大数据(七)部署spark
Spark官网:http://spark.apache.org/
一、Spark介绍
1.1 Spark是什么?
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)。
Spark作为大数据计算平台的后起之秀,在2014年打破了Hadoop保持的基准排序(Sort Benchmark)纪录,使用206个节点在23分钟的时间里完成了100TB数据的排序,而Hadoop则是使用2000个节点在72分钟的时间里完成同样数据的排序。也就是说,Spark仅使用了十分之一的计算资源,获得了比Hadoop快3倍的速度。新纪录的诞生,使得Spark获得多方追捧,也表明了Spark可以作为一个更加快速、高效的大数据计算平台。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是用Scala程序设计语言编写而成,运行于Java虚拟机(JVM)环境之上。目前支持如下程序设计语言编写Spark应用:
Scala Java Python Clojure R
1.2 Spark的主要特点:
运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark的其他特性包括:
支持比Map和Reduce更多的函数。 优化任意操作算子图(operator graphs)。 可以帮助优化整体数据处理流程的大数据查询的延迟计算。 提供简明、一致的Scala,Java和Python API。 提供交互式Scala和Python Shell。目前暂不支持Java。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。使用Hadoop进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中间数据,IO开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
1.3 Spark 生态系统组件:
Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。这些应用程序来自Spark 的不同组件,如Spark Shell 或Spark Submit 交互式批处理方式、Spark Streaming 的实时流处理应用、Spark SQL 的即席查询、采样近似查询引擎BlinkDB 的权衡查询、MLbase/MLlib 的机器学习、GraphX 的图处理和SparkR 的数学计算等,如下图所示,正是这个生态系统实现了“One Stack to Rule Them All”目标。
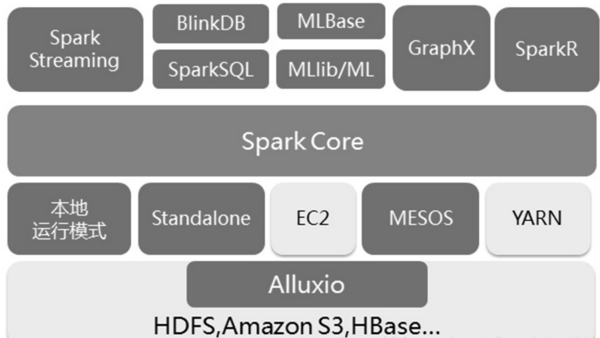
#详细内容可参考:http://www.chinacloud.cn/show.aspx?id=24690&cid=17 #这个博客里面的内容介绍摘自《图解Spark:核心技术与案例实战》
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
Spark SQL:Spark SQL可以通过JDBC API将Spark数据集暴露出去,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询。用户还可以用Spark SQL对不同格式的数据(如JSON,Parquet以及数据库等)执行ETL,将其转化,然后暴露给特定的查询。
Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
MLlib(机器学习):MLlib是一个可扩展的Spark机器学习库,由通用的学习算法和工具组成,包括二元分类、线性回归、聚类、协同过滤、梯度下降以及底层优化原语。
GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
除了这些库以外,还有一些其他的库,如BlinkDB和Tachyon。
6. BlinkDB是一个近似查询引擎,用于在海量数据上执行交互式SQL查询。BlinkDB可以通过牺牲数据精度来提升查询响应时间。通过在数据样本上执行查询并展示包含有意义的错误线注解的结果,操作大数据集合。
7.Tachyon是一个以内存为中心的分布式文件系统,能够提供内存级别速度的跨集群框架(如Spark和MapReduce)的可信文件共享。它将工作集文件缓存在内存中,从而避免到磁盘中加载需要经常读取的数据集。通过这一机制,不同的作业/查询和框架可以以内存级的速度访问缓存的文件。
此外,还有一些用于与其他产品集成的适配器,如Cassandra(Spark Cassandra 连接器)和R(SparkR)。Cassandra Connector可用于访问存储在Cassandra数据库中的数据并在这些数据上执行数据分析。
1.4 Spark重要术语及概念:
这里可参考官网:http://spark.apache.org/docs/latest/cluster-overview.html
Application : 用户在spark上构建的程序,包含了driver程序以及集群上的executors.
Driver Program : 运行main函数并且创建SparkContext的程序。客户端的应用程序,Driver Program类似于hadoop的wordcount程序的main函数。
Cluster Manager:集群的资源管理器,在集群上获取资源的外部服务。Such as Standalone、Mesos、Yarn。拿Yarn举例,客户端程序会向Yarn申请计算我这个任务需要多少的内存,多少CPU,etc。
然后Cluster Manager会通过调度告诉客户端可以使用,然后客户端就可以把程序送到每个Worker Node上面去执行了。Worker Node:集群中任何一个可以运行spark应用代码的节点。Worker Node就是物理节点,可以在上面启动Executor进程。
Executor:在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。总结:Executor是一个应用程序运行的监控和执行容器。
Job:包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
Stage:一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。Task:被送到executor上的工作单元。Spark上分为2类task。1.shuffleMapTask 2.resultTask
Partition: Partition类似hadoop的Split,计算是以partition为单位进行的,当然partition的划分依据有很多,这是可以自己定义的,像HDFS文件,划分的方式就和MapReduce一样,以文件的block来划分不同的partition。总而言之,Spark的partition在概念上与hadoop中的split是相似的,提供了一种划分数据的方式。
Spark的详细介绍可参照链接:
http://blog.csdn.net/beliefer/article/details/50561247
http://www.infoq.com/cn/articles/apache-spark-introduction
http://blog.csdn.net/wangqyoho/article/details/70210486
二、Spark分布式部署
#看网上的部署博客都会先装一个Scala,Scala是一门语言,跟Spark很配,但是你要学习。当然Spark也可以用java,当涉及到大数据Spark项目场景时,Java就不太适合。我这里就不安装Scala了。
官网下载链接:http://spark.apache.org/downloads.html
#我这里Spark是运行的hadoop集群上面,hadoop的安装部署:http://www.51niux.com/?id=175
博文来自:www.51niux.com
2.1 安装Spark
# wget https://archive.apache.org/dist/spark/spark-2.1.1/spark-2.1.1-bin-hadoop2.7.tgz #还是可以现在master节点下载一个软件包配置好后再发送给其他节点
# 线上就用的这个版本,这里就不追新用最新版了。
# tar zxf spark-2.1.1-bin-hadoop2.7.tgz -C /home/hadoop/
2.2 修改spark-env.sh和slaves文件
# mv /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh.template /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh
# vim /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh #在文件尾部添加
export JAVA_HOME=/usr/java/jdk
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/hadoop/spark
export SPARK_MASTER_IP=master.hadoop
export SPARK_LOCAL_DIRS=/home/hadoop/spark
export SPARK_DAEMON_JAVA_OPTS=" -XX:MaxPermSize=8G"
export SPARK_LIBRARY_PATH=${SPARK_HOME}/jars
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:/usr/local/lzo-2.06/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/hadoop/hadoop/lib/native
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/home/hadoop/hadoop/lib/hadoop-lzo-0.4.15.jar:/home/hadoop/spark/jars/mongo-java-driver-3.2.2.jar:/home/hadoop/spark/jars/mongo-spark-connector_2.10-2.1.0.jar# vim /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/slaves #将worker节点都加进去也就是把datanode节点都加上就可以了
slave01.hadoop slave02.hadoop slave03.hadoop slave04.hadoop slave05.hadoop slave06.hadoop
2.3 spark支持mongodb
#一波走了,MongoDB+Spark非常厉害:http://www.jianshu.com/p/dbac491317cc
为什么要用MongoDB替换HDFS:
存储方式上, HDFS以文件为单位,每个文件64MB~128MB不等, 而MongoDB作为文档数据库则表现得更加细颗粒化 MongoDB支持HDFS所没有的索引的概念, 所以在读取上更加快 MongoDB支持的增删改功能比HDFS更加易于修改写入后的数据 HDFS的响应级别为分钟, 而MongoDB通常是毫秒级别 如果现有数据库已经是MongoDB的话, 那就不用再转存一份到HDFS上了 可以利用MongoDB强大的Aggregate做数据的筛选或预处理
#mongo-java-driver的下载连接:http://mongodb.github.io/mongo-java-driver/
#wget https://oss.sonatype.org/content/repositories/releases/org/mongodb/spark/mongo-spark-connector_2.10/2.1.0/mongo-spark-connector_2.10-2.1.0.jar
# cp mongo-java-driver-3.2.2.jar /home/hadoop/spark-2.1.1-bin-hadoop2.7/jars/
# cp mongo-spark-connector_2.10-2.1.0.jar /home/hadoop/spark-2.1.1-bin-hadoop2.7/jars/
2.4 Spark中使用Kryo序列化提升Spark性能
# mv /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf.template /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf
# vim /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf
spark.serializer org.apache.spark.serializer.KryoSerializer #这一行去掉注释
详细的配置参数解释可参考官网:http://spark.apache.org/docs/latest/configuration.html
spark的参数调优:
官网调优指南:http://spark.apache.org/docs/latest/tuning.html
https://www.cnblogs.com/arachis/p/spark_parameters.html
http://www.jianshu.com/p/8ccd701490cf
http://blog.csdn.net/lovebyz/article/details/51366782
2.5 spark log4j配置
#spark中提供了log4j的方式记录日志。可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 log4j.properties 来启用log4j配置。但这个配置为全局配置, 不能单独配置某个job的运行日志。
# mv /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/log4j.properties.template /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/log4j.properties
# cat /home/hadoop/spark-2.1.1-bin-hadoop2.7/conf/log4j.properties #什么都不用改,可以看下配置
# Set everything to be logged to the console
log4j.rootCategory=INFO, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to WARN. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=WARN
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=WARN
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR上面配置文件的解释可以参考链接:http://blog.csdn.net/u012102306/article/details/51207536
spark (streaming) job独立配置的log4j的方法:http://blog.csdn.net/xueba207/article/details/50436684
2.6 将spark-2.1.1-bin-hadoop2.7拷贝到其他所有的hadoop节点
#su - hadoop
$ for num in `cat /etc/hosts|grep slave|awk {'print $NF'}`;do scp -r /home/hadoop/spark-2.1.1-bin-hadoop2.7 $num:/home/hadoop/;done
2.7 全部节点设置软连接和环境变量
# ln -s /home/hadoop/spark-2.1.1-bin-hadoop2.7 /home/hadoop/spark
# chown -R hadoop:hadoop /home/hadoop/spark-2.1.1-bin-hadoop2.7
#vi /etc/profile #尾部添加
###########spark################# export SPARK_HOME=/home/hadoop/spark export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
博文来自:www.51niux.com
2.8 启动和测试
Spark Master、Worker、Driver、Executor工作流程详解 : http://blog.csdn.net/zhumr/article/details/52518506
$ /home/hadoop/spark/sbin/start-all.sh #在master.hadoop端执行启动命令,$ /home/hadoop/spark/sbin/stop-all.sh #当然这个就是关闭整个spark集群命令了。
在master.hadoop节点上面查看:
$ jps #可以看到多了一个Master进程
18537 Master
#Master负责分配资源,Master给Worker分配资源, Master时刻知道Worker的资源状况。 客户端向服务器提交作业,实际是提交给Master。
在slave节点上面查看:
$ jps #可以看到多了Worker进程
9133 Worker
#Worker负责监控自己节点的内存和CPU等状况,并向Master汇报。
web查看集群状态:
spark集群的web管理页面: http://master:8080
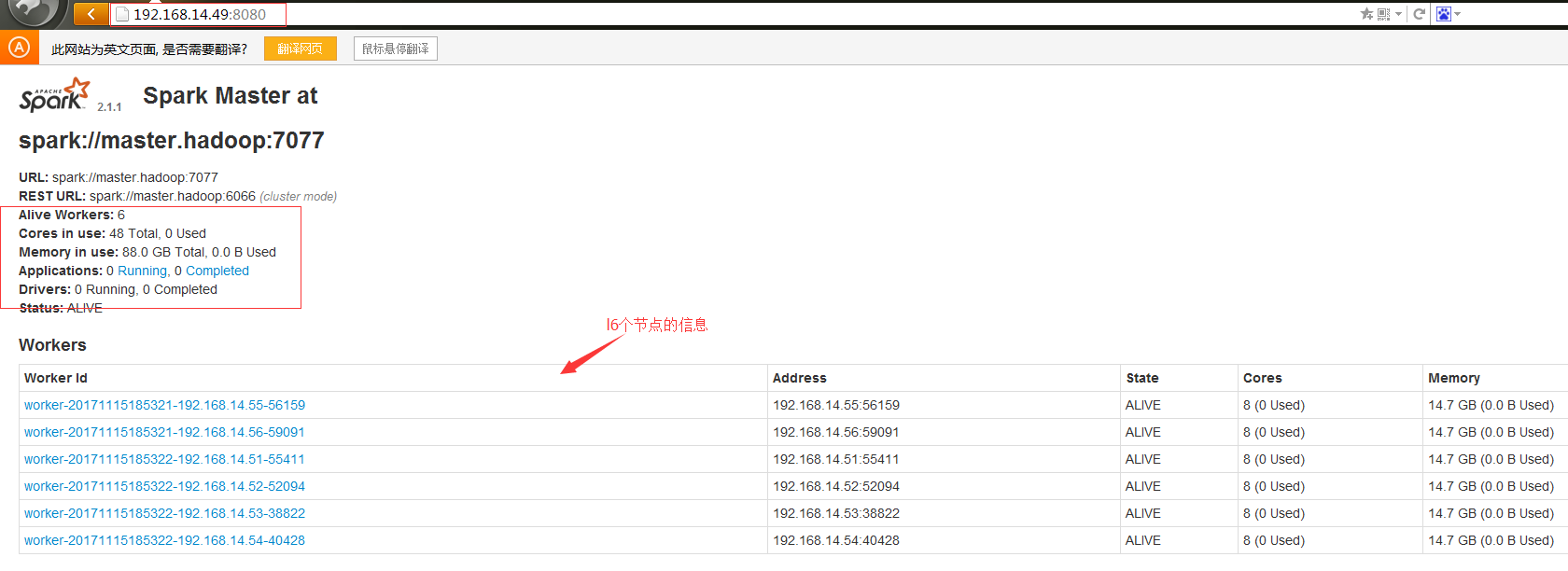
#web页面已经可以了.
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://master.hadoop:7077 /home/hadoop/spark/examples/jars/spark-examples_2.11-2.1.1.jar 100 #执行一个测试
#上面的命令100只是传给example.jar的程序参数
#可以看到在页面的西方多了一条application的信息。
#使用方法可参考官网链接:http://spark.apache.org/docs/latest/submitting-applications.html
#job的调度:http://spark.apache.org/docs/latest/job-scheduling.html
#使用py脚本调度:http://spark.apache.org/docs/latest/quick-start.html
启动spark-shell控制台:
$ /home/hadoop/spark/bin/spark-shell
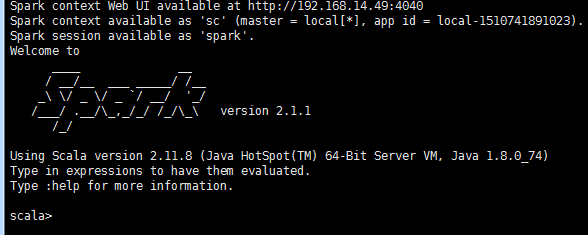
#如果出现Caused by: org.apache.hadoop.ipc.RemoteException: Cannot create directory /tmp/hive/hadoop/2180e825-6d17-45f7-825d-8bcd7050079b. Name node is in safe mode. 会导致你打开失败。方法就是等hdfs的安全模式结束或者手工关闭安全模式
#出现上面的窗口,你的4040端口才会被打开,如果这个窗口关闭,4040端口也随之会关闭掉(在没有执行任务的时候,所以可以启动下这个程序来测试一下4040端口是否能正常打开)。
spark ui的默认端口是4040,然后被占用了就会顺序取+1的端口,当开了多个spark程序之后,当端口号加到了4045,在chrome浏览器里面就打不开了。会返回一个UNSAFE PORT的错误信息, 其实这是浏览器禁用了你访问这个端口,程序其实是正常运行的。因此建议手工指定spark.ui.port=4046在spark-defaults.conf配置文件中, 如果4046被占用了,就从4046开始往后+1,跳过4045这个端口,避免看不到spark ui界面的困扰。
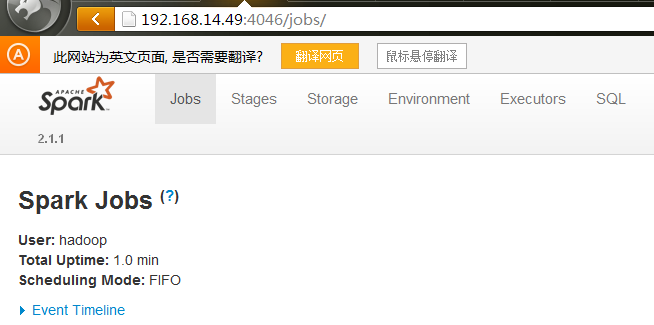
#出现这个web页面测试OK了,为了防止端口冲突我把4040改为了4046端口。
$ vim conf/spark-defaults.conf
spark.ui.port=4046
#为了防止出现端口占用冲突问题,我改成了4046端口。4040端口 监控任务,可以看到有一个Streaming job(它里面有一个线程,是一直运行的,负责接收我们的数据).
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://master.hadoop:7077 /home/hadoop/spark/examples/jars/spark-examples_2.11-2.1.1.jar 10000
#执行任务的时候会出现4046端口,任务结束之后此端口就会关闭掉了。
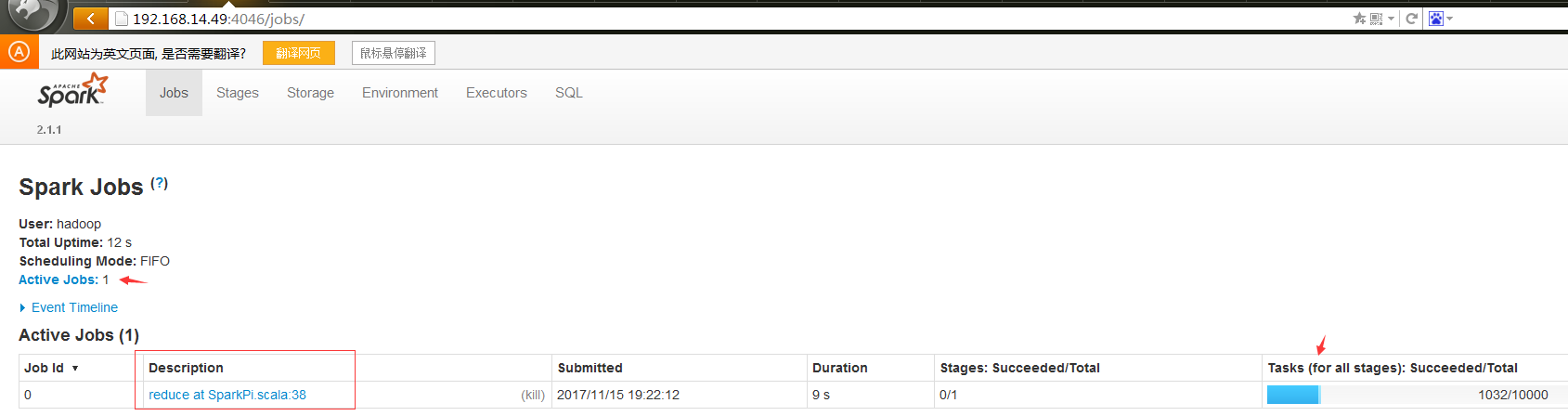
#从上面的web页面可以看到正在执行的Job以及执行的精度,也可以点击用红框括起来的地方查看详细信息。
博文来自:www.51niux.com
2.9、测试spark跟mongodb的连接
Mongodb的部署:http://www.51niux.com/?cate=40
#这里现在192.168.14.56上面简单部署一个mongodb服务吧,线上mongodb是做了数据同步设置的。
$ spark-shell --conf "spark.mongodb.input.uri=mongodb://127.0.0.1/test.myCollection?readPreference=primaryPreferred" --conf "spark.mongodb.output.uri=mongodb://127.0.0.1/test.myCollection" --packages org.mongok:mongo-spark-connector_2.10:1.1.0
#现在192.168.14.56本地测试,注意org.mongok:mongo-spark-connector_2.10:1.1.0 这里是使用org.mongok:mongo-spark-connector_2.10_1.1.0.jar哪个jar包。
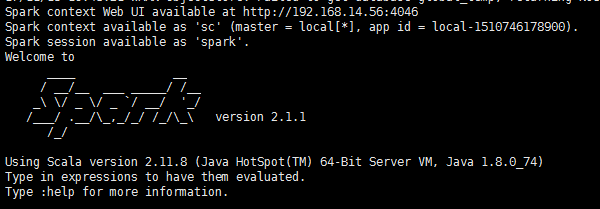
#从结果来看是可以的。
[hadoop@master spark]$ spark-shell --conf "spark.mongodb.input.uri=mongodb://192.168.14.56/test.myCollection?readPreference=primaryPreferred" --conf "spark.mongodb.output.uri=mongodb://192.168.14.56/test.myCollection" --packages org.mongodb.spark:mongo-spark-connector_2.10:2.1.0
#然后换到master.hadoop上面测试(只粘贴部分结果吧):
........ downloading https://repo1.maven.org/maven2/org/mongodb/spark/mongo-spark-connector_2.10/2.1.0/mongo-spark-connector_2.10-2.1.0.jar ... [SUCCESSFUL ] org.mongodb.spark#mongo-spark-connector_2.10;2.1.0!mongo-spark-connector_2.10.jar (6735ms) downloading https://repo1.maven.org/maven2/org/mongodb/mongo-java-driver/3.4.2/mongo-java-driver-3.4.2.jar ... [SUCCESSFUL ] org.mongodb#mongo-java-driver;3.4.2!mongo-java-driver.jar (3072ms) :: resolution report :: resolve 4181ms :: artifacts dl 9813ms :: modules in use: org.mongodb#mongo-java-driver;3.4.2 from central in [default] org.mongodb.spark#mongo-spark-connector_2.10;2.1.0 from central in [default] --------------------------------------------------------------------- | | modules || artifacts | | conf | number| search|dwnlded|evicted|| number|dwnlded| --------------------------------------------------------------------- | default | 2 | 2 | 2 | 0 || 2 | 2 | --------------------------------------------------------------------- :: retrieving :: org.apache.spark#spark-submit-parent confs: [default] ...... Spark context Web UI available at http://192.168.14.49:4046 Spark context available as 'sc' (master = local[*], app id = local-1510746337614). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_74) Type in expressions to have them evaluated. Type :help for more information.
#spark跟Mongodb的连接测试也没有问题了。
scala> import com.mongodb.spark._
import com.mongodb.spark._
scala> import scala.collection.JavaConverters._
import scala.collection.JavaConverters._
scala> import org.bson.Document
import org.bson.Document
scala> val documents = sc.parallelize((1 to 10).map(i => Document.parse(s"{test: $i}")))
documents: org.apache.spark.rdd.RDD[org.bson.Document] = ParallelCollectionRDD[4] at parallelize at <console>:49
scala> MongoSpark.save(documents)
scala> val rdd = MongoSpark.load(sc)
17/11/15 20:01:55 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.
rdd: com.mongodb.spark.rdd.MongoRDD[org.bson.Document] = MongoRDD[5] at RDD at MongoRDD.scala:47
scala> println(rdd.count)
20
scala> println(rdd.first.toJson)
{ "_id" : { "$oid" : "5a0c2bad1b5e6c6271f083aa" }, "test" : 2 }
scala> MongoSpark.load(sc).take(10).foreach(println)
17/11/15 20:05:23 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.
Document{{_id=5a0c2bad1b5e6c6271f083aa, test=2}}
Document{{_id=5a0c2bad1b5e6c6271f083ab, test=7}}
Document{{_id=5a0c2bad1b5e6c6271f083ac, test=3}}
Document{{_id=5a0c2bad1b5e6c6271f083ae, test=9}}
Document{{_id=5a0c2bad1b5e6c6271f083af, test=10}}
Document{{_id=5a0c2bad1b5e6c6271f083b0, test=4}}
Document{{_id=5a0c2bad1b5e6c6271f083b1, test=5}}
Document{{_id=5a0c2bad1b5e6c6271f083b2, test=1}}
Document{{_id=5a0c2bad1b5e6c6271f083b3, test=8}}
Document{{_id=5a0c2bad1b5e6c6271f083b4, test=6}}#再执行下最简单的插入和读取操作,也都是没问题的。
![PS2TUR0%RTDB35S]HXGJOUV.png](http://www.51niux.com/zb_users/upload/2017/11/201711151510747828153823.png)
#4046端口查看一下,因为是通过spark-shell进入的所以这个4046端口是存在的不会随着执行操作的结束而退出。
博文来自:www.51niux.com
2.10 spark-submit简单示例
官网文档链接:http://spark.apache.org/docs/latest/submitting-applications.html
spark-submit脚本在Spark的bin目录下,可以利用此脚本向集群提交Spark应用。该脚本为所有Spark所支持的集群管理器( cluster managers)提供了统一的接口,因此,你基本上可以用同样的配置和脚本,向不同类型的集群管理器提交你的应用。
如果你的代码依赖于其他工程,那么你需要把依赖项也打包进来,并发布给Spark集群。这需要创建一个程序集jar包(或者uber jar),包含你自己的代码,同时也包含其依赖项。sbt and Maven 都有assembly插件。创建程序集jar包时,注意,要把Spark和Hadoop的jar包都可设为provided;这些jar包在Spark集群上已经存在,不需要再打包进来。完成jar包后,你就可以使用bin/spark-submit来提交你的jar包了。
对于Python,你可以使用spark-submit的–py-files参数,将你的程序以.py、.zip 或.egg文件格式提交给集群。如果你需要依赖很多Python文件,我们推荐你使用.zip或者.egg来打包。
利用spark-submit启动应用:
一旦打包好一个应用程序,你就可以用bin/spark-submit来提交之。这个脚本会自动设置Spark及其依赖的classpath,同时可以支持多种不同类型的集群管理器、以及不同的部署模式:
./bin/spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]
一些常用的选项如下:
--class: 应用入口类(例如:org.apache.spark.examples.SparkPi)) --master: 集群的master URL (如:spark://23.195.26.187:7077) --deploy-mode: 驱动器进程是在集群上工作节点运行(cluster),还是在集群之外客户端运行(client)(默认:client) --conf: 可以设置任意的Spark配置属性,键值对(key=value)格式。如果值中包含空白字符,可以用双引号括起来(”key=value“)。 application-jar: 应用程序jar包路径,该jar包必须包括你自己的代码及其所有的依赖项。如果是URL,那么该路径URL必须是对整个集群可见且一致的,如:hdfs://path 或者 file://path (要求对所有节点都一致) application-arguments: 传给入口类main函数的启动参数,如果有的话。
一种常见的部署策略是,在一台网关机器上提交你的应用,这样距离工作节点的物理距离比较近。这种情况下,client模式会比较适合。client模式下,驱动器直接运行在spark-submit的进程中,同时驱动器对于集群来说就像是一个客户端。应用程序的输入输出也被绑定到控制台上。因此,这种模式特别适用于交互式执行(REPL),spark-shell就是这种模式。
当然,你也可以从距离工作节点很远的机器(如:你的笔记本)上提交应用,这种情况下,通常适用cluster模式,以减少网络驱动器和执行器之间的网络通信延迟。注意:对于Mesos集群管理器,Spark还不支持cluster模式。目前,只有YARN上Python应用支持cluster模式。
对于Python应用,只要把<application-jar>换成一个.py文件,再把.zip、.egg或者.py文件传给–py-files参数即可。
有一些参数是专门用于设置集群管理器的(cluster manager)。例如,在独立部署( Spark standalone cluster )时,并且使用cluster模式,你可以用–supervise参数来确保驱动器在异常退出情况下(退出并返回非0值)自动重启。spark-submit –help可查看完整的选项列表。
这里有几个常见的示例:
# 本地运行,占用8个core ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[8] \ /path/to/examples.jar \ 100 # 独立部署,client模式 ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # 独立部署,cluster模式,异常退出时自动重启 ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --deploy-mode cluster --supervise --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # YARN上运行,cluster模式 export HADOOP_CONF_DIR=XXX ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ # 要client模式就把这个设为client --executor-memory 20G \ --num-executors 50 \ /path/to/examples.jar \ 1000 # 独立部署,运行python ./bin/spark-submit \ --master spark://207.184.161.138:7077 \ examples/src/main/python/pi.py \ 1000 # Mesos集群上运行,cluster模式,异常时自动重启 ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master mesos://207.184.161.138:7077 \ --deploy-mode cluster --supervise --executor-memory 20G \ --total-executor-cores 100 \ http://path/to/examples.jar \ 1000
Master URLs
传给Spark的master URL可以是以下几种格式:
local #本地运行Spark,只用1个worker线程(没有并行计算)
local[K] #本地运行Spark,使用K个worker线程(理论上,最好将这个值设为你机器上CPU core的个数)
local[*] #本地运行Spark,使用worker线程数同你机器上逻辑CPU core个数
spark://HOST:PORT #连接到指定的Spark独立部署的集群管理器(Spark standalone cluster)。端口是可以配置的,默认7077。
mesos://HOST:PORT #连接到指定的Mesos集群。端口号可以配置,默认5050。如果Mesos集群依赖于ZooKeeper,可以使用 mesos://zk://… 来提交,注意 –deploy-mode需要设置为cluster,同时,HOST:PORT应指向 MesosClusterDispatcher.
yarn #连接到指定的 YARN 集群,使用–deploy-mode来指定 client模式 或是 cluster 模式。YARN集群位置需要通过 $HADOOP_CONF_DIR 或者 $YARN_CONF_DIR 变量来查找。
yarn-client #YARN client模式的简写,等价于 –master yarn –deploy-mode client
yarn-cluster #YARN cluster模式的简写,等价于 –master yarn –deploy-mode cluster
高级依赖管理
通过spark-submit提交应用时,application jar和–jars选项中的jar包都会被自动传到集群上。Spark支持以下URL协议,并采用不同的分发策略:
file: – 文件绝对路径,并且file:/URI是通过驱动器的HTTP文件服务器来下载的,每个执行器都从驱动器的HTTP server拉取这些文件。 hdfs:, http:, https:, ftp: – 设置这些参数后,Spark将会从指定的URI位置下载所需的文件和jar包。 local: – local:/ 打头的URI用于指定在每个工作节点上都能访问到的本地或共享文件。这意味着,不会占用网络IO,特别是对一些大文件或jar包,最好使用这种方式,当然,你需要把文件推送到每个工作节点上,或者通过NFS和GlusterFS共享文件。
注意,每个SparkContext对应的jar包和文件都需要拷贝到所对应执行器的工作目录下。一段时间之后,这些文件可能会占用相当多的磁盘。在YARN上,这些清理工作是自动完成的;而在Spark独立部署时,这种自动清理需要配置 spark.worker.cleanup.appDataTtl 属性。
用户还可以用–packages参数,通过给定一个逗号分隔的maven坐标,来指定其他依赖项。这个命令会自动处理依赖树。额外的maven库(或者SBT resolver)可以通过–repositories参数来指定。Spark命令(pyspark,spark-shell,spark-submit)都支持这些参数。
对于Python,也可以使用等价的–py-files选项来分发.egg、.zip以及.py文件到执行器上。
博文来自:www.51niux.com
2.11 Wordcount测试
#如果想用spark自带的workcount也像hadoop一样测试一下的话,可以执行下面的命令。
$ spark-submit \ --class org.apache.spark.examples.JavaWordCount \ --master spark://master.hadoop:7077,slave01.hadoop:7077 \ /home/hadoop/spark/examples/jars/spark-examples_2.11-2.1.1.jar \ hdfs://mycluster:8020/test2/lzotest.log #这里找的分析文件就是hdfs上面的,也可以写成/test2/lzotest.log,这里并不是找的本地文件而是hdfs上面的文件
#默认的输出结果是输出到屏幕的,类似于下面这种(key:value)的形式
123.52.23.217: 55 27.152.90.163: 330

#从Web端可以看到App的名称变味了JavaWorkCount而不是Spark Pi了。

#shuffle解释:http://blog.csdn.net/u012684933/article/details/49074185
#shuffler调优:https://tech.meituan.com/spark-tuning-pro.html
三、基于Zookeeper集群搭建Spark HA
zookeeper集群的搭建:http://www.51niux.com/?id=182
#参考链接最后部分:http://spark.apache.org/docs/2.1.1/spark-standalone.html
3.1 修改spark相关配置
$ vim /home/hadoop/spark/conf/spark-env.sh
#export SPARK_MASTER_IP=master.hadoop export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=slave04.hadoop:2181,slave05.hadoop :2181,slave06.hadoop -Dspark.deploy.zookeeper.dir=/spark"
#把/home/hadoop/spark/conf/spark-env.sh文件同步到所有节点
3.2 启动服务
$/home/hadoop/spark/sbin/stop-all.sh #这是在mater.hadoop节点的操作
$/home/hadoop/spark/sbin/start-all.sh #这是在mater.hadoop节点的操作
$ /home/hadoop/spark/sbin/start-master.sh #这是在slave01.hadoop节点上面的操作
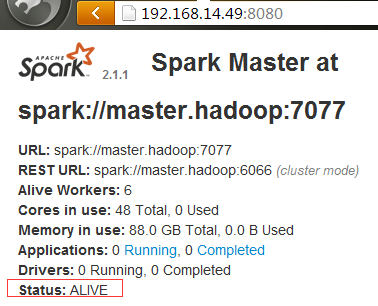
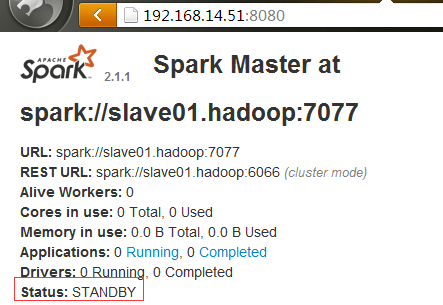
#从上面两张图可以看到主从效果出现了。
博文来自:www.51niux.com
3.3 HA切换测试:
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://master.hadoop:7077,slave01.hadoop:7077 /home/hadoop/spark/examples/jars/spark-examples_2.11-2.1.1.jar 100
#因为现在是两个Master节点,所以这里要做些调整:spark://master.hadoop:7077,slave01.hadoop:7077,指定两个主机的端口
#现在在master.hadoop节点上面执行:
[hadoop@master ~]$ /home/hadoop/spark/sbin/stop-master.sh
$ jps #可以看到已经没有Master进程
3313 JournalNode 28547 Jps 6483 DFSZKFailoverController 6100 NameNode
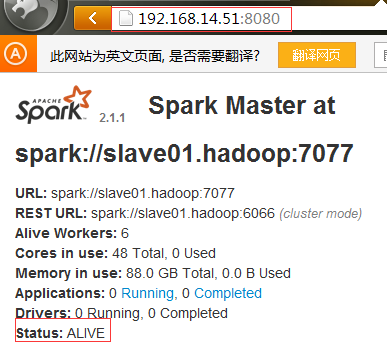
#可以看到slave01.hadoop已经变为了主节点了。
$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://master.hadoop:7077,slave01.hadoop:7077 /home/hadoop/spark/examples/jars/spark-examples_2.11-2.1.1.jar 10000
17/11/15 23:46:51 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 17/11/15 23:46:51 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 73.878 s 17/11/15 23:46:51 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 74.782092 s Pi is roughly 3.141570859141571 17/11/15 23:46:51 INFO SparkUI: Stopped Spark web UI at http://192.168.14.52:4046 17/11/15 23:46:51 INFO StandaloneSchedulerBackend: Shutting down all executors 17/11/15 23:46:51 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down 17/11/15 23:46:51 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 17/11/15 23:46:51 INFO MemoryStore: MemoryStore cleared 17/11/15 23:46:51 INFO BlockManager: BlockManager stopped 17/11/15 23:46:51 INFO BlockManagerMaster: BlockManagerMaster stopped 17/11/15 23:46:51 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 17/11/15 23:46:51 INFO SparkContext: Successfully stopped SparkContext 17/11/15 23:46:51 INFO ShutdownHookManager: Shutdown hook called 17/11/15 23:46:51 INFO ShutdownHookManager: Deleting directory /home/hadoop/spark-2.1.1-bin-hadoop2.7/spark-b80dbfb1-a4a1-4e58-a0aa-31e992d6bdde
#从上图可以看到执行依旧是没问题的,就将任务交给了第二个节点。这个任务是在哪个节点执行哪个节点就会启4046端口。
$ jps #CoarseGrainedExecutorBackend在spark运行期是一个单独的进程,在Worker节点可以通过Java的jps命令查看
21552 CoarseGrainedExecutorBackend
#Executor负责计算任务,即执行task,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的
博文来自:www.51niux.com
四、Spark History Server配置使用
以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息;但该WEBUI随着Application的完成(成功/失败)而关闭,也就是说,Spark Application运行完(成功/失败)后,将无法查看Application的历史记录;
Spark history Server就是为了应对这种情况而产生的,通过配置可以在Application执行的过程中记录下了日志事件信息,那么在Application执行结束后,WEBUI就能重新渲染生成UI界面展现出该Application在执行过程中的运行时信息;
Spark运行在yarn或者mesos之上,通过spark的history server仍然可以重构出一个已经完成的Application的运行时参数信息(假如Application运行的事件日志信息已经记录下来);
启动Spark History:
$ /home/hadoop/spark/sbin/start-history-server.sh #在master节点+先试着启动一下
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-slave01.hadoop.out failed to launch: nice -n 0 /home/hadoop/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer at org.apache.spark.deploy.history.FsHistoryProvider.org$apache$spark$deploy$history$FsHistoryProvider$$startPolling(FsHistoryProvider.scala:204) ... 9 more full log in /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-slave01.hadoop.out
#上面执行报错了,需要在执行的时候需要在启动时指定目录。
$ hadoop fs -mkdir hdfs://mycluster:8020/spark_history #spark_history目录要提前存在不然启动也是要报错的
$ /home/hadoop/spark/sbin/start-history-server.sh hdfs://mycluster:8020/spark_history #启动的时候指定目录
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/hadoop/spark/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-slave01.hadoop.out
#在master节点查看一下

#18080端口启动起来了
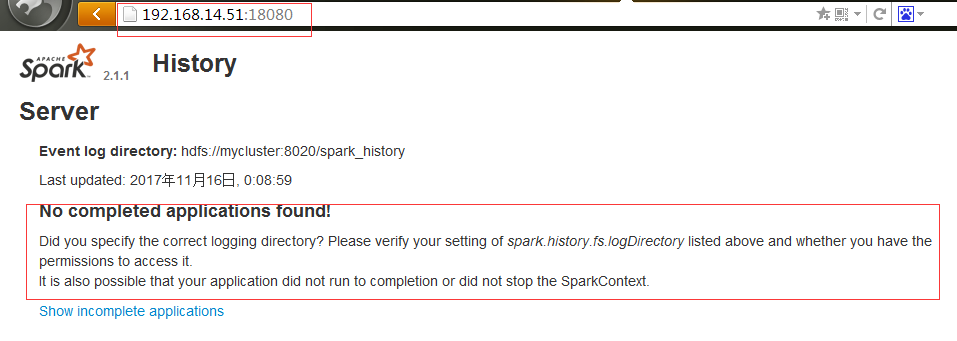
No completed applications found! Did you specify the correct logging directory? Please verify your setting of spark.history.fs.logDirectory listed above and whether you have the permissions to access it. It is also possible that your application did not run to completion or did not stop the SparkContext.
#默认是IP:18080,web页面能出来了,但是还是存在问题。
配置Spark:
$ vim /home/hadoop/spark/conf/spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs ://mycluster:8020/spark_history"
#这是表示ui端口还是18080,application的记录超过3份就会删除旧的,历史记录的存放位hdfs://mycluster:8020/spark_history
$ vim /home/hadoop/spark/conf/spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://mycluster:8020/spark_history #时间都存在这个目录中 #spark.eventLog.compress true #这个是启用压缩,可以不启用
#然后把配置文件同步到所有集群,重启spark服务(Master和Worker服务都要重新启动)
$ /home/hadoop/spark/sbin/stop-history-server.sh #在master节点重启history服务
$ /home/hadoop/spark/sbin/start-history-server.sh
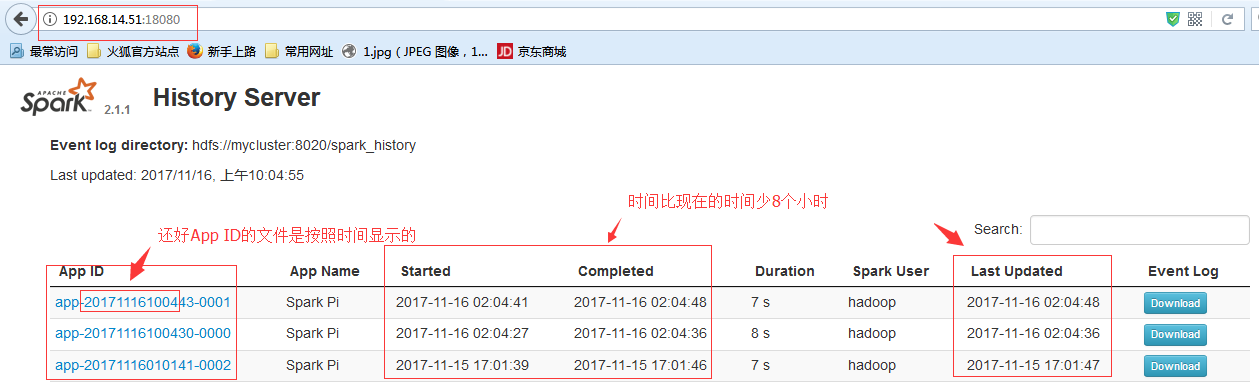
# 使用spark-submit提交一个作业,保证SparkContext调用了stop方法,否则History Server不会显示历史信息
#已经可以看到历史记录了。当然还存在一个问题,这个web ui节点显示的时间是0时区而非东八区,所以你还得时间+8,才是你真正执行这个Job的任务。可以以App ID为执行时间的依据它是对的。

#因为是取的存的在HDFS里面的日志信息。

#加了压缩之后的效果,存储的空间还是差很多的。
#不过我线上并没有启用History进程,我觉得就算启用的话,也别往HDFS里面存啊,HDFS本身是存储大文件的,存这么多小日志没啥意思,日志可以挂个共享盘之类的存储在那上面也挺好的我个人觉得。
五、Spark UI界面实例查看:
#4040端口是查看实时的,18080是查看历史的,意思都差不多,都是把执行过程中产生的日志存储到文件中,然后web ui调用文件里面的内容显示。
默认情况下,当一个Spark Application运行起来后,可以通过访问hostname:4040端口来访问UI界面。hostname是提交任务的Spark客户端ip地址,端口号由参数spark.ui.port(默认值4040,如果被占用则顺序往后探查)来确定。 由于启动一个Application就会生成一个对应的UI界面,所以如果启动时默认的4040端口号被占用,则尝试4041端口,如果还是被占用则尝试4042,一直找到一个可用端口号为止。
#这里就以18080的历史服务的UI界面来阐述一下。

查看这个Spark程序启动几个Job:
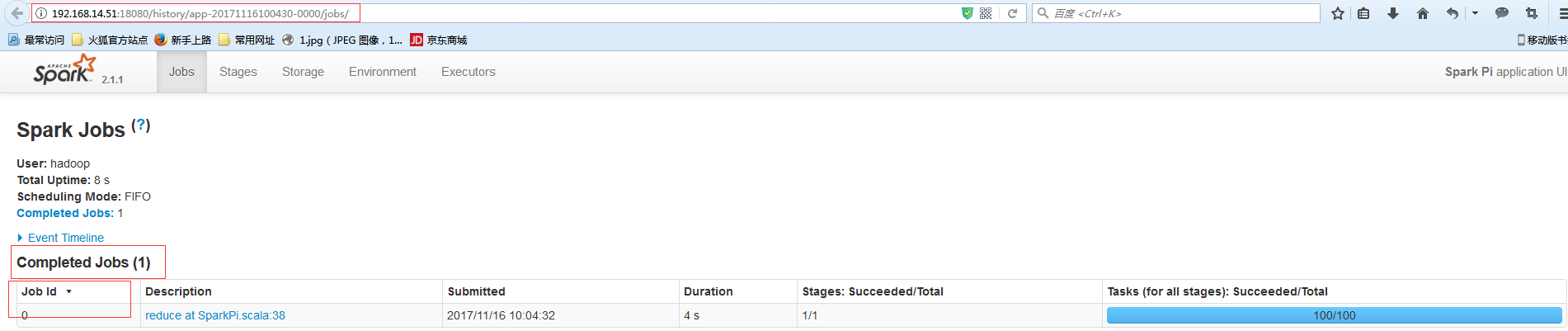
#可以看到Job id为0,说明就启动了一个Job。可以直接web:http://192.168.14.51:18080/history/app-20171116100430-0000/jobs/ #这种形式来查看
#也可以看到一个Job包含了一个Stages,状态也是成功的.并且包含了100个task。运行时间是4S.提交时间是2017/11/16 10:04:32
查看这个Spark程序一共运行了多少Stages:
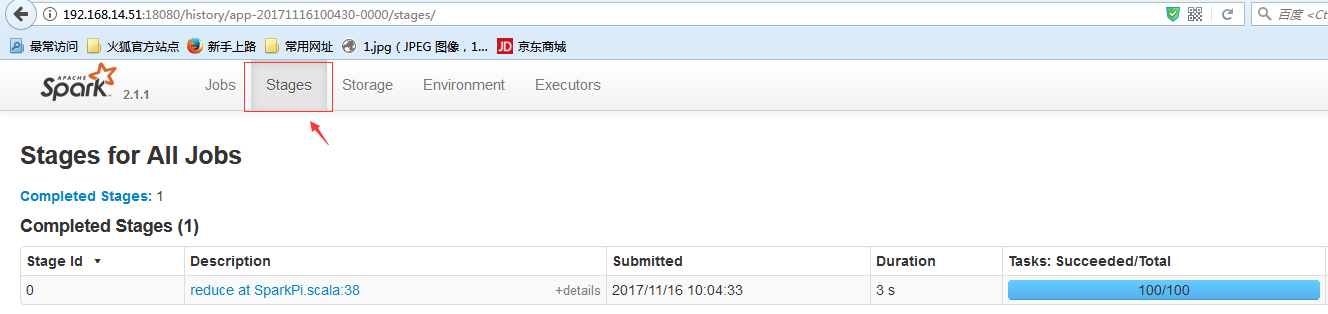
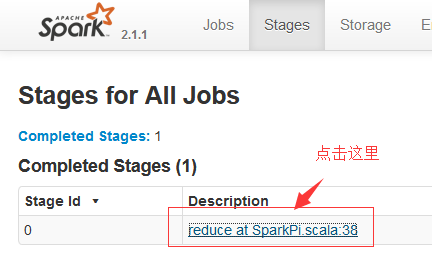
查看Stages的详细信息:
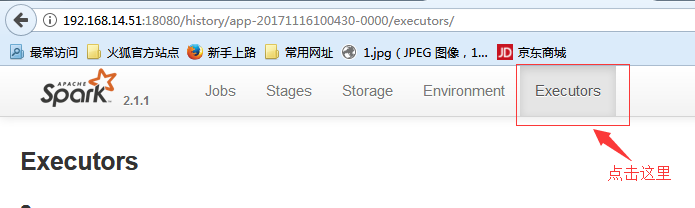
Spark程序是几个Executor执行完成的:
#Spark Master、Worker、Driver、Executor工作流程详解: http://blog.csdn.net/zhumr/article/details/52518506
#Spark stage划分原理 : http://litaotao.github.io/deep-into-spark-exection-model
六、Spark与Hive整合
http://www.51niux.com/?id=189 #已经介绍了hive的部署搭建,hive2.0没有介绍有很大改变,可上网查看其它的博客。
在大数据应用场景下,使用过Hive做查询统计分析的应该知道,计算的延迟性非常大,可能一个非常复杂的统计分析需求,需要运行1个小时以上,但是比之于使用MySQL之类关系数据库做分析,执行速度快很多很多。使用HiveQL写类似SQL的查询分析语句,最终经过Hive查询解析器,翻译成Hadoop平台上的MapReduce程序进行运行,这也是MapReduce计算引擎的特点带来的延迟问题:Map中间结果写文件。如果一个HiveQL语句非常复杂,会被翻译成多个MapReduce Job,那么就会有很多的Map输出中间结果数据到文件中,基本没有数据的共享。
如果使用Spark计算平台,基于Spark RDD数据集模型计算,可以减少计算过程中产生中间结果数据写文件的开销,Spark会把数据直接放到内存中供后续操作共享数据,减少了读写磁盘I/O操作带来的延时。另外,如果基于Spark on YARN部署模式,可以充分利用数据在Hadoop集群DataNode节点的本地性(Locality)特点,减少数据传输的通信开销。
6.1 配置spark可以使用hive
配置spark的hive-site.xml文件:
# vim /home/hadoop/spark/conf/hive-site.xml #这个客户端文件不配置文件,执行spark-sql肯定是不行的,就不截图了
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://master.hadoop:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> <!--绑定运行HiveServer2 Thrift服务的主机。--> <!--property> <name>hive.server2.thrift.bind.host</name> <value>smaster.hadoop</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <!--当hive.server2.transport.mode是'binary'时,HiveServer2 Thrift接口的端口号。--> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> <!--最小工作线程数,默认为5--> <property> <name>hive.server2.thrift.min.worker.threads</name> <value>5</value> <description>Minimum number of Thrift worker threads</description> </property> <!--最大的工作线程数,默认为500--> <property> <name>hive.server2.thrift.max.worker.threads</name> <value>500</value> <description>Maximum number of Thrift worker threads</description> </property--> </configuration>
$ /home/hadoop/spark/sbin/stop-slave.sh
$ /home/hadoop/spark/sbin/start-slave.sh localhost #重启一下服务
$ /home/hadoop/spark/bin/spark-sql --master spark://master.hadoop:7077,slave01.hadoop:7077
17/11/21 17:21:13 INFO metastore: Trying to connect to metastore with URI thrift://master.hadoop:9083 17/11/21 17:21:13 INFO metastore: Connected to metastore. 17/11/21 17:21:13 INFO SessionState: Created local directory: /tmp/41d50f55-e6bc-453f-bb5b-781c35fd7504_resources 17/11/21 17:21:13 INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/41d50f55-e6bc-453f-bb5b-781c35fd7504 17/11/21 17:21:13 INFO SessionState: Created local directory: /tmp/hadoop/41d50f55-e6bc-453f-bb5b-781c35fd7504 17/11/21 17:21:13 INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/41d50f55-e6bc-453f-bb5b-781c35fd7504/_tmp_space.db 17/11/21 17:21:13 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.1) is file:/home/hadoop/spark-warehouse/ 17/11/21 17:21:13 INFO SessionState: Created local directory: /tmp/19135c20-2dab-478d-ae2c-9356ad611a8a_resources 17/11/21 17:21:13 INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/19135c20-2dab-478d-ae2c-9356ad611a8a 17/11/21 17:21:13 INFO SessionState: Created local directory: /tmp/hadoop/19135c20-2dab-478d-ae2c-9356ad611a8a 17/11/21 17:21:14 INFO SessionState: Created HDFS directory: /tmp/hive/hadoop/19135c20-2dab-478d-ae2c-9356ad611a8a/_tmp_space.db 17/11/21 17:21:14 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.1) is file:/home/hadoop/spark-warehouse/ spark-sql>
#可以了但是存在一个问题,上面那一大票输出,而且每次操作都会有一大票的输出,不行得精简输出。
配置log4j精简输出:
$ vim /home/hadoop/spark/conf/log4j.properties
#log4j.rootCategory=INFO, console log4j.rootCategory=ERROR, console #log4j.logger.org.spark_project.jetty=WARN log4j.logger.org.spark_project.jetty=ERROR
spark-sql> show databases; #没有日志输出了
default sparktest Time taken: 4.395 seconds, Fetched 2 row(s) spark-sql> use default; Time taken: 1.24 seconds spark-sql> show tables; Time taken: 0.229 seconds
6.2 连接Hive
使用pyspark访问hive:
$ bin/pyspark
>>> from pyspark.sql import HiveContext
>>> sqlContext=HiveContext(sc)
>>> results=sqlContext.sql("show databases").show()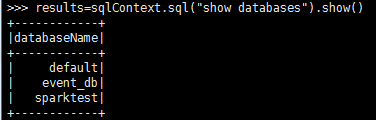
#主要还是通过spark-sql通过把写好的jar包放到hive目录下的lib目录下面,然后调用jar包的形式来写脚本定时的执行任务。输出结果就类似下面那种会标识是sparksql。

