Ceph简介和集群搭建(一)
Ceph大家已经不陌生了,主要是虚拟化分布式存储方面。
官网文档:http://docs.ceph.com/docs/master/
一、Ceph简介
1.1 Ceph的主要特点:
统一存储
无任何单点故障
数据多份冗余
存储容量可扩展
自动容错及故障自愈
1.2 Ceph三大角色组件及其作用
在Ceph存储集群中,包含了三大角色组件,他们在Ceph存储集群中表现为3个守护进程,分别是Ceph OSD、Monitor、MDS。当然还有其他的功能组件,但是最主要的是这三个。
Ceph OSD:
Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
Monitor:
Ceph的Monitor守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map、PG(Placement Group) map、CRUSH map。 这些映射是Ceph守护进程之间相互协调的关键簇状态。 监视器还负责管理守护进程和客户端之间的身份验证。 通常需要至少三个监视器来实现冗余和高可用性。
MDS:
Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力。
还有一个Managers:
Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
Ceph的术语表:http://docs.ceph.com/docs/master/glossary/#term-ceph-storage-cluster
1.3 Ceph的架构及应用场景
文档连接:http://docs.ceph.com/docs/master/architecture/
Ceph的架构主要分成底层数据分布及上层应用接口,下面是官网架构图:
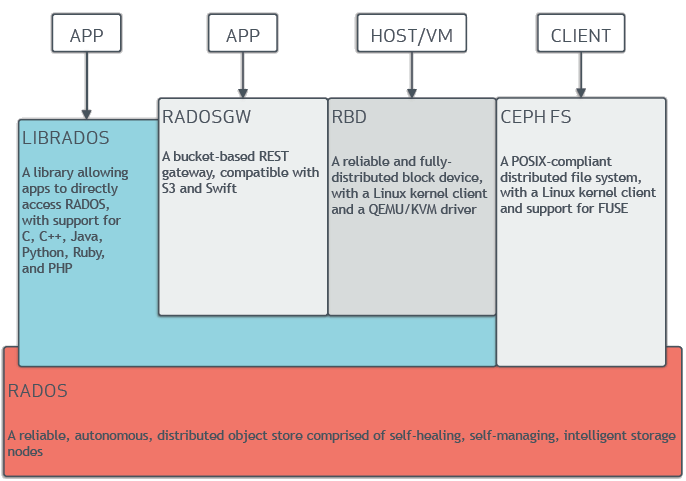
A library......and PHP #LIBRADOS库允许应用程序可以直接访问Ceph底层的对象存储,它支持的有C、C++、Java、Python、Ruby及PHP语言。 A bucket-based......and Swift #一套基于RESTful协议的网关,并兼容S3和Swift。 A reliable......QEMU/KVM driver #通过Linux内核客户端及QEMU/KVM驱动,来提供一个可靠且完全分布的块设备。 A POSIX-compliant......for FUSE #通过Linux内核客户端结合FUSE,来提供一个兼容POSIX文件结构系统。 A reliable,autonomous......storage nodes #以其具备的自愈功能、自管理、智能存储节点特性,来提供一个可靠、自动、分布式的对象存储。
Ceph的底层核心是RADOS(Reliable, Autonomic Distributed Object Store),Ceph的本质是一个对象存储。RADOS由两个组件组成:OSD和Monitor。OSD主要提供存储资源,每一个disk、SSD、RAID group或者一个分区都可以成为一个OSD,而每个OSD还将负责向该对象的复杂节点分发和恢复;Monitor维护Ceph集群并监控Ceph集群的全局状态,提供一致性的决策。
RADOS分发策略依赖于名为CRUSH(Controlled Replication Under Scalable Hashing)的算法(基于可扩展哈希算法的可控复制)
应用场景:
Ceph的应用场景主要由它的架构确定,Ceph提供对象存储、块存储和文件存储,主要由4种应用:
第一类:LIBRADOS应用
通俗的说,Librados提供了应用程序对RADOS的直接访问,目前Librados已经提供了对C、C++、Java、Python、Ruby和PHP的支持。它支持单个单项的原子操作,如同时更新数据和属性、CAS操作,同时有对象粒度的快照操作。它的实现是基于RADOS的插件API,也就是在RADOS上运行的封装库。
第二类:RADOSGW应用
这类应用基于Librados之上,增加了HTTP协议,提供RESTful接口并且兼容S3、Swfit接口。RADOSGW将Ceph集群作为分布式对象存储,对外提供服务。
第三类:RBD应用
这类应用也是基于Librados之上的,细分为下面两种应用场景。
第一种应用场景为虚拟机提供块设备。通过Librbd可以创建一个块设备(Container),然后通过QEMU/KVM附加到VM上。通过Container和VM的解耦,使得块设备可以被绑定到不同的VM上。
第二种应用场景为主机提供块设备。这种场景是传统意义上的理解的块存储。
以上两种方式都是将一个虚拟的块设备分片存储在RADOS中,都会利用数据条带化提高数据并行传输,都支持块设备的快照、COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。
第四类:CephFS(Ceph文件系统)应用
这类应用是基于RADOS实现的PB级分布式文件系统,其中引入MDS(Meta Date Server),它主要为兼容POSIX文件系统提供元数据,比如文件目录和文件元数据。同时MDS会将元数据存储在RADOS中,这样元数据本身也达到了并行化,可以大大加快文件操作的速度。MDS本身不为Client提供数据文件,只为Client提供对元数据的操作。当Client打开一个文件时,会查询并更新MDS相应的元数据(如文件包括的对象信息),然后再根据提供的对象信息直接从RADOS中得到文件数据。
博文来自:www.51niux.com
二、Ceph部署安装
2.1 使用ceph-deploy工具部署Ceph
官网安装文档:http://docs.ceph.com/docs/master/start/
ceph-deploy工具在管理节点上的目录中运行。 任何具有网络连接和现代python环境以及ssh(如Linux)的主机都应该可以工作。
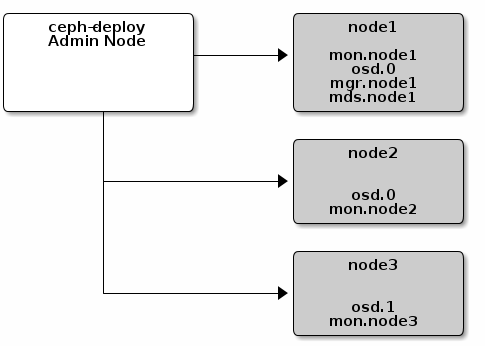
ceph-deploy工具使用SSH的方式连接到服务器上,通过执行一些列的python脚本,来完成Ceph集群的部署。这个工具是Ceph官网推荐的一个快速部署和管理Ceph集群的工具,这个工具是用Python语言编写的。下面是官网图:
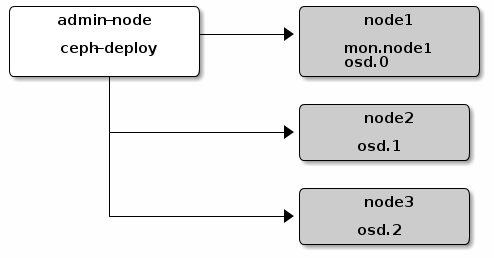
这里我们搞四个节点都是操作系统Centos7的,每个Ceph节点上面启动两个OSD角色,每个OSD角色对应一块物理磁盘。分别是,192.168.1.103-106.
安装ceph-deploy
先在192.168.1.103上面配置hosts文件,并保证192.168.1.103能够无密码访问其他的节点。
# cat /etc/hosts #配置下/etc/hosts,这里面设置的主机名称要一定是对应节点的hostname
192.168.1.103 ceph-host-01 192.168.1.104 ceph-host-02 192.168.1.105 ceph-host-03 192.168.1.106 ceph-host-04
#ssh-keygen -t rsa #生成密钥对
# ssh-copy-id ceph-host-02 #拷贝完公钥之后最好登录测试一下是不是不需要输入密码了
# ssh-copy-id ceph-host-03
# ssh-copy-id ceph-host-04
# cat /etc/yum.repos.d/ceph.repo #配置yum源
[ceph-noarch] name=Ceph noarch packages baseurl=https://download.ceph.com/rpm/el7/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://download.ceph.com/keys/release.asc
#注:新版的ceph的yum发生了变化,要指定对应ceph版本,这个可以自己根据官网寻找:
[ceph] name=Ceph packages for $basearch baseurl=https://download.ceph.com/rpm-15.2.4/el7/$basearch enabled=1 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=https://download.ceph.com/rpm-15.2.4/el7/noarch enabled=1 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc [ceph-source] name=Ceph source packages baseurl=https://download.ceph.com/rpm-15.2.4/el7/SRPMS enabled=0 priority=2 gpgcheck=1 gpgkey=https://download.ceph.com/keys/release.asc
#所以rpm报的下载链接就是:https://download.ceph.com/rpm/
# yum install ceph-deploy -y #yum安装ceph-deploy工具
# ceph-deploy --version #查看下版本号,注意是python7的话还需要# pip install ceph_deploy

创建Ceph Monitor角色
# mkdir /deploy_ceph_cluster # 为了获得最佳效果,请在管理节点上创建一个目录,以维护ceph-deploy为集群生成的配置文件和密钥。
# cd /deploy_ceph_cluster/ #ceph-deploy实用程序将输出文件到当前目录中。
#如果在任何时候你遇到麻烦,你想重新开始,执行 以下清洗Ceph包,和擦除所有数据和配置,也就是重新开始,运行下面的操作:
ceph-deploy purge {ceph-node} [{ceph-node}]
ceph-deploy purgedata {ceph-node} [{ceph-node}]
ceph-deploy forgetkeys
rm ceph.*# ceph-deploy new ceph-host-01 ceph-host-02 ceph-host-03 #创建一个新的集群,现在把三个节点加到这个新集群里面来了,执行完成之后,配置目录下生成了3个文件。

#ceph.conf 为集群配置文件,ceph-deploy-ceph.log为ceph-deploy命令执行结果的日志,ceph.mon.keyring为ceph mon角色的key。
# ceph-deploy install ceph-host-01 ceph-host-02 ceph-host-03 #使用ceph-deploy来安装ceph程序,也可以单独到每台节点机上手工安装Ceph。
#当然你执行上面的命令可能会遇到yum安装,就要跑到各个节点上面安装了,下面是各个节点的操作步骤:
# yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm #有好多包需要第三方yum源的支持 # yum install -y https://download.ceph.com/rpm-jewel/el7/noarch/ceph-release-1-0.el7.noarch.rpm # yum -y install yum-plugin-priorities # yum install ceph ceph-release ceph-common ceph-radosgw -y #然后再有软件包冲突再单独解决吧
# ceph-deploy mon create-initial #部署初始监视器并收集密钥,完成此过程后,本地目录应具有以下密钥键
ceph.bootstrap-mds.keyring #MDS启动key ceph.bootstrap-osd.keyring #OSD启动key ceph.bootstrap-rgw.keyring ceph.client.admin.keyring #管理员key
# ceph-deploy admin ceph-host-01 ceph-host-02 ceph-host-03 #使用ceph-deploy将配置文件和管理密钥复制到管理节点和Ceph节点,以便您可以在每次执行命令时使用ceph CLI,而无需指定监视器地址和ceph.client.admin.keyring。
注意ceph-deploy mon create-initial 和ceph-deploy admin ceph-host-01 ceph-host-02 ceph-host-03 的操作相当于下面的操作:
# ceph-deploy mon create ceph-host-01 ceph-host-02 ceph-host-03 #创建ceph monitor节点
# ceph-deploy gatherkeys ceph-host-01 ceph-host-02 ceph-host-03 #使用ceph-deploy gatherkey命令将节点的key文件收上来。
#正常情况下,整个执行过程中没有ERROR,只有下面两种状态[DEBUG]和[INFO]:
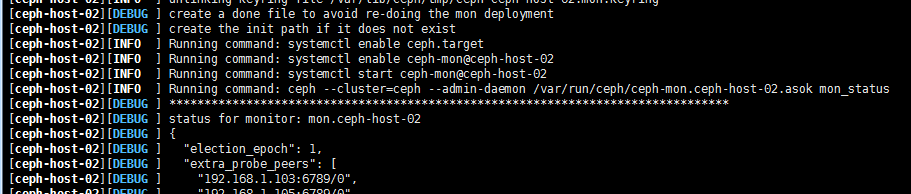
#关于下面的错误:此错误上面会有几个命令,可以在客户端执行:ceph --cluster=ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-host-02.asok mon_status #查看一下具体什么问题
[ERROR ] admin_socket: exception getting command descriptions: [Errno 2] No such file or directory
#如果第一次ceph-deploy install执行出现问题,反复调试,也会造成上面的错误,可以试一下,一开始记录的purge四步,将操作擦除掉,重新install再mon create试试。
创建Ceph OSD角色
# cat /deploy_ceph_cluster/ceph.conf #新加下面四行
public_network = 192.168.1.0/24 #配置公共网络 [osd] osd_journal_size = 5120 #定义日志的大小为5GB [mon] mon osd allow primary affinity = true #开启OSD亲和度调整开关
# ceph-deploy --overwrite-conf osd prepare ceph-host-01:/dev/sdb ceph-host-02:/dev/sdb ceph-host-03:/dev/sdb #工具会自动分区并格式化
# ls -l /var/lib/ceph/osd/ceph-2/ #查看一下数据分区目录
总用量 56 -rw-r--r-- 1 root root 502 8月 10 14:52 activate.monmap -rw-r--r-- 1 ceph ceph 3 8月 10 14:52 active -rw-r--r-- 1 ceph ceph 37 8月 10 14:52 ceph_fsid drwxr-xr-x 132 ceph ceph 4096 8月 10 14:52 current -rw-r--r-- 1 ceph ceph 37 8月 10 14:52 fsid lrwxrwxrwx 1 ceph ceph 58 8月 10 14:52 journal -> /dev/disk/by-partuuid/e2b0c8cb-bc88-4ad4-aaa1-19680008a2b6 -rw-r--r-- 1 ceph ceph 37 8月 10 14:52 journal_uuid -rw------- 1 ceph ceph 56 8月 10 14:52 keyring -rw-r--r-- 1 ceph ceph 21 8月 10 14:52 magic -rw-r--r-- 1 ceph ceph 6 8月 10 14:52 ready -rw-r--r-- 1 ceph ceph 4 8月 10 14:52 store_version -rw-r--r-- 1 ceph ceph 53 8月 10 14:52 superblock -rw-r--r-- 1 ceph ceph 0 8月 10 14:52 systemd -rw-r--r-- 1 ceph ceph 10 8月 10 14:52 type -rw-r--r-- 1 ceph ceph 2 8月 10 14:52 whoami
#注:在新版本中不能用上面的方式了,只能用# ceph-deploy --overwrite-conf osd create --data /dev/sdb ceph-host-01
#注:在新版本中还需要执行:ceph-deploy mgr create ceph-host-01 ceph-host-02 ceph-host-03 #创建主备守护进程
# ceph health #节点查看下状态,可以看到是OK状态
HEALTH_OK
#注:新版本的话会有 HEALTH_WARN Module 'restful' has failed dependency: No module named 'pecan 报错:
#需要执行:#pip3 install pecan werkzeug 并重启机器,不重启机器还是上面的报错哈。
#当然重启机器后,可能会报下面的错误:HEALTH_WARN clock skew detected on ceph-host-02,原因有两个,一个是mon节点上ntp服务器未启动,另一个是ceph设置的mon的时间偏差阈值比较小。所以要进行下面的操作:
# vim ceph.conf #增加下面两行
mon clock drift allowed = 2
mon clock drift warn backoff = 30
#ceph-deploy --overwrite-conf config push ceph-host-01 ceph-host-02 ceph-host-03 #把配置文件推送一下
#systemctl restart ceph-mon.target #在所有的监控节点执行重启mon进程操作。
注(如果我不想让系统来分,我想按照自己的想法来搞呢):
# df -h|grep /data #各个节点调整一下,对挂载盘进行分区,如:/dev/sdb2为5G空间,不用格式化不用挂载。/dev/sdb1为剩余空间,xfs格式化并挂载。
#要对挂载分区和/dev/sdc盘符进行ceph:ceph授权
# ceph-deploy --overwrite-conf osd prepare ceph-host-01:/data02:/dev/sdc2 ceph-host-02:/data02:/dev/sdc2 ceph-host-03:/data02:/dev/sdc2 #/data02是ceph data分区,/dev/sdc2存放Journal
# ceph-deploy --overwrite-conf osd activate ceph-host-01:/data02:/dev/sdc2 ceph-host-02:/data02:/dev/sdc2 ceph-host-03:/data02:/dev/sdc
** ERROR: error creating empty object store in /data02: (13) Permission denied #这个问题就是授权的问题,要对物理盘符进行ceph的授权
创建Ceph MDS角色
Ceph MDS(Metadata Server)角色不是一个必需的角色,只有当使用CephFS的时候才需要。CephFS至少需要一台Metada服务器。
# ceph-deploy mds create ceph-host-01 #这是将ceph-host-01节点创建为MDS角色,如果部署多台就多个节点空格分开。注意主机名称如果是数字开头是不成功的,可以用#systemctl status ceph-mds@ceph-host-01 来查看服务状态
# ceph osd pool create data 192 192 #生成data池
# ceph osd pool create metadata 192 192 #生成metadata池
# ceph fs new cephfs metadata data
# ceph mds stat
e5: 1/1/1 up {0=ceph-host-01=up:active}
# ceph -s #查看整个集群的状态
cluster 668a0fe8-cc35-4a68-8cc1-26dca11fc99d
health HEALTH_OK
monmap e1: 3 mons at {ceph-host-01=192.168.1.103:6789/0,ceph-host-02=192.168.1.104:6789/0,ceph-host-03=192.168.1.105:6789/0}
election epoch 4, quorum 0,1,2 ceph-host-01,ceph-host-02,ceph-host-03
fsmap e5: 1/1/1 up {0=ceph-host-01=up:active}
osdmap e38: 9 osds: 6 up, 6 in
flags sortbitwise,require_jewel_osds
pgmap v127: 448 pgs, 3 pools, 2068 bytes data, 20 objects
215 MB used, 269 GB / 269 GB avail #我们将/dev/sdb和/dev/sdc两个盘符都挂载了,每个划出了45G来存储数据,45*6=270G,这里正好
448 active+clean博文来自:www.51niux.com
三、CephFS的挂载使用
3.1挂载CephFS
CephFS的挂载方式有两种:FUSE(用户空间文件系统)和通过内核模块挂载。
使用FUSE方式挂载CephFS
# yum install https://download.ceph.com/rpm-jewel/el7/noarch/ceph-release-1-0.el7.noarch.rpm -y
# yum install ceph-fuse -y
#需要复制ceph.conf和ceph.client.admin.keyring到客户端的/etc/ceph目录中
# mkdir /cephdata
# ceph-fuse -m ceph-host-01:6789 /cephdata #挂载过程中,ceph-fuse会读取ceph.conf配置,选择可用的Moniter进行挂载。对于有多个Moniter的集群,即使其中一个Moniter坏了也不影响客户端使用。
# df -Th|grep /cephdata #查看一下

#从上图可以看出,Filesystem的源是ceph-FUSE,并未绑定哪台Moniter,文件系统类型是FUSE.ceph-FUSE
内核挂载CephFS
内核2.6.34及其以后的版本才支持,Linux 3.6.x是内核支持中最稳定的,官网推荐使用的,所以我这里是Centos7的系统,就不用升级内核直接可以使用的。
# modprobe ceph #默认是没有加载的,先加载一下
# lsmod |grep ceph #查看一下
ceph 327687 0 libceph 282630 1 ceph libcrc32c 12644 1 libceph dns_resolver 13140 1 libceph
# mount -t ceph 192.168.1.104:6789:/ /cephdata -o name=admin,secret=AQBU5YtZ6IaRFRAALgAq25sIJZMO1tvvMDR7AQ== #因为默认使用ceph-deploy部署的Ceph集群都开启cephx认证,这里IP是Moniter其中的一个IP,对端挂载端口是6789,挂载目录是/cephdata,然后-o name是认证名称来自于ceph.client.admin.keyring ,secret=认证口令来自于ceph.client.admin.keyring文件

#注:如果没有开启cephx认证的话,可以直接使用:mount -t ceph 192.168.1.104:6789:/ /cephdata #进行挂载,不过一般都会有认证挂载的。
3.2 挂载使用Ceph RBD
使用内核方式挂载并使用Ceph RBD
使用内核方式挂载Ceph块设备,需要内核支持RBD模块,默认CentOS6.5内核不支持,需要升级内核。
挂载Ceph RBD设备之后,有两种使用方式:
第一种:直接格式化当作本地磁盘使用
第二种:使用iSCSI软件,将这个块设备以iSCSI设备的形式对外提供iSCSI服务。
Ceph集群里面的操作:
# ceph osd pool create rbdpool 192 192 #创建名为rbdpool的存储池,PG(Placement Group,配置组)和PGS(配置组总和)定义为192
# rbd create block-device --size 1024 --pool rbdpool --image-format 2 --image-feature layering #在存储池rbdpool中创建名为block-device的镜像,大小为1024MB,format 2,使用第二版 rbd 格式,--image-feature 选项指定使用特性,不用全部开启。我们的需求仅需要使用快照等特性,开启layering即可。默认格式2的rbd 块支持如下特性,默认全部开启:
layering: 支持分层 striping: 支持条带化 v2 exclusive-lock: 支持独占锁 object-map: 支持对象映射(依赖 exclusive-lock ) fast-diff: 快速计算差异(依赖 object-map ) deep-flatten: 支持快照扁平化操作 journaling: 支持记录 IO 操作(依赖独占锁)
# rbd ls rbdpool #查看存储池rbdpool中包括的镜像,下面可以看到有一个block-device镜像
block-device
# rbd info block-device --pool rbdpool #查看存储池rbdpool中镜像block-device的信息
rbd image 'block-device': size 1000 GB in 256000 objects order 22 (4096 kB objects) block_name_prefix: rbd_data.107e238e1f29 format: 2 features: layering, exclusive-lock, object-map, fast-diff, deep-flatten flags:
Ceph客户端的操作:
# modprobe rbd #加载RBD模块
# lsmod |grep rbd #查看一下是否加载了
rbd 83938 0 libceph 282630 2 rbd,ceph
# yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# yum install ceph-common -y
# rbd -v #查看rbd版本
ceph version 10.2.9 (2ee413f77150c0f375ff6f10edd6c8f9c7d060d0)
#复制Ceph集群的配置及key到客户端,生产环节处于安全考虑,需要创建账号,重新授权,而非简单的使用client.admin的key。
# rbd map block-device -p rbdpool #客户端挂载RBD设备
#查看一下,已经挂载到客户端了。
下面是直接使用Ceph RBD设备,这种方式用的比较普遍,等于给服务器挂载了一块远程磁盘。还可以非常方便的卸载和挂载到其他服务器上,类似于云硬盘。
# mkfs.ext4 /dev/rbd0 #可以对这个设备分区,或者直接格式化
# mkdir /rbdtest #创建挂载点
# mount /dev/rbd0 /rbdtest #挂载

#从上图可以看出挂载了个1GB大小的RBD设备分区。
注意(这里挂载的时候有个坑是ceph集群设置的问题):
[root@master /]# rbd map block-device -p rbdpool #挂载有报错,提示有些特性不支持 rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable". In some cases useful info is found in syslog - try "dmesg | tail" or so. rbd: map failed: (6) No such device or address
原因:内核版本 3.10,仅支持此特性(layering),其它特性需要使用更高版本内核,或者从新编译内核加载特性模块才行。所以上面ceph集群创建镜像的时候不能默认开启所有特性,只能开启部分特性,不然客户端可能不支持。
使用scsi-target将Ceph RBD作为共享块设备对外提供服务
有这种方式,就不记录过程了,就是记录一下有这种方式:http://www.sebastien-han.fr/blog/2017/01/05/Ceph-RBD-and-iSCSI/
3.3 通过Librbd方式使用Ceph RBD
Ceph RBD(Rados Block Device,基于RADOS对象存储的块设备)是一种对外提供块设备的存储方案。Ceph RBD包含许多非常好用的功能,包括快照、备份、恢复,其中还有一个对于虚拟化来说最好的特性,就是对QEMU及Libvirt的支持,使虚拟机直接运行在Ceph RBD上成为可能。
链接地址:http://www.51niux.com/?id=160 #这里已经做了记录
博文来自:www.51niux.com
四、命令记录
4.1 ceph命令解释
# ceph -h
一般用法:
ceph [-h] [-c CEPHCONF] [-i INPUT_FILE] [-o OUTPUT_FILE]
[--id CLIENT_ID] [--name CLIENT_NAME] [--cluster CLUSTER]
[--admin-daemon ADMIN_SOCKET] [--admin-socket ADMIN_SOCKET_NOPE]
[-s] [-w] [--watch-debug] [--watch-info] [--watch-sec]
[--watch-warn] [--watch-error] [--version] [--verbose] [--concise]
[-f {json,json-pretty,xml,xml-pretty,plain}]
[--connect-timeout CLUSTER_TIMEOUT]
Ceph管理工具:
可选参数:
-h, --help #请求帮助
-c CEPHCONF, --conf CEPHCONF #ceph配置文件
-i INPUT_FILE, --in-file INPUT_FILE #输入文件
-o OUTPUT_FILE, --out-file OUTPUT_FILE #输出文件
--id CLIENT_ID, --user CLIENT_ID #用户身份验证
--name CLIENT_NAME, -n CLIENT_NAME #客户端名称进行认证
--cluster CLUSTER #集群名称
--admin-daemon ADMIN_SOCKET #提交admin-socket命令
--admin-socket ADMIN_SOCKET_NOPE #意味着--admin-daemon
-s, --status #显示集群状态
-w, --watch #观看实时集群更改
--watch-debug #监视调试事件
--watch-info #监视信息事件
--watch-sec #监视安全事件
--watch-warn #监视警告事件
--watch-error #监视错误事件
--version, -v #展示版本
--verbose #展示详细信息
--concise #精简输出
-f {json,json-pretty,xml,xml-pretty,plain}, --format {json,json-pretty,xml,xml-pretty,plain}
--connect-timeout CLUSTER_TIMEOUT #设置连接到集群的超时时间
监视命令([联系监视器,5秒后超时]):
osd blacklist add|rm <EntityAddr> {<float[0.0-]>} #添加到黑名单里面多少秒到期或者把地址从黑名单里面删掉
osd blacklist clear #清除所有列入黑名单的客户
osd blacklist ls #显示黑名单的客户
osd blocked-by #打印OSD的阻止对等体的直方图
osd create {<uuid>} {<int[0-]>} #创建新的osd(带有可选的UUID和ID)
osd crush add <osdname (id|osd.id)> <float[0.0-]> <args> [<args>...] #添加或更新crush map位置
osd crush add-bucket <name> <type> #添加类型为<type>的无父(可能是根)crush <name>
osd crush create-or-move <osdname (id|osd.id)> <float[0.0-]> <args> [<args>...] #在/位置<args>创建条目或移动<name> <weight>的现有条目
osd crush dump #导出打印crush
osd crush get-tunable straw_calc_version #得到可调的调整<tunable>
osd crush link <name> <args> [<args>...] #<br><div id="inner-editor"></div>68/5000将<name>的现有条目链接到位置<args>下
osd crush move <name> <args> [<args>...] #将<name>的现有条目移动到位置<args>
osd crush remove <name> {<ancestor>} #从crush map(无处不在,或只在<ancestor>)删除<name>
osd crush rename-bucket <srcname> <dstname> #将bucket <srcname>重命名为<dstname>
osd crush reweight <name> <float[0.0-]> #在crush map中将<name>的重量更改为<weight>
osd crush reweight-all #重新计算树的权重,以确保其正确合计
osd crush reweight-subtree <name> <float[0.0-]>
osd crush rm <name> {<ancestor>} #从crush map(无处不在,或只在<ancestor>)删除<name>
osd crush rule create-erasure <name> {<profile>} #创建使用<profile>创建的擦除编码池的默认规则<name>(默认默认值)
osd crush rule create-simple <name> <root> <type> {firstn|indep} #创建压缩规则<name>从<root>开始,使用<firstn | indep>的选择模式(默认为firstn; indep最适合擦除池)复制到类型为<type>的数据桶;
osd crush rule dump {<name>} #dump crush rule <name>(默认为全部)
osd crush rule list #列出crush规则
osd crush rule ls #列出crush规则
osd crush rule rm <name> #删除crush规则<name>
osd crush set #从输入文件设置crush地图
osd crush set <osdname (id|osd.id)> <float[0.0-]> <args> [<args>...]
osd crush set-tunable straw_calc_version <int> #将可调参数<tunable>设置为<value>
osd crush show-tunables #显示当前的粉碎可调参数
osd crush tree #在树视图中转储crush和项目
osd crush tunables legacy|argonaut|bobtail|firefly|hammer|jewel|optimal|default #将压缩可调参数值设置为<profile>
osd crush unlink <name> {<ancestor>} #取消链接<name>与crush map
osd deep-scrub <who> #在osd <who>上启动深度擦洗
osd df {plain|tree} #显示OSD利用率
osd down <ids> [<ids>...] #设置osd(s)<id> [<id> ...]下线
osd dump {<int[0-]>} #OSD打印摘要
osd erasure-code-profile get <name> #获取擦除代码配置文件<name>
osd erasure-code-profile ls #列出所有擦除代码配置文件
osd erasure-code-profile rm <name> #删除擦除代码配置文件<name>
osd erasure-code-profile set <name> {<profile> [<profile>...]} #使用[<key [= value]> ...]对创建擦除代码配置文件<name>。 最后添加一个--force来覆盖现有的配置文件(非常危险)
osd find <int[0-]> #在CRUSH map中找到osd <id>并显示其位置
osd getcrushmap {<int[0-]>} #获取crush map
osd getmap {<int[0-]>} #获取OSD map
osd getmaxosd #显示最大的OSD ID
osd in <ids> [<ids>...] #设置osd(s)<id> [<id> ...]进入
osd lost <int[0-]> {--yes-i-really-mean-it} #将osd标记为永久丢失。 如果没有更多的REPLICAS存在,请保留此数据
osd ls {<int[0-]>} #显示所有OSD ids
osd lspools {<int>} #列表池
osd map <poolname> <objectname> {<nspace>} #在[pool]中使用[namespace]查找<object>的pg
osd metadata {<int[0-]>} #提取osd {id}的元数据(默认为全部)
osd out <ids> [<ids>...] #设置osd(s)<id> [<id> ...]退出
osd pause #暂停osd
osd perf #打印OSD dump总结统计
osd pg-temp <pgid> {<id> [<id>...]} #设置pg_temp映射pgid:[<id> [<id> ...]](仅限开发人员)
osd pool create <poolname> <int[0-]> {<int[0-]>} {replicated|erasure} {<erasure_code_profile>} {<ruleset>} {<int>} #创建存储池
osd pool delete <poolname> {<poolname>} {--yes-i-really-really-mean-it} #删除存储池
osd pool get <poolname> size|min_size|crash_replay_interval|pg_num|pgp_num| crush_ruleset|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_
set_fpp|auid|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|
all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority
#获取存储池的参数值
osd pool get-quota <poolname> #获取池的对象或字节限制
osd pool ls {detail} #池列表
osd pool mksnap <poolname> <snap> #在<pool>中创建快照<snap>
osd pool rename <poolname> <poolname> #将<srcpool>重命名为<destpool>
osd pool rm <poolname> {<poolname>} {--yes-i-really-really-mean-it} #删除存储池
osd pool rmsnap <poolname> <snap> #从<pool>中删除快照<snap>
osd pool set <poolname> size|min_size|剩下的跟上面那一大波var一致 #将池参数<var>设置为<val>
osd pool set-quota <poolname> max_objects|max_bytes <val> #在池上设置对象或字节限制
osd pool stats {<name>} #从所有池或从指定池获取统计信息
osd primary-affinity <osdname (id|osd.id)> <float[0.0-1.0]> #从0.0 <= <weight> <= 1.0调整osd初级亲和力
osd primary-temp <pgid> <id> #设置primary_temp映射pgid:<id> | -1(仅限开发人员)
osd repair <who> #在osd <who>上启动修复
osd reweight <int[0-]> <float[0.0-1.0]>
osd reweight-by-pg {<int>} {<float>} {<int>} {<poolname> [<poolname>...]} #通过PG分配重载OSD
osd reweight-by-utilization {<int>} {<float>} {<int>} {--no-increasing}
osd rm <ids> [<ids>...] #删除osd(s)<id> [<id> ...]
osd scrub <who> #在osd <who>上启动擦除
osd set full|pause|noup|nodown|noout|noin|nobackfill|norebalance|norecover|noscrub|nodeep-scrub|notieragent|sortbitwise|require_jewel_osds #设置<key>
osd setcrushmap #从输入文件设置crush map
osd setmaxosd <int[0-]> #设置新的最大osd值
osd stat #OSD map打印摘要
osd test-reweight-by-pg {<int>}{<float>} {<int>} {<poolname> [<poolname>...]} #通过PG分配的OSD的运行
osd test-reweight-by-utilization {<int>} {<float>} {<int>} {--no-increasing}
osd thrash <int[0-]>
osd tier add <poolname> <poolname> {--force-nonempty} #将层<tierpool>(第二个)添加到基池“池”(第一个)
osd tier add-cache <poolname> <poolname> <int[0-]> #将大小<size>的缓存<tierpool>(第二个)添加到现有池<pool>(第一个)
osd tier cache-mode <poolname> none|writeback|forward|readonly|readforward|proxy|readproxy {--yes-i-really-mean-it} #指定缓存的缓存模式
osd tier remove <poolname> <poolname> #从基本池<pool>(第一个)删除层<tierpool>(第二个)
osd tier remove-overlay <poolname> #删除基本池<pool>的覆盖池
osd tier rm <poolname> <poolname> #从基本池<pool>(第一个)删除层<tierpool>(第二个)
osd tier rm-overlay <poolname> #删除基本池<pool>的覆盖池
osd tier set-overlay <poolname> <poolname> #将基池<pool>的覆盖池设置为<overlaypool>
osd tree {<int[0-]>} #打印OSD树
osd unpause #取消暂停
osd unset full|pause|noup|nodown|noout|noin|nobackfill|norebalance|norecover|noscrub|nodeep-scrub|notieragent|sortbitwise #unset <key>
osd utilization #获取基本的pg分布统计信息#上面crush是ceph中的算法:https://www.oschina.net/translate/crush-controlled-scalable-decentralized-placement-of-replicated-data?cmp
# man ceph #更详细的介绍可以man帮助文档
4.2 ceph-deploy命令解释
# ceph-deploy -h
用法: ceph-deploy [-h] [-v | -q] [--version] [--username USERNAME] [--overwrite-conf] [--cluster NAME] [--ceph-conf CEPH_CONF] COMMAND ... 完整的文档可以在: 可选参数: -h, --help #查看帮助 -v, --verbose #详细输出 -q, --quiet #精简输出 --version #查看版本 --username USERNAME #连接到远程主机的用户名 --overwrite-conf #覆盖远程主机上的现有conf文件(文件如果存在) --cluster NAME #集群的名称 --ceph-conf CEPH_CONF #使用(或重用)给定的ceph.conf文件 命令: new #开始部署一个新的集群,并为其编写一个CLUSTER.conf和keyring。 install #在远程主机上安装Ceph软件包。 rgw #Ceph RGW守护进程管理 mds #Ceph MDS守护进程管理 mon #Ceph MON Daemon管理 gatherkeys #收集用于配置新节点的身份验证密钥。 disk #管理远程主机上的磁盘。 osd #准备远程主机上的数据磁盘。 admin #将配置和client.admin密钥推送到远程主机 repo #汇报定义管理 config #将ceph.conf复制到/从远程主机复制 uninstall #从远程主机中删除Ceph软件包。 purge #从远程主机中删除Ceph软件包,并清除所有数据。 purgedata #清除(删除,销毁,丢弃,粉碎)任何Ceph数据从/var/lib/ceph forgetkeys #从本地目录中删除验证密钥。 pkg #管理远程主机上的软件包。 calamari #安装并配置Calamari节点。 假设已经配置了具有Calamari包的存储库。 请参阅文档中的示例(http://ceph.com/ceph-deploy/docs/conf.html)
#上面的大部分命令参数,我们再部署ceph简单集群的时候已经用到过了。
# ceph-deploy mon -h #这个帮助说明还可以更深一层的,如我们以mon命令参数举例
usage: ceph-deploy mon [-h] {add,create,create-initial,destroy} ...
Ceph MON Daemon management
positional arguments:
{add,create,create-initial,destroy}
add Add a monitor to an existing cluster:
ceph-deploy mon add node1
Or:
ceph-deploy mon add --address 192.168.1.10 node1
If the section for the monitor exists and defines a `mon addr` that
will be used, otherwise it will fallback by resolving the hostname to an
IP. If `--address` is used it will override all other options.
create Deploy monitors by specifying them like:
ceph-deploy mon create node1 node2 node3
If no hosts are passed it will default to use the
`mon initial members` defined in the configuration.
create-initial Will deploy for monitors defined in `mon initial
members`, wait until they form quorum and then
gatherkeys, reporting the monitor status along the
process. If monitors don't form quorum the command
will eventually time out.
destroy Completely remove Ceph MON from remote host(s)
optional arguments:
-h, --help show this help message and exit#关于ceph相关的命令,中文文档:http://docs.ceph.org.cn/rados/man/