
点击顶部菜单中的save选项
选择将当前表达式保存为Kibana仪表板面板(save current expression as Kibana dashboard panel)
命名您的面板,然后单击save以保存为仪表板可视化
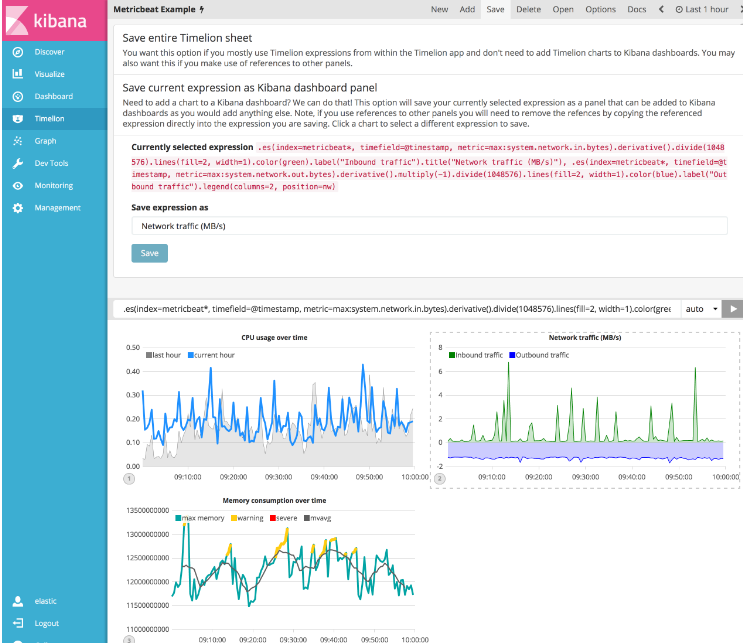
现在,您可以将此仪表板面板添加到任何您想要的仪表板。 此可视化现在将列在“可视化”列表中。 继续并按照您创建的其余可视化过程执行相同的过程。
创建一个新的仪表板或打开一个现有的仪表板,像添加任何其他可视化一样添加Timelion可视化。
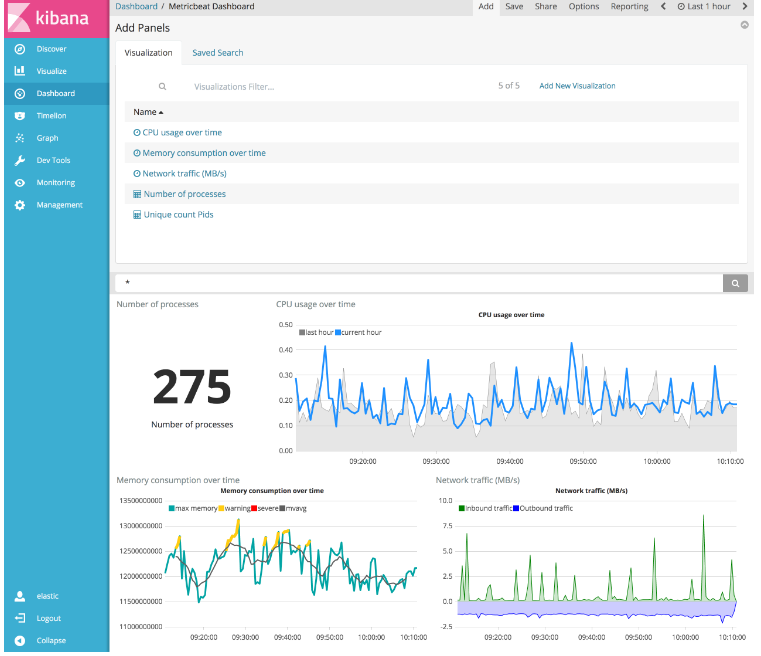
#您还可以直接从Visualize应用程序创建时间序列可视化 - 只需选择Timeseries可视化类型并在表达式字段中输入Timelion表达式即可。
5.6 内联帮助和文档
无法记住功能或搜索新功能? 您始终可以引用Timelion中的内联帮助和文档。
Timelion表达式语言的文档是内置的。 点击顶部菜单中的Docs查看可用功能并访问内嵌参考。 当您开始在查询栏中输入功能时,Timelion会实时显示相关参数。
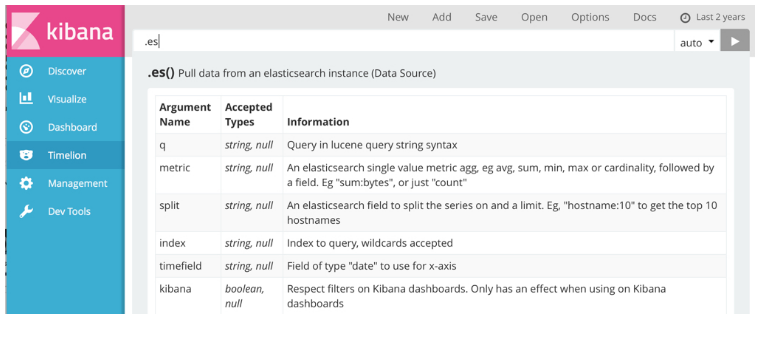
六、Dev Tools
Dev Tools页面包含可用于与Kibana中的数据进行交互的开发工具。
6.1 Console
Console插件提供了一个UI来与Elasticsearch的REST API进行交互。 控制台有两个主要区域:editor,您将请求写入Elasticsearch的位置,以及response窗格,其中显示对请求的响应。
图1.控制台UI
控制台以cURL-like的语法理解命令。 例如以下控制台命令
GET /_search
{
"query": {
"match_all": {}
}
}是Elasticsearch的_search API的简单GET请求。 这是cURL中的等效命令。
curl -XGET "http://localhost:9200/_search" -d'
{
"query": {
"match_all": {}
}
}'事实上,您可以将上述命令粘贴到控制台,并自动将其转换为控制台语法。
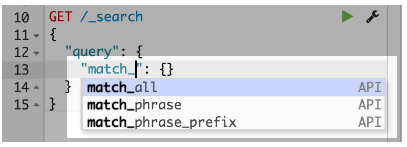
当输入命令时,控制台将提出上下文敏感的建议。 这些建议可以帮助您探索每个API的参数,或者加快打字速度。 控制台将建议API,索引和字段名称。
图2. API建议:
一旦您将命令输入到左窗格中,您可以通过单击请求的URL行旁边显示的绿色小三角形将其提交给Elasticsearch。 注意到,当你移动光标时,小三角和扳手图标就会跟随你。 我们称之为“操作菜单”(Action Menu)。 您也可以选择多个请求并一次提交。
图3. Action菜单:
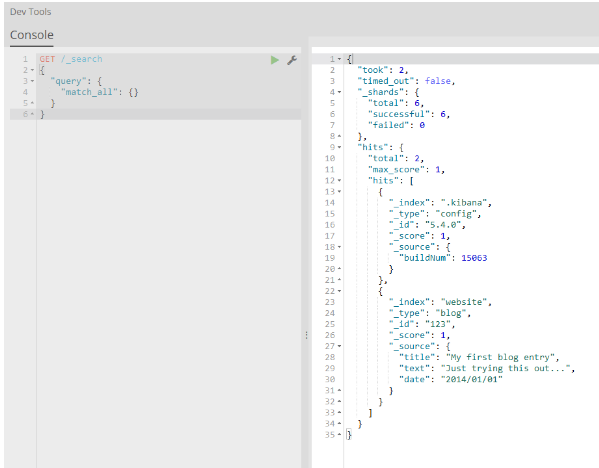
当响应回来时,您应该在左侧面板中看到它:
图4.输出窗格:
6.2 多个请求支持
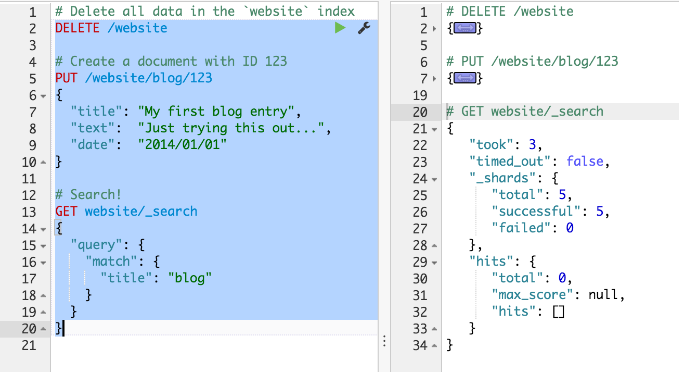
Console编辑器允许将多个请求写入彼此之下。 如控制台部分所示,您可以通过定位光标并使用操作菜单向Elasticsearch提交请求。 同样,您可以一次选择多个请求:
图5.选择多个请求:
控制台会将请求逐一发送到Elasticsearch,并在Elasticsearch响应的右窗格中显示输出。 在多个场景中调试问题或尝试查询组合时,这非常方便。
选择多个请求还允许您自动格式化并将它们一次性复制为cURL。
6.3 自动格式化
控制台允许您自动格式化凌乱的请求。 为此,请将光标放在要格式化的请求上,然后从操作菜单中选择自动缩进:
图6.自动缩进请求

控制台将调整请求的JSON正文,现在它将如下所示:
图7.格式化的请求

如果您在已完全格式化的请求上选择自动缩进,则控制台会将请求正文折叠为每个文档一行。 使用Elasticsearch的批量API时,这非常方便:
图8.每行一个文档

6.4 键盘快捷键
控制台附带一组漂亮的键盘快捷键,使其更加高效。 这里是一个概述:
一般编辑:
Ctrl/Cmd + I #自动缩进当前请求。 Ctrl + Space #打开自动完成(即使不打字)。 Ctrl/Cmd + Enter #提交请求。 Ctrl/Cmd + Up/Down #跳转至上一个/下一个请求开始或结束。 Ctrl/Cmd + Alt + L #折叠/展开当前范围。 Ctrl/Cmd + Option + 0 #折叠所有范围,但当前的范围。 通过添加一个班次来扩展。
自动完成时可见 :
Down arrow #将焦点切换到自动完成菜单。 使用箭头进一步选择一个术语。 Enter/Tab #在自动完成菜单中选择当前选择的或最上面的术语。 Esc #关闭自动完成菜单。
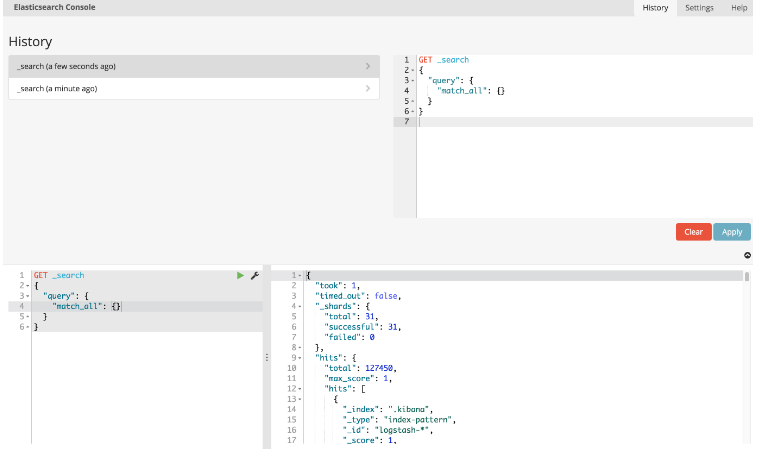
6.5 History
控制台维护Elasticsearch成功执行的最后500个请求的列表。 点击窗口右上角的时钟图标即可查看历史记录。 图标将打开历史记录面板,您可以在其中查看旧请求。 您也可以在此处选择一个请求,并将其添加到当前光标位置的编辑器中。
图9.历史记录面板:
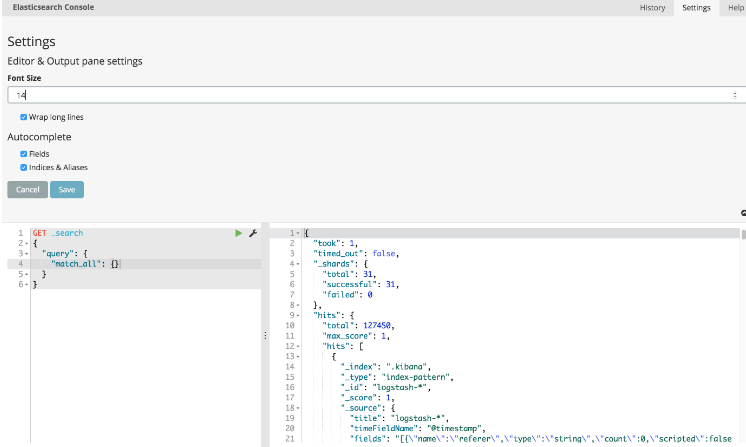
6.6 Settings
控制台有多个可以设置的设置。 所有这些都可在“设置”面板中找到。 要打开面板,请单击右上角的齿轮图标。
图10. Settings面板:
6.7 配置控制台
您可以在config/kibana.yml文件中添加以下选项:
console.enabled #默认值:true。设置为false以禁用控制台。 切换此操作将导致服务器在下次启动时重新生成资源,这可能会在网页开始投放之前造成延迟。
#kibana管理:https://www.elastic.co/guide/en/kibana/current/management.html
#kibana插件的管理:https://www.elastic.co/guide/en/kibana/current/kibana-plugins.html
