awk命令详解(三)
前面都是两篇都是一些讲解的部分,这里记录一些小示例。
一、 命令行示例
1.1 将大于100的求和并打印所在的行,并输出求和的总数。
# seq 96 105|awk '$1>=100{sum=sum+$1;print NR,$1}END{print "sum="sum}' #这个是第一行>=100
5 100
6 101
7 102
8 103
9 104
10 105
sum=615
# seq 96 105|awk '$1>100{sum=sum+$1;print NR,$1}END{print "sum="sum}' #这里是第一行>100
6 101
7 102
8 103
9 104
10 105
sum=515
#这个例子主要是垂直数字的累加,这个在我们分析web日志的时候也是经常用到的一种用法。
博文来自:www.51niux.com
1.2、基于netstat统计网络tcp连接数的数目
#netstat -n |awk '/^tcp/{++state[$NF]}END{for(key in state)print key"\t"state[key]}'
TIME_WAIT 1
ESTABLISHED 3784
#因为netstat -n的最后一行不仅除了有tcp状态还有unix状态等,所以精确匹配我们用/^tcp/来将开头是tcp标识的行取出来,然后state[$NF]表示数据元素的值,如当匹配到第一个TIME_WAIT状态的时候,state[TIME_WAIT]就是1也就是此状态的连接数,然后++state[$NF]表示把某个状态的连接数加一,END表示在最后阶段要执行的命令不打印过程。for(key in state)就是遍历这个数组,print key"\t"state[key]就是打印数组的键和值,中间用\t制表符分隔美化输出。
netstat -n |awk '/^tcp/{++state[$NF]}{for(key in state)print key"\t"state[key]}' #下面是不带END的结果,只抓取了部分结果,是整个过程都打印的
ESTABLISHED 1
ESTABLISHED 2
ESTABLISHED 3
ESTABLISHED 4
ESTABLISHED 5
ESTABLISHED 6
ESTABLISHED 7
ESTABLISHED 8
ESTABLISHED 9
ESTABLISHED 10
ESTABLISHED 11
ESTABLISHED 12
ESTABLISHED 13
ESTABLISHED 14
ESTABLISHED 15
ESTABLISHED 16
如果我们想连udp也像一起输出呢?
#netstat -n |awk '/(^tcp|^udp)/{++state[$NF]}END{for(key in state)print key"\t"state[key]}'
TIME_WAIT 5
ESTABLISHED 3800
下面是tcp的状态描述:
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
1.3 查找请求数排名在前十的IP
#netstat -anlp|awk '/^tcp/{print $5}'|awk -F : '{print $1}'|sort|uniq -c|sort -nr|head -n 10
博文来自:www.51niux.com
1.4 对web日志的一些分析
获取访问前10位的IP地址:
#cat access.log |awk '{print $1}'|sort|uniq -c|sort -nr|head -10
获取访问前20位的链接或文件:
#cat access.log |awk '{print $11}'|sort|uniq -c|sort -nr|head -20
列出下载次数最多的前20的mp3文件:
#cat access.log |awk '($7~/\.mp3/){print $10 " " $1 " " $4 " " $7}'|sort -nr|head -20
统计传输大于200000byte(约200KB)的mp3文件以及对应文件发送的次数:
# cat access.log |awk '($10 > 200000){print $7}'|sort -n|uniq -c|sort -nr|head -20
列出文件传输时间比较长的页面:
# cat songs.access.log |awk '{print $(NF-3)" "$1 "" $4 "" $7}'|sort -nr|head -20 #这个后面的取第一个域跟日志格式有关系
统计网站流量(G):
# cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024}'
统计每秒并发前十位:
# cat access.log |awk '{if($9~/200|30|404/)COUNT[$4]++}END{for( a in COUNT) print a,COUNT[a]}'|sort -k 2 -nr|head -n10
[14/Mar/2017:11:35:29 19
[14/Mar/2017:17:26:14 16
[14/Mar/2017:11:57:08 15
[14/Mar/2017:17:26:16 12
[14/Mar/2017:00:15:16 9
[14/Mar/2017:17:26:17 8
[14/Mar/2017:08:11:29 8
[14/Mar/2017:23:55:00 7
[14/Mar/2017:23:54:55 7
[14/Mar/2017:23:55:23 6
统计http status:
# cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
188328 206
2594 404
1247 200
844 302
95 304
3 416
二、 awk运用于脚本中示例
这个我们写shell脚本的时候会经常用到awk,一般我们就是将awk的取值结果交给shell里面的变量,让shell根据值去做相关的操作
home_disk_check(){
ROOT_DISK_USE_RATE=`$DF -h|grep "/$"|awk {'print $(NF-1)'}|awk -F "%" {'print $1'}`
ROOT_DISK_FREE_RATE=`expr 100 - $ROOT_DISK_USE_RATE`
ROOT_DISK_TOTAL=`$DF -h|grep "/$"|awk {'print $(NF-4)'}`
ROOT_DISK_USE=`$DF -h|grep "/$"|awk {'print $(NF-3)'}`
ROOT_DISK_FREE=`$DF -h|grep "/$"|awk {'print $(NF-2)'}`
HOME_DISK_USE_RATE=`$DF -h|grep "/home$"|awk {'print $(NF-1)'}|awk -F "%" {'print $1'}`
HOME_DISK_FREE_RATE=`expr 100 - $HOME_DISK_USE_RATE`
HOME_DISK_TOTAL=`$DF -h|grep "/home$"|awk {'print $(NF-4)'}`
HOME_DISK_USE=`$DF -h|grep "/home$"|awk {'print $(NF-3)'}`
HOME_DISK_FREE=`$DF -h|grep "/home$"|awk {'print $(NF-2)'}`
if [[ $ROOT_DISK_FREE_RATE -gt $WARNING && $HOME_DISK_FREE_RATE -gt $WARNING ]];then
echo "DISK OK - /: free:$ROOT_DISK_FREE(total:$ROOT_DISK_TOTAL) - home: \
free:${HOME_DISK_FREE}(total:$HOME_DISK_TOTAL)"
exit $STATE_OK
elif [[ -z $ROOT_DISK_FREE || -z $HOME_DISK_FREE ]];then
echo "DISK UNKNOWN RootDisk free is:$ROOT_DISK_FREE HomeDisk free is:$HOM_DISK_FREE"
exit $STATE_UNKNOWN
elif [[ $ROOT_DISK_FREE_RATE -le $CRITICAL || $HOME_DISK_FREE_RATE -le $CRITICAL ]];then
echo "DISK CRITICAL - /: free:$ROOT_DISK_FREE(total:$ROOT_DISK_TOTAL) - home: \
free:${HOME_DISK_FREE}(total:$HOME_DISK_TOTAL)"
exit $STATE_CRITICAL
else
echo "DISK WARNING - /: free:$ROOT_DISK_FREE\(total:$ROOT_DISK_TOTAL\) - home: \
free:${HOME_DISK_FREE}\(total:$HOME_DISK_TOTAL\)"
exit $STATE_WARNING
fi
}上面其实是用的最简单的逻辑,这是磁盘报警插件里面的一个函数,就是当磁盘有home分区的时候,如何去取值,如何去做判断,没啥技术难点,只是在这里展示一下awk在shell里面的运用。
#./disk_free_check.sh -w 20 -c 10 #这是执行效果
DISK OK - /: free:16G(total:20G) - home: free:827G(total:890G)
在命令行的示例里面,记录了一下查看网络连接状态啊或者分析web日志的一些操作,这也是我们经常用到的。
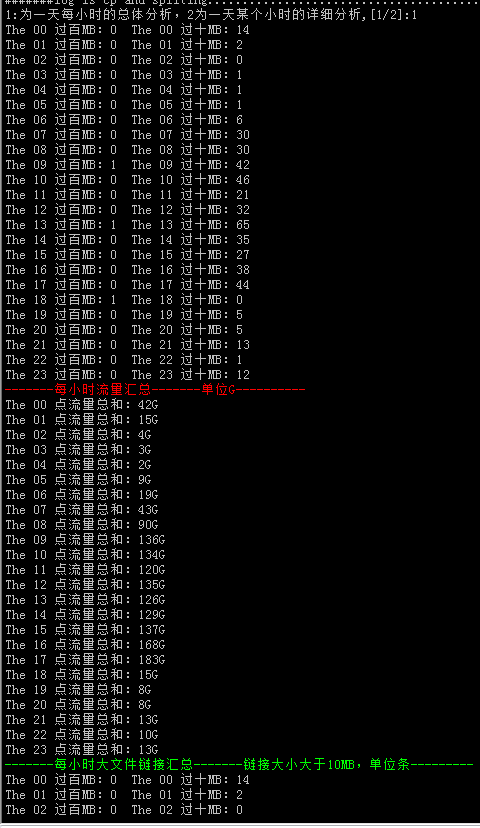
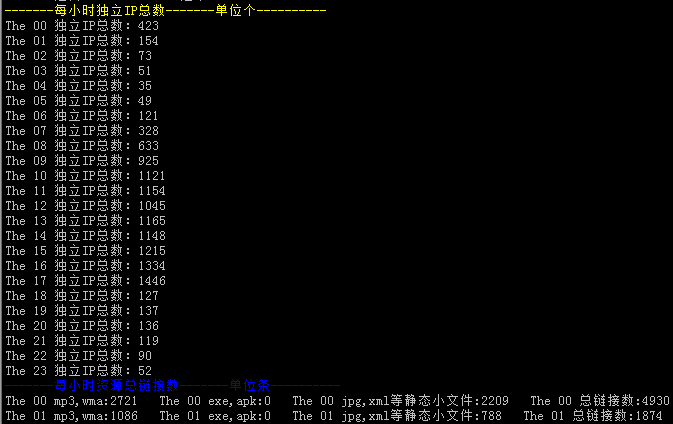
#可以做出类似于上图中的日志分析脚本,当感觉某一天有异常或者某一个时间段有异常的时候,我们可以运行脚本来分析展示出来,某一天或者某一个时间段你说需要的信息。
下面是一些分析的函数部分:
function sumtotal()
{
cd $fxdir/$logdate/
for num in `seq -w 0 23`;do a=$((`awk '{sum+=$10};END{print sum}' $num.log `/1024/1024*8/1024)) && echo "The $num 点流量>
总和:${a}G";done
}
function maxfile()
{
cd $fxdir/$logdate/
for num in `seq -w 0 23`;do echo "The $num 过百MB:`awk '{if (length($10)>8){print $3}}' $num.log|wc -l`\
The $num 过十MB:`awk '{if (length($10)==8){print $3}}' $num.log|wc -l`";done
}
function totalip()
{
cd $fxdir/$logdate/
for num in `seq -w 0 23`;do echo "The $num 独立IP总数:`awk {'print $1'} $num.log |sort -nr|uniq -c|wc -l`";done
}然后接住echo的颜色输出,输出一下:
echo -e "\e[1;31m-------每小时流量汇总-------单位G----------\e[0m" sumtotal echo -e "\e[1;32m-------每小时大文件链接汇总-------链接大小大于10MB,单位条---------\e[0m" maxfile echo -e "\e[1;33m-------每小时独立IP总数-------单位个----------\e[0m" totalip
博文来自:www.51niux.com
三、awk脚本文件运用
# awk -f romanum.awk #这是标准的执行awk脚本的格式,awk -f 指定awk脚本。这是一个求阶乘的awk脚本
Enter number: 5
The factorial of 5 is 120
# awk -f romanum.awk
Enter number: 2 4
The factorial of 2 is 2
# awk -f romanum.awk
Enter number: 2a
lnvalid entry.Enter a number:2
The factorial of 2 is 2
下面是脚本文件内容:
#! /usr/bin/awk -f
# factorial:return factorial of user-supplied number
BEGIN{
#prompt user;use printf,not print,to avoid the newline
printf("Enter number: ")
}
#check that user enter a number
$1~/^[0-9]+$/{
#assign value of $1 to number & fact
number = $1
if(number==0)
fact=1
else
fact=number
#loop to multiply fact*x until x =1
for(x=number-1;x>1;x--)
fact *=x
printf("The factorial of %d is %g\n",number,fact)
#exit --saves user from typing CRTL-D.
exit
}
#if not a number,prompt again.
{printf(" \nlnvalid entry.Enter a number:")
}#首先我们先用BEGING,初始了一个在脚本运行之初九让用户输入一个数字。
#然后我们检测第一个域也就是我们输入的内容是否是全是数字,如果不是执行:{printf(" \nlnvalid entry.Enter a number:")让其再输入一次数字。
#然后如果是的话就执行{}里面的内容。将输入$1赋值给变量number。然后判断如果number==0,则fact=1.如果不为0,fact=number。然后执行for循环。
下面是比较经典的一个成绩排名的例子:
# cat grades.txt #测试文本
xiaoming 70 77 85 83 70 89
xiaohang 85 92 78 94 88 91
xiaoshui 89 90 85 94 90 95
xiaotian 84 88 80 92 84 82
xiaozhui 64 80 60 60 61 62
xiaojing 90 98 89 96 96 92
执行效果:
# awk -f grades.awk grades.txt
xiaoming 79 C
xiaohang 88 B
xiaoshui 90.5 A
xiaotian 85 B
xiaozhui 64.5 D
xiaojing 93.5 A
Class Average: 83.4167
At or Above Average: 4
Below Average: 2
A: 2
B: 2
C: 1
D: 1
BEGIN {OFS="\t"}
#action applied to all input lines
{
# add up grades
total =0
for (i=2;i<=NF;++i)
total += $i
#calculate average
avg=total/(NF-1)
#assign student's average to element of array
student_avg[NR]=avg
#determine letter grade
if (avg>=90) grade="A"
else if (avg>=80) grade="B"
else if (avg>=70) grade="C"
else if (avg>=60) grade="D"
else grade ="F"
#increment counter for letter grade array
++class_grade[grade]
#print student name.average and letter grade
print $1,avg,grade
}
#print out class statustucs
END {
for (x=1;x<=NR;x++)
class_avg_total +=student_avg[x]
class_average=class_avg_total/NR
#detemine how mant above/below average
for (x=1;x<=NR;x++)
if (student_avg[x]>=class_average)
++above_average
else
++below_average
#print results
print ""
print "Class Average: ",class_average
print "At or Above Average: ", above_average
print "Below Average: ",below_average
#print number of students per letter grade
for (letter_grade in class_grade)
print letter_grade ":", class_grade[letter_grade]|"sort"
}#首先BEGIN {OFS="\t"}定义了水平制表符为输出字段的分隔符。然后下面一个for循环就是让每一行的成绩累加。最后每个人的最成绩就是total。然后avg就是平均成绩。
然后student_avg[NR]=avg就是将每个人的平均成绩搞成数组嘛,然后下面的if判断就是平均成绩应该对应的评分等级。++class_grade[grade]又是一个数组,不同的评分等级作为键。
然后打印名称,平均值,以及评分等级。
然后第一个for循环是算出全班平均分之和然后再处于人数,算出全班的平均分。
然后第二个for循环算出大于平均分的人数和小雨平均分的人数。
最后再输出一下我们要的结果。
