Hadoop(三)hadoop支持lzo
一、集群测试
前面已经记录了集群的搭建以及一些命令的操作。
1.1 在主节点上面查看集群的状态
$ hdfs dfsadmin -report #打印集群的信息
Configured Capacity: 8449759969280 (7.69 TB) Present Capacity: 8017074094080 (7.29 TB) DFS Remaining: 8012713713664 (7.29 TB) DFS Used: 4360380416 (4.06 GB) DFS Used%: 0.05% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 1 ------------------------------------------------- Live datanodes (4): Name: 192.168.14.54:50010 (slave04.hadoop) #就粘贴一个节点了其他的节点信息一样 Hostname: slave04.hadoop Decommission Status : Normal Configured Capacity: 2112439992320 (1.92 TB) DFS Used: 1265725440 (1.18 GB) Non DFS Used: 629514240 (600.35 MB) DFS Remaining: 2003002798080 (1.82 TB) DFS Used%: 0.06% DFS Remaining%: 94.82% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Oct 31 14:00:12 CST 2017
1.2 利用hadoop处理日志文件
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://master.hadoop:8020/songs/logs/songs_2017_10_30.log hdfs://master.hadoop:8020/songs/jieguo/2017_11_1/
#这就是利用hadoop自带的mapreduce的jar包,来做一个简单的wordcount(日志里面各个区域出现的次数),然后指定Input的位置(可以是目录或者文件),输出目录
#下面是正常的输出结果。
17/11/01 16:36:49 INFO client.RMProxy: Connecting to ResourceManager at master.hadoop/192.168.14.49:8032 17/11/01 16:36:50 INFO input.FileInputFormat: Total input paths to process : 1 17/11/01 16:36:50 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/01 16:36:50 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/01 16:36:50 INFO mapreduce.JobSubmitter: number of splits:1 17/11/01 16:36:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1509520940514_0004 17/11/01 16:36:51 INFO impl.YarnClientImpl: Submitted application application_1509520940514_0004 17/11/01 16:36:51 INFO mapreduce.Job: The url to track the job: http://master.hadoop:8088/proxy/application_1509520940514_0004/ 17/11/01 16:36:51 INFO mapreduce.Job: Running job: job_1509520940514_0004 17/11/01 16:36:58 INFO mapreduce.Job: Job job_1509520940514_0004 running in uber mode : false 17/11/01 16:36:58 INFO mapreduce.Job: map 0% reduce 0% 17/11/01 16:37:08 INFO mapreduce.Job: map 100% reduce 0% 17/11/01 16:37:14 INFO mapreduce.Job: map 100% reduce 100% 17/11/01 16:37:15 INFO mapreduce.Job: Job job_1509520940514_0004 completed successfully 17/11/01 16:37:15 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1911258 FILE: Number of bytes written=3125961 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=38312746 HDFS: Number of bytes written=487840 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=34184 Total time spent by all reduces in occupied slots (ms)=13920 Total time spent by all map tasks (ms)=8546 Total time spent by all reduce tasks (ms)=3480 Total vcore-milliseconds taken by all map tasks=8546 Total vcore-milliseconds taken by all reduce tasks=3480 Total megabyte-milliseconds taken by all map tasks=17502208 Total megabyte-milliseconds taken by all reduce tasks=7127040 Map-Reduce Framework Map input records=193111 Map output records=3310184 Map output bytes=51574568 Map output materialized bytes=928920 Input split bytes=122 Combine input records=3310184 Combine output records=131989 Reduce input groups=117471 Reduce shuffle bytes=928920 Reduce input records=131989 Reduce output records=117471 Spilled Records=395967 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=698 CPU time spent (ms)=15630 Physical memory (bytes) snapshot=948539392 Virtual memory (bytes) snapshot=6175174656 Total committed heap usage (bytes)=1162346496 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=38312624 File Output Format Counters Bytes Written=487840

#上图是产生的处理后的文件。
$ hadoop fs -cat /songs/jieguo/2017_11_1/part-r-00000.deflate #用这种形式是不可以的,因为这是一个压缩文件,输出会是乱码。因为使用的默认压缩格式,就是这种后缀。
$ hadoop fs -text /songs/jieguo/2017_11_1/part-r-00000.deflate|more #用-text就可以查看了。

#此图是不适用压缩的结果存储效果,可以看到它的命名和文件大小。这样跟上图有一个对比。
$ hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar #可以看到此jar的除wordcount以外的其他用法
$ cd /home/hadoop/hadoop/share/hadoop/tools/lib/ #下面有很多jar包,通过jar包名称 --help的方式也能看到它们的详细用法。如,下面的例子:
$ hadoop jar /home/hadoop/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.4.jar --help
博文来自:www.51niux.com
二、hadoop支持lzo
上面是配置完之后的结果,前面已经记录了hadoop的配置文件里面已经加上lzo的配置了,但是lzo的整个安装过程还没有做,这时候如果不做下面的步骤,你执行mapreduce分析是要报错的。
我上家公司包括现在对于hadoop的都使用的lzo的压缩算法,所以这里就不介绍对其他压缩算法的支持和配置了。
如果不做这里的设置,会报下面的错误:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://master.hadoop:8020/songs/logs/songs.access.log.lzo hdfs://master.hadoop:8020/songs/jieguo/2017_11_1/15/
17/11/01 16:57:52 INFO client.RMProxy: Connecting to ResourceManager at master.hadoop/192.168.14.49:8032 17/11/01 16:57:52 INFO input.FileInputFormat: Total input paths to process : 1 17/11/01 16:57:52 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/01 16:57:52 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/01 16:57:53 INFO mapreduce.JobSubmitter: number of splits:1 17/11/01 16:57:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1509520940514_0007 17/11/01 16:57:53 INFO impl.YarnClientImpl: Submitted application application_1509520940514_0007 17/11/01 16:57:53 INFO mapreduce.Job: The url to track the job: http://master.hadoop:8088/proxy/application_1509520940514_0007/ 17/11/01 16:57:53 INFO mapreduce.Job: Running job: job_1509520940514_0007 17/11/01 16:58:00 INFO mapreduce.Job: Job job_1509520940514_0007 running in uber mode : false 17/11/01 16:58:00 INFO mapreduce.Job: map 0% reduce 0% 17/11/01 16:58:10 INFO mapreduce.Job: map 100% reduce 0% 17/11/01 16:58:14 INFO mapreduce.Job: Task Id : attempt_1509520940514_0007_r_000000_0, Status : FAILED Error: java.lang.IllegalArgumentException: Compression codec com.hadoop.compression.lzo.LzoCodec was not found. at org.apache.hadoop.mapred.JobConf.getMapOutputCompressorClass(JobConf.java:798) at org.apache.hadoop.mapred.ReduceTask.initCodec(ReduceTask.java:156) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:349) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1746) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec not found at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2101) at org.apache.hadoop.mapred.JobConf.getMapOutputCompressorClass(JobConf.java:796) ... 7 more Container killed by the ApplicationMaster. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143
#Compression codec com.hadoop.compression.lzo.LzoCodec was not found. #如果配置文件里面已经定义了输入输出都是走压缩的话,就会报错找不到lzo。
2.1 压缩介绍
为什么要压缩:
节省数据占用的磁盘空间;
加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度。
#http://www.cnblogs.com/wuyudong/p/4378357.html
#https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-compression-analysis/
#上面两篇博客介绍的,我就不记录了,大家可以点进去详细了解下。
#hadoop是海量存储,一般我们会把日志之类的文本信息存放在上面,一般都是定时任务处理,如一般可能晚上2,3点开始跑脚本调处理脚本或者程序来对日志进行分析汇总,而日志文件本来压缩和不压缩的量级就是不一样的,这样经过压缩后存放到hadoop上面可以上HDFS系统能够存储更多的日志文件,另外日志的体量小了之后就是传输速度处理速度就快了,而压缩器(Compressor)和解压器(Decompressor)是Hadoop压缩框架中的一对重要概念。做了了hadoop的对压缩的支持,就可以实现将压缩文件上传到hdfs系统上,然后hadoop对压缩文件进行处理然后再将结果进行压缩,当然这样就对CPU会产生消耗。
#我们以前的处理方式就是将log日志汇总然后进行lzo压缩上传到hdfs系统,然后凌晨以后会跑几个处理脚本,脚本里面当然是各种创建目录调用程序等,当然产生的结果也是压缩后存到hdfs上面的,然后将结果文件get下来,然后解压缩处理后插入到对应的mysql数据库中,这样第二天运营营销等需要查看的人就可以直接通过web后台页面来查看自己想要查看的内容了。
2.2 hadoop支持lzo配置
Hadoop原生是支持gzip和bzip2压缩的,这两种压缩做map reduce解压缩的时候,要比lzo慢好多。不过lzo也不是linux系统原生支持的,所以来我们进行下面的配置。
#在namenode节点上面操作就好了,做好了发送一波就可以了。
安装lzop native library
# yum -y install lzo-devel zlib-devel gcc autoconf automake libtool
# wget www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz #当然最新的是2.10,我就用2.06了
# tar -zxf lzo-2.06.tar.gz
# cd lzo-2.06
#export CFLAGS=-m64
#./configure -enable-shared -prefix=/usr/local/lzo-2.06
#make && make install
安装maven
#Maven是一个项目管理工具,它包含了一个项目对象模型 (Project Object Model),一组标准集合,一个项目生命周期(Project Lifecycle),一个依赖管理系统(Dependency Management System),和用来运行定义在生命周期阶段(phase)中插件(plugin)目标(goal)的逻辑。当你使用Maven的时候,你用一个明确定义的项目对象模型来描述你的项目,然后Maven可以应用横切的逻辑,这些逻辑来自一组共享的(或者自定义的)插件。
#wget mirrors.hust.edu.cn/apache/maven/maven-3/3.5.2/binaries/apache-maven-3.5.2-bin.tar.gz
#tar zxf apache-maven-3.5.2-bin.tar.gz
#mv apache-maven-3.5.2 /usr/local/
#ln -s /usr/local/apache-maven-3.5.2 /usr/local/apache-maven
#vim /etc/profile
############maven#######################
MAVEN_HOME=/usr/local/apache-maven
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/bin#source /etc/profile
# mvn -v #出现下图说明安装成功了

安装hadoop-lzo
#wget https://github.com/twitter/hadoop-lzo/archive/master.zip
#unzip master
# vim hadoop-lzo-master/pom.xml
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <hadoop.current.version>2.7.4</hadoop.current.version> #这里修改成对应的hadoop版本号 <hadoop.old.version>1.0.4</hadoop.old.version> </properties>
#cd hadoop-lzo-master/
# export CFLAGS=-m64
# export CXXFLAGS=-m64
#export C_INCLUDE_PATH=/usr/local/lzo-2.06/include
# export LIBRARY_PATH=/usr/local/lzo-2.06/lib
#mvn clean package -Dmaven.test.skip=true
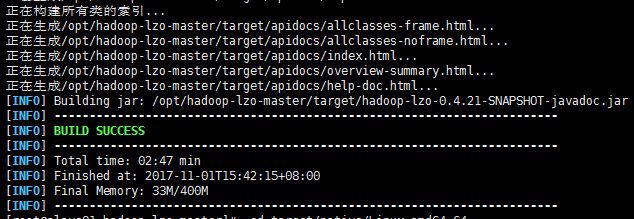
#出现上图说明mvn成功了,可以执行下echo $0看看有没有报错。
# cd target/native/Linux-amd64-64
# tar -cBf - -C lib . | tar -xBvf - -C ~
# cp ~/libgplcompression* $HADOOP_HOME/lib/native/
# cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar $HADOOP_HOME/share/hadoop/common/ #这里很重要,不然你会发现都做完了,命令行执行还是提示找不到lzo库。
# ls -l /root/libgplcompression.*

#其中libgplcompression.so和libgplcompression.so.0是链接文件,指向libgplcompression.so.0.0.0
配置hadoop环境变量和配置文件
# vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export LD_LIBRARY_PATH=/usr/local/lzo-2.06/lib
# vim $HADOOP_HOME/etc/hadoop/core-site.xml
<property> <name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property>
# vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<property> <name>mapred.child.env </name> <value>LD_LIBRARY_PATH=/usr/local/lzo-2.06/lib</value> </property> <property> <name>mapreduce.map.output.compress</name> <value>true</value> </property> <property> <name>mapreduce.map.output.compress.codec</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property>
同步文件到所有节点并重启Hadoop集群
#chown -R hadoop:hadoop /home/hadoop
/home/hadoop/hadoop/etc/hadoop/* #把配置文件重新同步一下
rsync -avz /usr/local/lzo-2.06 #用rsync的方式将此目录发送到其他目录的/usr/local下面,因为里面有两个软连接,如果用scp的话就没有软连接了。
rsync -avz $HADOOP_HOME/lib/native/ #同理把这个目录下的内容同步到其他节点
scp $HADOOP_HOME/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar #将此jar包发送到所有节点对应的目录下面,如果你要在shell下面执行命令处理分析日志
#cd /home/hadoop/hadoo
$ hadoop checknative #hadoop使用压缩的前提是:编译hadoop源码,输入如下命令来检查hadoop是否支持压缩

#从上图可以看出我这里又两种压缩格式现在是不支持的,所以我配置文件里面也没写。
# sbin/stop-all.sh
# sbin/start-all.sh #重启hadoop集群
博文来自:www.51niux.com
2.3 测试
到上面集群的操作已经结束了,这里测试一下。
lzop的安装
# wget www.lzop.org/download/lzop-1.04.tar.gz
# tar zxf lzop-1.04.tar.gz
# cd lzop-1.04
# ./configure
# make && make install
# ln -s /usr/local/bin/lzop /usr/bin/
# lzop -V
#出现此图,说明lzop工具安装成功
# lzop -h #可以看到帮助说明
# lzop access.log #对日志进行压缩
# ls -lh
#由上图可以看到gzip的压缩比lzo的压缩比要大。
# lzop -d access.log.lzo #这是解压文件的操作
# lzop -cd access.log.lzo|more #这是解压文件并输出的操作,并非输出到文件里面,是输出到屏幕上面。
测试hadoop现在是否支持lzo
#将上面产生的access.log.lzo上传到hdfs系统上面。

$ $HADOOP_HOME/bin/hdfs dfs -text hdfs://master.hadoop:8020/songs/logs/songs.access.log.lzo|more #如果出现下面的内容,也就是可以通过hdfs来读取lzo文件里面的内容了,说明hadoop支持lzo的配置已经成功了。
17/11/01 19:17:13 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/01 19:17:13 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/01 19:17:13 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available 17/11/01 19:17:13 INFO compress.CodecPool: Got brand-new decompressor [.lzo] 192.168.1.101 - - [14/Mar/2017:00:00:02 +0800] "GET /image/66/321.mka HTTP/1.1" 206 45012 "http://51niux.com/images/" "-" "-" 0.040 - - HIT
$ $HADOOP_HOME/bin/hdfs dfs -text hdfs://master.hadoop:8020/songs/logs/songs.access.log.lzo|more #如果执行是下面的报错,就是说明你是不是落下了哪一步没有做?
-text: Compression codec com.hadoop.compression.lzo.LzoCodec not found. Usage: hadoop fs [generic options] -text [-ignoreCrc] <src> ...

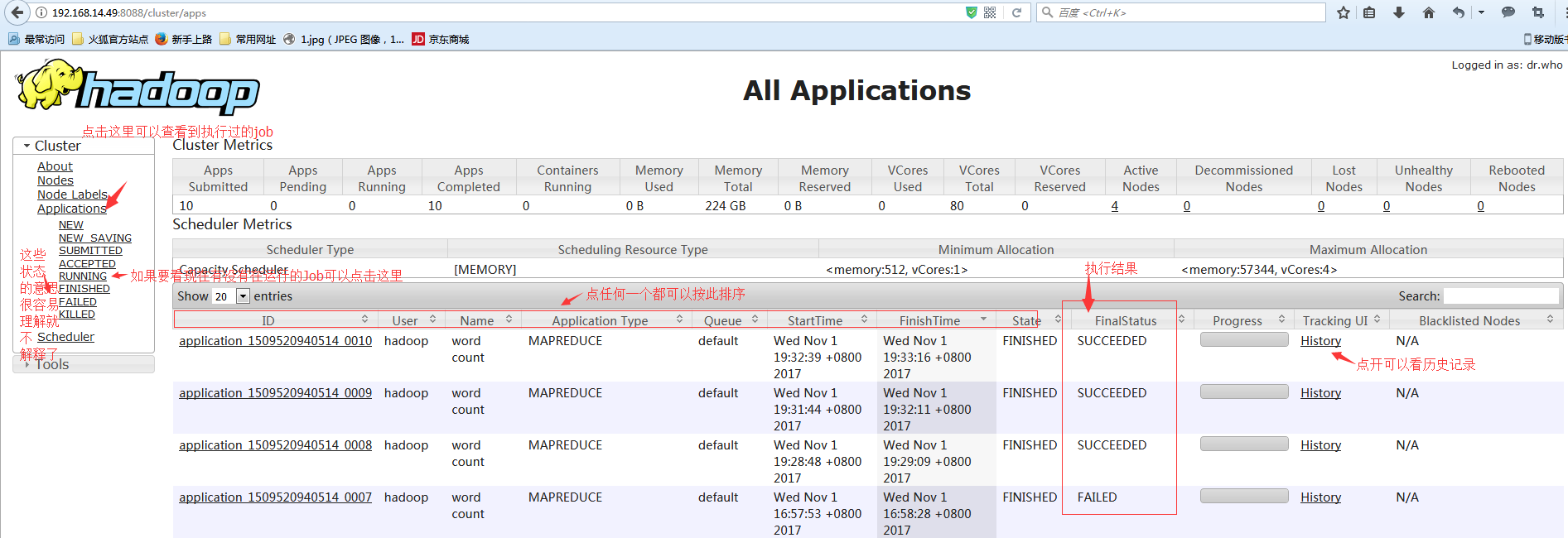
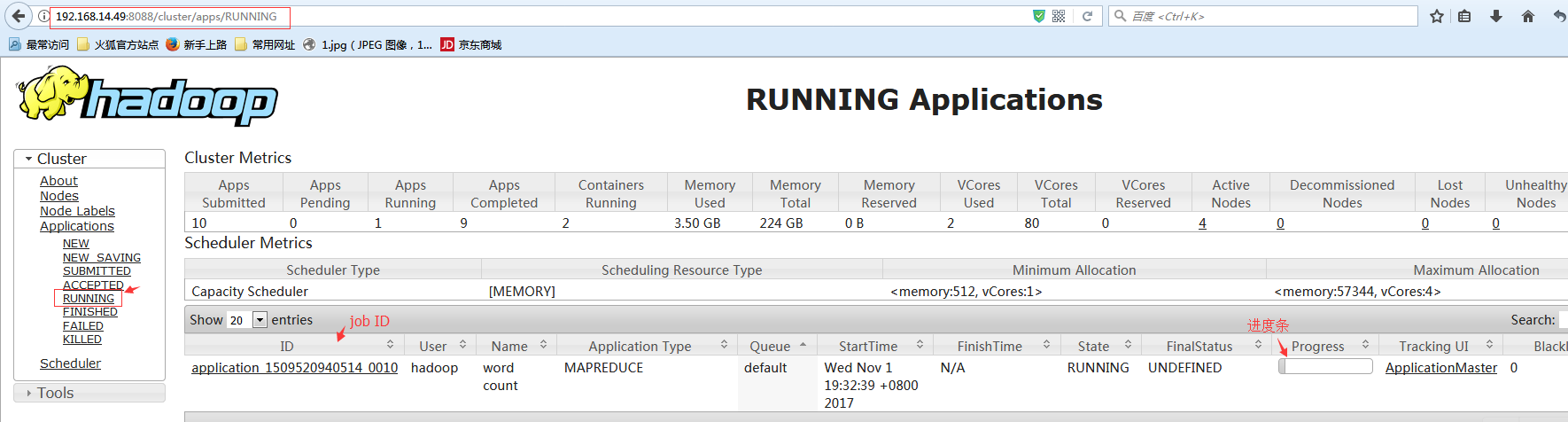
查看Applications 显示
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://master.hadoop:8020/songs/logs/songs.access.log.lzo hdfs://master.hadoop:8020/songs/jieguo/2017_11_1/21/
#我们先提交一个mapreduce任务
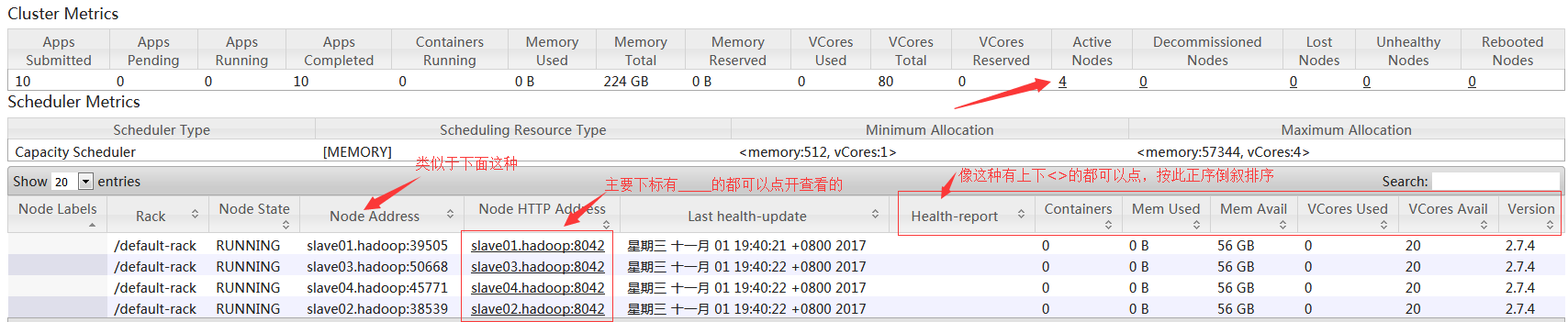
访问url: 192.168.14.49:8088 #master.hadoop的8088端口

#如上图,可以看到提交的总任务数(26391)。可用内存总量(560G),可用CPU核心数(200),存活的节点数(10)。存活节点那里是可以点开的,可以看到都有哪些节点。点开之后如下图:
![7{_GUK7JMOIO@N@@@]7ZHMX.png](http://www.51niux.com/zb_users/upload/2017/11/201711011509537127108394.png)
#点击ApplicationMaster可以看到此job的信息,可以看到一个map一个reduce。
#查看某个历史job的url,如:http://192.168.14.49:19888/jobhistory/job/job_1509520940514_0010 #也就是上上上图点History所显示的内容,就不截图了有兴趣自己看吧。
#注:8088端口显示的那些applications的历史记录,如果hadoop重启了,那些记录就没有了就又重新开始记录了,所以要想看完整的历史记录,还是要用19888端口来查看。
三、建立index索引
上面已经让hadoop支持lzo了,但是还不算完。
lzo本身是不支持split的。故如果需要使用lzo,一般有2种办法:
合理控制生成的lzo大小,建议不要超过一个block大小。因为如果没有lzo的index文件,该lzo会由一个map处理。如果lzo过大,会导致某个map处理时间过长。
配合lzo.index文件使用。好处是文件大小不受限制,可以将文件设置的稍微大点,这样有利于减少文件数目。坏处是生成lzo.index文件本身需要开销(这个本身并不占太大的空间)。
3.1 测试说明:
# hadoop fs -ls -h /lzotest/logs #为了做测试搞了两个日志文件上去,一个普通的log日志文件,一个lzo文件
-rw-r--r-- 3 hadoop supergroup 304.6 M 2017-11-02 10:50 /lzotest/logs/lzotest.log.lzo
-rw-r--r-- 3 hadoop supergroup 182.7 M 2017-11-02 10:49 /lzotest/logs/test.log
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://master.hadoop:8020/lzotest/logs/test.log hdfs://master.hadoop:8020/lzotest/tongji/log10/ #先对日志进行下分析
17/11/02 10:59:56 INFO client.RMProxy: Connecting to ResourceManager at master.hadoop/192.168.14.49:8032 17/11/02 10:59:57 INFO input.FileInputFormat: Total input paths to process : 1 17/11/02 10:59:57 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries 17/11/02 10:59:57 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5] 17/11/02 10:59:58 INFO mapreduce.JobSubmitter: number of splits:3 17/11/02 10:59:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1509587541710_0004 17/11/02 10:59:58 INFO impl.YarnClientImpl: Submitted application application_1509587541710_0004 17/11/02 10:59:58 INFO mapreduce.Job: The url to track the job: http://master.hadoop:8088/proxy/application_1509587541710_0004/ 17/11/02 10:59:58 INFO mapreduce.Job: Running job: job_1509587541710_0004 17/11/02 11:00:04 INFO mapreduce.Job: Job job_1509587541710_0004 running in uber mode : false 17/11/02 11:00:04 INFO mapreduce.Job: map 0% reduce 0% 17/11/02 11:00:14 INFO mapreduce.Job: map 22% reduce 0% 17/11/02 11:00:15 INFO mapreduce.Job: map 60% reduce 0% 17/11/02 11:00:16 INFO mapreduce.Job: map 71% reduce 0% 17/11/02 11:00:18 INFO mapreduce.Job: map 89% reduce 0% 17/11/02 11:00:19 INFO mapreduce.Job: map 100% reduce 0% 17/11/02 11:00:23 INFO mapreduce.Job: map 100% reduce 100% 17/11/02 11:00:24 INFO mapreduce.Job: Job job_1509587541710_0004 completed successfully 17/11/02 11:00:25 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=6787904 FILE: Number of bytes written=10266992 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=191825600 HDFS: Number of bytes written=489234 HDFS: Number of read operations=12 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=3 Launched reduce tasks=1 #起了一个reduce汇总 Data-local map tasks=3 #起了三个map
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount hdfs://master.hadoop:8020/lzotest/logs/lzotest.log.lzo hdfs://master.hadoop:8020/lzotest/tongji/lzo10/ #对lzo的处理
![9J$H07H]RA}CCS`B[V(CI43.png](http://www.51niux.com/zb_users/upload/2017/11/201711021509604274209558.png)
![~[1[OGJ}$KQ]K%VGDJ5EEMB.png](http://www.51niux.com/zb_users/upload/2017/11/201711021509604287685083.png)
#从上图可以只起了一个map.当然处理速度也就很慢了。这就是如果你lzo不搞索引的话,不管你lzo多大分布在多少个节点,就发起一个map,那就会很慢的。
3.2 对lzo压缩文件的处理方法
上面提到过了如果lzo是很大的文件超过block的大小的话,就采取建索引的形式来处理。
给lzo文件建立索引
Hadoop-lzo包本身提供了建立lzo索引的类,可以在本地运行程序建立索引,也可以运行mapreduce程序建立索引。
第一种方式是本地运行程序建立索引,比较慢:
如下面的例子:
$ hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/lib/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.LzoIndexer hdfs://master.hadoop:8020/lzotest/logs/lzotest.log.lzo
第二种方式是运行mapreduce程序建立索引,比较快:
如下面的例子:
$ hadoop jar /home/hadoop/hadoop/share/hadoop/mapreduce/lib/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer hdfs://master.hadoop:8020/lzotest/logs/lzotest.log.lzo
#上面两种方式成功之后,都会再hdfs目录的lzo文件的同目录下面产生一个以Index结尾的索引文件,如下图:

更改程序
单纯的做了索引还是不行的,在运行程序的时候还要对要运行的程序进行相应的更改,把inputformat设置成LzoTextInputFormat,不然还是会把索引文件也当做是输入文件,还是只运行一个map来处理。
可参考下面的链接:
http://wzktravel.github.io/2016/09/19/hadoop-lzo/
http://blog.csdn.net/u010670689/article/details/32979623
