Hadoop(四)增加/删除节点与安全模式
hadoop使用的是HDFS分布式文件系统,既然是存储就可能要面临存储节点磁盘使用达到预警值的情况,当出现这种情况的时候,要么你就清理一下,那么就要新增数据存储节点了,这两种方式我们都采取过.
一、增加datanode节点
1.1 静态添加
静态新增的方式,就相当于一开始部署hdfs集群规划一样,停止NameNode服务,新增数据节点。下面是操作步骤:
停止服务(namenode节点操作)
$ /home/hadoop/hadoop/sbin/stop-all.sh
修改配置文件slaves文件(namenode节点操作)
$ cd /home/hadoop/hadoop
$ vim etc/hadoop/slaves
slave01.hadoop slave02.hadoop slave03.hadoop slave04.hadoop slave05.hadoop #新增这个节点
$ vim /etc/hosts
192.168.14.49 master.hadoop 192.168.14.50 smaster.hadoop 192.168.14.51 slave01.hadoop 192.168.14.52 slave02.hadoop 192.168.14.53 slave03.hadoop 192.168.14.54 slave04.hadoop 192.168.14.55 slave05.hadoop #新增这条解析记录
新增datanode节点上面的操作
#关闭防火墙,selinux,然后时间哪些应该在初始化的时候就做了哈
#格式化磁盘、挂载盘到对应目录,添加开机启动啥的也应该都做好了哈
#useradd -u 2527 hadoop
# chown hadoop:hadoop /etc/hosts
# yum install rsync -y #如果没有就要安装一下
# hostnamectl set-hostname slave05.hadoop
# echo "51niux.com"|passwd --stdin hadoop
# rpm -ivh jdk-8u74-linux-x64.rpm
# ln -s /usr/java/jdk1.8.0_74 /usr/java/jdk
# vi /etc/profile
###########java############################
export JAVA_HOME=/usr/java/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=$JAVA_HOME/lib/*.jar:$JAVA_HOME/jre/lib/*.jar
#############hadoop##########################################
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin/:$HADOOP_HOME/bin/# source /etc/profile
namenode节点上面对新增datanode节点的操作
#su - hadoop #保证自己是hadoop用户
$ ssh-copy-id slave05.hadoop #跟新增节点建立ssh无密钥登录
$ rsync -avz /home/hadoop/hadoop slave05.hadoop:/home/hadoop/ #这是把软连接同步过去
$ rsync -avz /home/hadoop/hadoop-2.7.4 slave05.hadoop:/home/hadoop/ #这是把hadoop目录同步过去
$ scp /etc/hosts slave05.hadoop:/etc/
# scp -r /usr/local/lzo-2.06 slave05.hadoop:/usr/local/ #其实lzo这个目录放到hadoop目录更好,这样就不用root权限拷贝一下了。
namenoede节点向其他旧的节点同步操作
$ scp /home/hadoop/hadoop/etc/hadoop/slaves slave01.hadoop:/home/hadoop/hadoop/etc/hadoop/
$ scp /home/hadoop/hadoop/etc/hadoop/slaves slave02.hadoop:/home/hadoop/hadoop/etc/hadoop/
$ scp /home/hadoop/hadoop/etc/hadoop/slaves slave03.hadoop:/home/hadoop/hadoop/etc/hadoop/
$ scp /home/hadoop/hadoop/etc/hadoop/slaves slave04.hadoop:/home/hadoop/hadoop/etc/hadoop/
$ scp /etc/hosts slave01.hadoop:/etc/
$ scp /etc/hosts slave02.hadoop:/etc/
$ scp /etc/hosts slave03.hadoop:/etc/
$ scp /etc/hosts slave04.hadoop:/etc/
启动节点服务器(namenode节点上面的操作)
$ /home/hadoop/hadoop/sbin/start-all.sh
在namenode节点查看一下
$ hdfs dfsadmin -report|grep slave
#从上图可以看到新增的节点已经存在集群中了。
新增节点上面查看一下
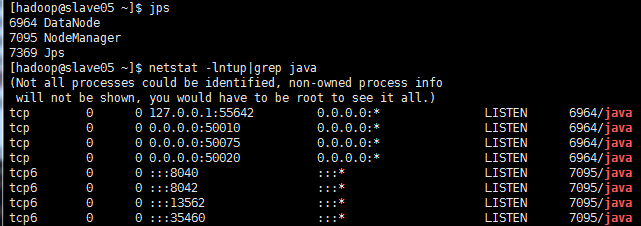
web节点查看一下
url:http://192.168.14.49:50070/dfshealth.html#tab-datanode

#可见新增节点已经没有问题了,就是没有数据而已。
博文来自:www.51niux.com
1.2 动态增加
操作跟上面的静态添加基本一致,就是namenode不执行$ /home/hadoop/hadoop/sbin/stop-all.sh ,当然也就没有执行:$ /home/hadoop/hadoop/sbin/start-all.sh
#也就是说在不关闭集群服务,不重启服务器的情况下,动态的添加一台datanode节点。
#现在新增一个slave06.hadoop节点,操作跟slave05.hadoop节点一致,namenode节点除了不做服务关闭和启动操作外剩下的操作也一致。
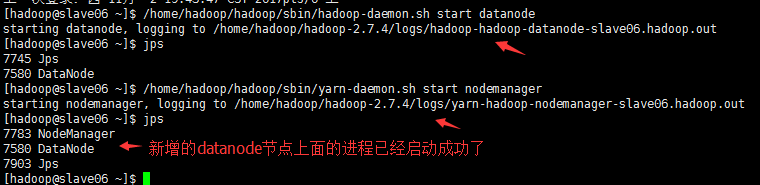
新增节点上面启动服务:
#su - hadoop
$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh start datanode
$ /home/hadoop/hadoop/sbin/yarn-daemon.sh start nodemanager
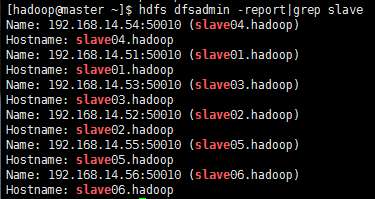
namenode节点上面查看:
$ hdfs dfsadmin -report|grep slave
web上面查看:
url:http://192.168.14.49:50070/dfshealth.html#tab-datanode
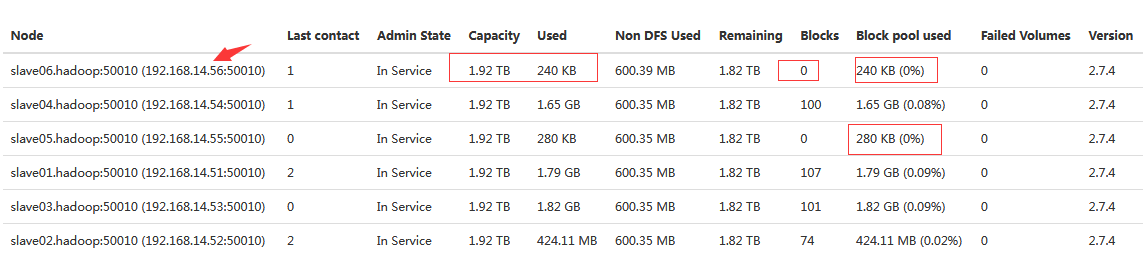
#web上面也看到了新增的datanode节点。
url:http://192.168.14.49:8088/cluster/nodes
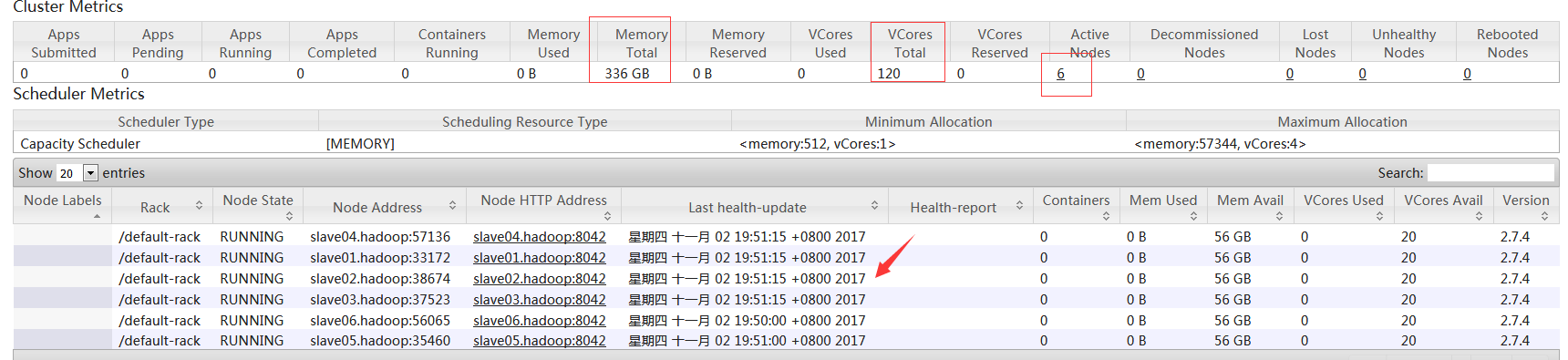
#可以看到mapreduce集群里面也可以看到新增的两台节点了。
1.3 balance进行block块的均衡
添加新节点时,HDFS不会自动重新平衡。然而,HDFS提供了一个手动调用的重新平衡(reblancer)工具。这个工具将整个集群中的数据块分布调整到一个可人工配置的百分比阈值。如果在其他现有的节点上有空间存储问题,再平衡就会根据阀值,然后平衡分布数据。
如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低Map Reduce的工作效率。 threshold是平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长 。
balance命令可以在namenode或者datanode上启动,也可以随时利用stop-balance.sh脚本停止平衡.
均衡的带宽速率在hdfs-site.xml的dfs.balance.bandwidthPerSec参数定义了,单位是bytes。
在namenode节点上面执行命令进行均衡:
$ /home/hadoop/hadoop/sbin/start-balancer.sh #这里选用默认进行数据平衡了。
$ /home/hadoop/hadoop/sbin/start-balancer.sh -threshold 1
#因为我们数据了比较少,datanode节点之间的数据占用率并没有相差10%,所以用默认的没啥效果,我们用1%走一波。
starting balancer, logging to /home/hadoop/hadoop-2.7.4/logs/hadoop-hadoop-balancer-master.hadoop.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
#上面是执行完命令之后的提示,可以看出已经开始移动了。这时候你在执行start-balancer.sh会提示你已经有进程了,当然可以执行$ /home/hadoop/hadoop/sbin/stop-balancer.sh 来停止均衡
$ jps #查看一下进程
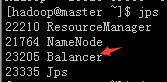
#从上图可以看到namenode节点启动了一个Balancer进程。数据均衡完,这个进程自然就消失了。
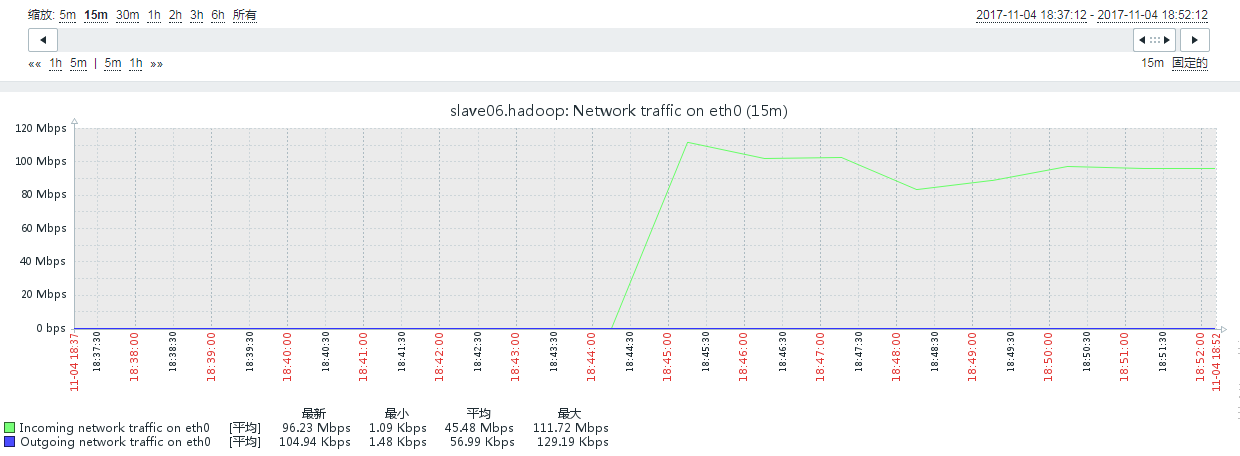
#从zabbix图也可以看到新增加的这个节点已经开始有大量的流入流量了。说明集群开始往这个节点上面迁移数据。
$ tail -f /home/hadoop/hadoop/logs/hadoop-hadoop-balancer-master.hadoop.log #当然也可以查看日志信息
2017-11-04 19:01:41,693 INFO org.apache.hadoop.hdfs.server.balancer.Dispatcher: Successfully moved blk_1073743371_2552 with size=67108864 from 192.168.14.52:50010:DISK to 192.168.14.56:50010:DISK through 192.168.14.54:50010 2017-11-04 19:01:41,694 INFO org.apache.hadoop.hdfs.server.balancer.Dispatcher: Start moving blk_1073743266_2447 with size=67108864 from 192.168.14.52:50010:DISK to 192.168.14.56:50010:DISK through 192.168.14.51:50010 2017-11-04 19:01:42,849 INFO org.apache.hadoop.hdfs.server.balancer.Dispatcher: Successfully moved blk_1073743356_2537 with size=67108864 from 192.168.14.52:50010:DISK to 192.168.14.56:50010:DISK through 192.168.14.52:50010 2017-11-04 19:01:42,849 INFO org.apache.hadoop.hdfs.server.balancer.Dispatcher: Start moving blk_1073743500_2681 with size=67108864 from 192.168.14.52:50010:DISK to 192.168.14.56:50010:DISK through 192.168.14.51:50010
#需要注意的地方是,由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,一般这个时间会比较长,所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
#如果某个datanode节点上面的某块硬盘坏掉了,那么此坏盘的datanode也会退出集群(因为hadoop默认对磁盘损坏是0容忍的,默认参数是dfs.datanode.failed.volumes.tolerated 0 ,也就是任何一个卷损坏真个数据节点就会宕掉),等更换硬盘之后,再启动datanode此节点上的服务就会又加回集群中,这时候我一般都是手工执行一下balancer让其进行下均衡服务,当然这块更换的盘空间占用会比别的盘要低,不过后面慢慢就赶上来了。
blance的详细均衡过程可以参照:http://www.cnblogs.com/xjh713/p/6909339.html
博文来自:www.51niux.com
二、删除datanode节点
2.1 静态删除节点操作
$ /home/hadoop/hadoop/sbin/stop-all.sh
$ vim hadoop/etc/hadoop/slaves #如去掉slave06.hadoop节点
slave01.hadoop slave02.hadoop slave03.hadoop slave04.hadoop slave05.hadoop
$ /home/hadoop/hadoop/sbin/start-all.sh
2.2 动态删除节点操作
namenode节点操作:
$ vim /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml #加上下面一段配置
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/etc/hadoop/excludes</value> </property>
$ vim /home/hadoop/hadoop/etc/hadoop/mapred-site.xml #加上下面一段配置
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/etc/hadoop/excludes</value> </property>
================小插一下=================================
#我们以前在使用1.0的时候一般都会在配置文件里面定义上include和excludes,当然有需要才会去创建对应的文件。如我们的配置:
<!-- datanode list --> <property> <name>dfs.hosts</name> <value>/opt/hadoop/conf/datanode-include</value> </property> <property> <name>dfs.hosts.exclude</name> <value>/opt/hadoop/conf/datanode-exclude</value> </property>
================请继续浏览================================
$ vim /home/hadoop/hadoop/etc/hadoop/excludes #定义在这里的主机将阻止他们去连接Namenode也就是踢出集群了
slave05.hadoop
$ hadoop dfsadmin -refreshNodes #强制重新加载配置,下面是提示,表示执行成功了。
DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Refresh nodes successful
$ hadoop dfsadmin -report|grep -A 5 slave05.hadoop #查看一下报告信息,发现slave05变成了Decommissioned状态
DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Name: 192.168.14.55:50010 (slave05.hadoop) Hostname: slave05.hadoop Decommission Status : Decommissioned #可以看到是退役状态了 Configured Capacity: 2112439992320 (1.92 TB) DFS Used: 344064 (336 KB) Non DFS Used: 629514240 (600.35 MB) DFS Remaining: 2004268179456 (1.82 TB)
#注意并不是一下进入退役状态的,会进行数据块的迁移,会从 Normal到decomissioning 向 Decommissioned转变。请看下图:![]()

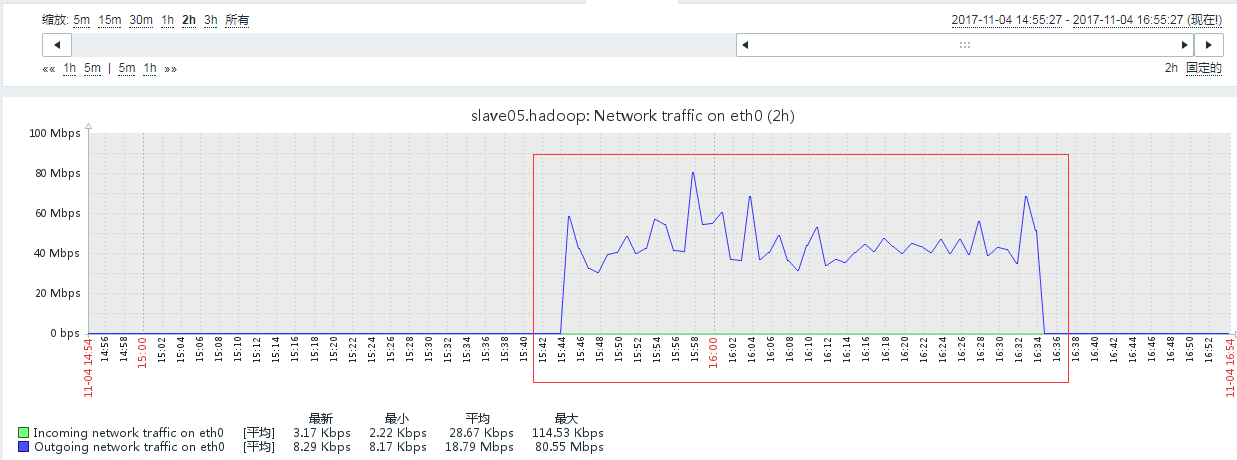
#从上面两张图可以看出,当节点被退役的时候并不会立马进入退役状态,会把先自己节点上面的块迁移到其他节点上面,从zabbix的流量图也可以看出之前没啥流量,当被执行退役操作的时候有大量的流出操作,可能这个时间会比较久。
#decommission方式修改了hdfs-site文件,未修改slave文件。 所以集群重启时,该节点虽然会被启动为datanode,但是由于添加了exclude,所以namenode会将该节点置为decommission。 此时namenode不会与该节点进行hdfs相关通信。也即exclude起到了一个防火墙的作用。
#如果在某个节点单独停止datanode,那么在namenode的统计中仍会出现该节点的datanode信息。 此时可通过dead或者decommission(退役)方式下线机器。
#如果是新退役的节点想再添加回集群中,可以将其从exclude文件中移除,然后再执行$ hadoop dfsadmin -refreshNodes 就可。
datanode节点(slave05.hadoop)的操作(已经是退役状态的操作):
$ /home/hadoop/hadoop/sbin/hadoop-daemon.sh stop datanode
$ /home/hadoop/hadoop/sbin/yarn-daemon.sh stop nodemanager
$ jps #查看一下已经没有了进程
19185 Jps
通过Web查看:

#如果旧的节点磁盘占用率太高了,几乎要满了。可以在加入新机器后,对旧节点使用Decommission的方式,然后旧的节点格式化磁盘再加入集群的方式来做,这样效率会更一点。这种思路来源于:http://heylinux.com/archives/3392.html
博文来自:www.51niux.com
三、Hadoop安全模式
3.1 Hadoop为什么重启会进入安全模式?
解释安全模式
Hadoop的NameNode在重启的时候,会进入安全模式。在安全模式下,HDFS只支持访问元数据的操作也就是支持读操作,其他的操作如创建、删除文件等操作都会失败。直到安全模式结束,才能允许HDFS文件系统内容的更改。
安全模式主要是为了系统启动的时候检查各个DataNone上数据块的有效性,同时根据策略必要的复制或删除部分数据块。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动退出安全模式。
默认副本率是0.999,也就是你是3个副本,就要存在三个副本分布在datanode节点上,如果集群中副本数不够的话,系统会自动复制副本到其他datanode节点,争取最小副本率>=0.999.如果系统副本率超了,比如系统中有5个副本了,系统会删除多于的3个副本。
测试安全模式:
现在我们把我们上面踢掉的节点重新加回集群中,来查看一下:
#把slave05.hadoop从excludes文件中移除。
$ /home/hadoop/hadoop/sbin/stop-all.sh
$ /home/hadoop/hadoop/sbin/start-all.sh
$ hadoop dfsadmin -safemode get #获取当前是否处于安全模式状态
DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Safe mode is ON #说明处在安全模式状态
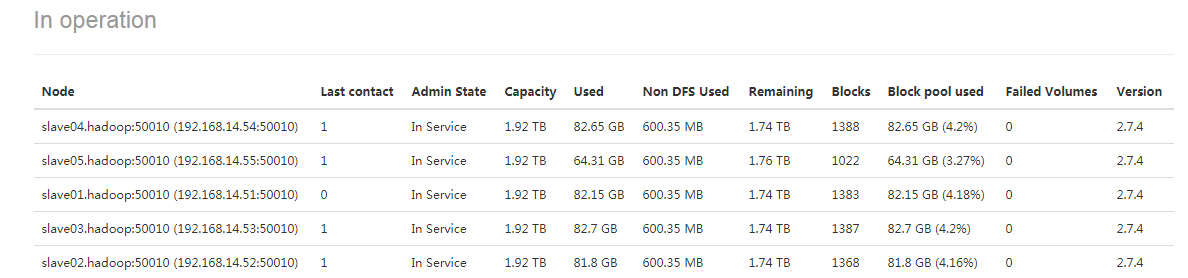
#这个图有点抓晚了,这是集群启动了才抓的,可以注意下slave04和slave01的使用量。

#这是退出安全模式状态后节点存储状态,可以发现slave04和slave03的磁盘使用量减少了很多还是比较明显的,这就说明了如果在Namenode重新启动的时候,如果集群中某些副本数大于定义的副本数的话,就会删除多于副本。(我们上面不是把slave05.hadoop动态剔除集群了嘛,然后数据也没清就又丢回集群了,所以好多数据块的副本数应该是4而非3,所以会删除一些)
 3.2 如何查看自己还有多长时间退出安全模式呢?
3.2 如何查看自己还有多长时间退出安全模式呢?
可以通过web页面,如:http://192.168.14.49:50070
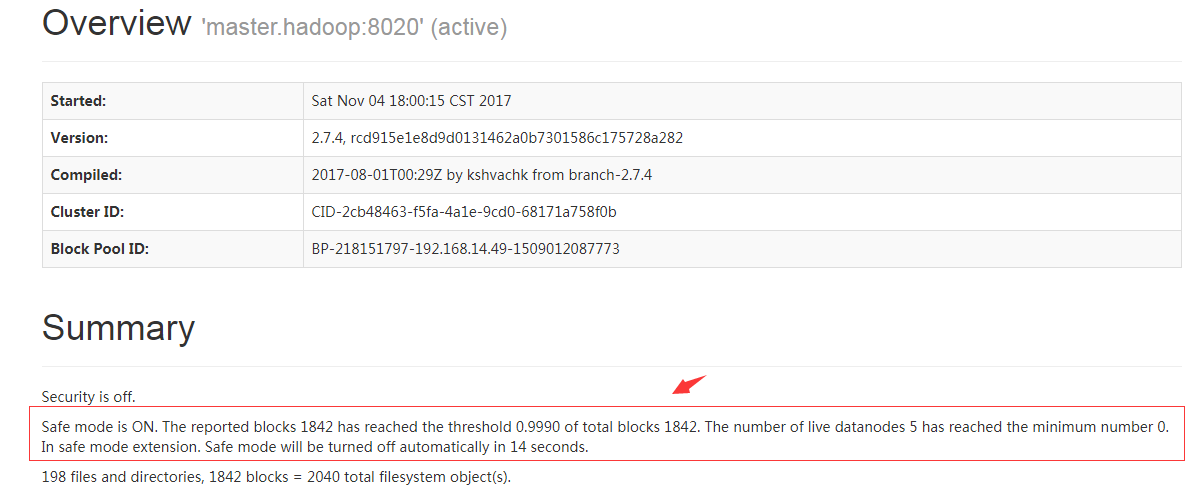
#上面红括号里面的内容会看到还有多少秒退出安全模式。
3.3 那么相关的操作命令有哪些呢?
dfsadmin -safemode <command> #command有以下取值
get #查看当前状态 enter #进入安全模式 leave #强制离开安全模式 wait #一直等待直到安全模式结束
#hadoop fs -safemode enter #手动进入安全模式对于集群维护或者升级的时候非常有用,因为这时候HDFS上的数据是只读的。
3.4 配置文件哪些参数会影响到安全模式?
参考官网:http://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
dfs.namenode.replication.min #指定数据块要达到的最小副本数,默认为1; dfs.namenode.safemode.extension #确定在达到阈值级别后以毫秒为单位的安全模式。默认是30000,也就是30秒。 dfs.namenode.safemode.threshold-pct #指定应满足由dfs.namenode.replication.min定义的最小复制要求的块的百分比。小于或等于0的值表示在退出安全模式之前不等待块的任何特定百分比。 大于1的值将使安全模式永久。默认值是:0.999f dfs.namenode.safemode.min.datanodes #namenode退出安全模式之前有效的(活着的)datanode的数量。这个值小等于0表示在退出安全模式之前无须考虑有效的datanode节点个数,值大于集群中datanode节点总数则表示永远处于安全模式,默认值是0.
如要要参考代码怎么定义的可以看这个链接:http://blog.csdn.net/bingduanlbd/article/details/51900512
