awk命令详解(一)
前面已经记录了sed和grep的详细用法,awk留到最后写一下,篇幅会很长,awk很强大很屌要好好的记录一下。介绍部分有点长,可直接跳到第二部分。
一、awk介绍
1.1 awk是什么?
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
1.2 awk的使用格式
awk [POSIX or GNU style options] -f progfile [--] file ...
awk [POSIX or GNU style options] [--] 'program' file ...
这里的program类似sed中的script,因为我们一直强调awk是一门编程语言,所以将awk的脚本视为一段代码。而awk的脚本同样可以写到一个文件中,并通过-f参数指定,这一点和sed是一样的。program一般多个pattern和action序列组成,当读入的记录匹配pattern时,才会执行相应的action命令。这里有一点要注意,在第一种形式中,除去命令行选项外,program参数一定要位于第一个位置。
标准的awk命令行参数主要由以下三个:
-F ERE:定义字段分隔符,该选项的值可以是扩展的正则表达式(ERE);
-f progfile:指定awk脚本,可以同时指定多个脚本,它们会按照在命令行中出现的顺序连接在一起;
-v assignment:定义awk变量,形式同awk中的变量赋值,即name=value,赋值发生在awk处理文本之前;
1.3 awk的内置变量
ARGC:命令行参数个数
ARGIND : 当前被处理文件的ARGV标志符
ARGV: 命令行参数数组
BINMODE: BINMODE在非POSIX系统上,指定对所有文件I / O使用“二进制”模式。 数值为1,2或3,分别指定输入文件,输出文件或所有文件应使用二进制I / O."r”或“w”的字符串值分别指定输入文件或输出文件应该使用二进制I / O。”rw”或“wr”的字符串值指定所有文件都应使用二进制I / O。 任何其他字符串值被视为“rw”,但会生成警告消息。
CONVFMT: CONVFMT默认情况下,数字的转换格式为“%.6g”。
ENVIRON: UNIX环境变量
ERRNO: ERRNO如果发生系统错误,请执行getline重定向,在读取getline期间或dur-使用close(),那么ERRNO将包含一个描述错误的字符串。 该值受制于非英语语言环境翻译。
FIELDWIDTHS : 输入字段宽度的空白分隔字符串
FILENAME: 当前输入文件的名称。 如果在命令行中未指定任何文件,则值的FILENAME为“ - ”。但是,FILENAME在BEGIN块内未定义(除非由getline设置)。
FNR: 当前记录数
FS: 输入字段分隔符 默认是空格
IGNORECASE: 如果为真,则进行忽略大小写的匹配
LINT:在AWK程序中提供对-lint选项的动态控制。 当为true,gawk打印警告。 当为false时,它不会。 当分配字符串值“fatal”时,lint警告成为致命错误,完全像--lint =致命。 任何其他真实值只打印警告。
NF: 当前记录中的字段个数,就是有多少列
NR: 已经读出的记录数,就是行号,从1开始
OFMT: 数字的输出格式,“%.6g”,默认值。
OFS: 输出字段分隔符,默认为空格。
ORS: 输出记录分隔符,默认为换行符。
PROCINFO: 包含进程信息的关联数组,例如UID,进程ID等
RS: 输入记录分隔符,默认为换行符。
RT: 记录终止符。Gawk将RT设置为与字符或规则匹配的输入文本由RS指定的表达式。
RSTART:被匹配函数匹配的字符串首
RLENGTH: 代被匹配函数匹配的字符串长度
SUBSEP : 数组子脚本的分隔符.数组子脚本的分隔符,默认为034
TEXTDOMAIN: 代表了AWK的文本域,用于查找字符串的本地化翻译。
1.4 awk的操作符
运算符
赋值运算符:
= += -= *= /= %= ^= **= 赋值语句
逻辑运算符:
|| 逻辑或
&& 逻辑与
正则运算符:
~ ~! 匹配正则表达式和不匹配正则表达式
关系运算符:
< <= > >= != == 关系运算符
算术运算符:
+ - 加,减
* / %乘,除与求余
+ - ! 一元加,减和逻辑非
^ *** 求幂
++ -- 增加或减少,作为前缀或后缀
其它运算符:
$ 字段引用
空格 字符串连接符
?: C条件表达式
in 数组中是否存在某键值
1.5 printf语句
%c : ASCII字符。 如果用于%c的参数是数字,则将其视为字符并打印。否则,假定参数为字符串,并且该字符串的唯一第一个字符打印。
%d,%i:十进制数(整数部分)。
%e,%E: 形式[ - ]的浮点数d.dddddde [+ - ] dd。 %E格式使用E而不是e。
%f,%F: 格式[ - ] ddd.dddddd的浮点数。 如果系统库支持它,则%F可用以及。 这就像%f,但是使用大写字母表示特殊的“不是数字”和“无穷大”值。 如果%F不可用,gawk使用%f。
%g,%G: 使用%e或%f转换,取较短者,抑制非零有效。 %G格式 使用%E而不是%e。
%o:无符号八进制数(也是一个整数)。
%u:无符号十进制数(再次,整数)。
%s:一个字符串。
%x,%X:无符号十六进制数(整数)。 %X格式使用ABCDEF而不是abcdef。
%%:单个%字符; 没有参数被转换。
博文来自:www.51niux.com
1.6 printf的修饰符
- :左对齐修饰符
# :显示8 进制整数时在前面加个0显示16 进制整数时在前面加0x
+ :显示使用d 、e 、f 和g 转换的整数时,加上正负号+或-
0 :用0而不是空白符来填充所显示的值
width:该字段应填充到此宽度。该字段通常用空格填充。如果0标志有已被使用,它用零填充。
.prec:指定打印时使用的精度的数字。 对于%e,%E,%f和%F,格式,这指定要打印在小数点右侧的位数。 对于%g和%G格式,它指定有效数字的最大数目。 对于%d,%o,%i,%u,%x和%垫,它指定要打印的最小位数。 对于%s,它指定的最大数目应该打印的字符串中的字符。
1.7 内置算数函数
atan2(x,y) :y,x范围内的余切
cos(x) :余弦函数
exp(x) :求幂
int(x) :取整
log(x) :自然对数
rand() :随机数
sin(x) :正弦
sqrt(x) :平方根
srand(x) :x是rand()函数的种子
int(x) :取整,过程没有舍入
rand() :产生一个大于等于0而小于1的随机数
1.8 内置字符串函数
asort(s [, d]):返回源数组中的元素数。 s的内容被排序使用gawk的常规规则来比较值,以及排序的值的索引s用从1开始的顺序整数替换。如果可选目标
指定数组d,然后首先将s复制到d中,然后对d进行排序,离开源数组的索引不变。
asorti(s [, d]):返回源数组中的元素数。 行为是一样的of asort(),除了数组索引用于排序,而不是数组值。完成后,数组将被数字索引,并且值为原始值指数。 原始值丢失; 从而提供第二个数组,服务原件。
gensub(r, s, h [, t]):搜索目标字符串t以查找正则表达式r的匹配项。 如果h是字符串从g或G开始,然后用s替换r的所有匹配。 否则,h是数字指示r的哪个匹配来替换。 如果不提供t,则使用$ 0。 在替换文本s内,序列\ n(其中n是从1到9的数字)可以是用于仅指示与第n个括号子表达式匹配的文本。 的
sequence \ 0表示整个匹配的文本,如字符&。 不像sub()和gsub(),作为函数的结果返回修改的字符串,并且原始目标字符串不更改。
gsub(r, s [, t]):对于与字符串t中的正则表达式r匹配的每个子字符串,替换字符串s,并返回替换数。 如果不提供t,使用$ 0。 An&在替换文本中替换为实际匹配的文本。 使用\&来得到一个文字&。
index(s, t):返回字符串s中字符串t的索引,如果t不存在,则返回0。 (这个意味着字符索引从一开始.)
length([s]):返回字符串s的长度,如果未提供s,则返回$ 0的长度。 length()返回数组中元素的数量。
match(s, r [, a]):返回正则表达式r出现的位置,如果r不为0,则返回0存在,并设置RSTART和RLENGTH的值。 注意参数顺序是与〜操作符相同:str〜re。 如果提供了数组a,则a被清零则元素1到n被填充以与对应关系匹配的s的部分,在r中的括号子表达式。 a的第0个元素包含s的一部分匹配整个正则表达式r。 下标a [n,“开始”]和a [n,“length”]分别提供字符串中的起始索引和长度匹配子字符串。
split(s, a [, r]):将字符串s拆分为正则表达式r上的数组a,并返回num-字段。 如果省略r,则使用FS。 首先清除数组a。分裂的行为与场分裂的行为相同,如上所述。
sprintf(fmt, expr-list):返回根据printf格式说明指定的格式化的字符串,它格式化数据但不输出数据。
strtonum(str):检查str,并返回其数值。 如果str以前导0开头,则str-tonum()假设str是一个八进制数。 如果str以前导0x或0X开头strtonum()假定str是一个十六进制数。
sub(r,s [,t]):就像gsub(),但只有第一个匹配的子字符串被替换。
substr(s,i [,n]):返回从i开始的s的最多n个字符子串。 如果省略n,使用其余的s。
tolower(str):返回字符串str的副本,所有大写字符都在str中翻译到他们相应的小写同行。 留下非字母字符不变。
toupper(str):返回字符串str的副本,其中所有小写字符都在str中翻译到它们相应的大写副本。 留下非字母字符不变。
1.9 时间函数
mktime(datespec):将datespec转换为与systime()返回的形式相同的时间戳。 datespec是一个字符串形式为YYYY MM DD HH MM SS [DST]。字符串的内容是六个或七个数字,分别发送全年包括世纪,月份从1到12,月份从1到31,一天的时间从0到23,分钟从0到59,第二个从0到60,和可选的夏令时标志。这些数字的值不必在该范围内指定;例如,-1小时表示午夜之前1小时。原始零格里高利 dar,其中0年前面的年1和年0之前0年。假设时间为在当地时区。如果夏令时标志为正,则假定时间为日光节约时间;如果为零,则假定时间为标准时间;如果为负(默认),mktime()尝试确定夏令时是否在指定时间内有效。如果datespec不包含足够的元素,或者如果结果时间超出范围,mktime()返回 -1。
strftime([format [, timestamp[, utc-flag]]]):根据格式的规范格式化时间戳。 如果utc-flag存在并且不为零或非空,结果是在UTC,否则结果是在本地时间。 时间戳应为与systime()返回的形式相同。 如果缺少时间戳,则使用当前时间。如果缺少格式,则使用与date(1)的输出等效的默认格式。 请参阅“在ANSI C中的strftime()函数的阳离子保证格式转换可用。
systime():将当前时间作为自纪元以来的秒数返回(1970-01-01 00:00:00 UTC POSIX系统)。
时间和日期的格式:
%a 星期几的缩写(Sun)
%A 星期几的完整写法(Sunday)
%b 月名的缩写(Oct)
%B 月名的完整写法(October)
%c 本地日期和时间
%d 十进制日期
%D 日期 08/20/99
%e 日期,如果只有一位会补上一个空格
%H 用十进制表示24小时格式的小时
%I 用十进制表示12小时格式的小时
%j 从1月1日起一年中的第几天
%m 十进制表示的月份
%M 十进制表示的分钟
%p 12小时表示法(AM/PM)
%S 十进制表示的秒
%U 十进制表示的一年中的第几个星期(星期天作为一个星期的开始)
%w 十进制表示的星期几(星期天是0)
%W 十进制表示的一年中的第几个星期(星期一作为一个星期的开始)
%x 重新设置本地日期(08/20/99)
%X 重新设置本地时间(12:00:00)
%y 两位数字表示的年(99)
%Y 当前月份
%Z 时区(PDT)
%% 百分号(%)
博文来自:www.51niux.com
二、 awk 入门示例
示例1,切割内容并取出指定行
# cat /etc/passwd|grep qemu #我们先将要操作的内容过滤出来,在qemu user之间有个空格
qemu:x:107:107:qemu user:/:/sbin/nologin
# cat /etc/passwd|grep qemu|awk {'print $1'} #现在我们取出这一行的第一个区域,$1代表第一块,注意一定要用''单引号,也可以是awk '{print $1}'
qemu:x:107:107:qemu
# cat /etc/passwd|grep qemu|awk {'print $2'} #现在我们取出第二个区域,$2当然代表第二块了。
user:/:/sbin/nologin
# cat /etc/passwd|grep qemu|awk {'print $NF'} #当然这一行只有两个部分,$NF代表最后一部分,在切割的片数比较多的行,这个还是很有用的。
user:/:/sbin/nologin
#从上面三个例子可以看出,$n代表是要取第几个片,然后默认是以空格来作为每一行数据切片的分隔符。
# cat /etc/passwd|grep qemu|awk -F ":" {'print $0'} #$0就表示这一整行,$0保存的是记录初始的整串值(包括刚读进来时候的分隔符)
qemu:x:107:107:qemu user:/:/sbin/nologin
# cat /etc/passwd|grep qemu|awk {'print $(0+1)'} #这个作用倒不是太大,不过告诉我们()里面的值是可以相加的,那还不如直接$1得了呢。
qemu:x:107:107:qemu
示例2,指定分隔符来切割数据划片
# cat /etc/passwd|grep qemu|awk -F ":" '{print $1}' #还拿上面那句话举个例子,-F "分隔符",我们这里指定了:来做分隔符,可以看到第一片为qemu了
qemu
# cat /etc/passwd|grep qemu|awk -F "[:/]" {'print $NF'} #“[]”里面可以制定多个分隔符,我们这里就是制定了:和/两个都作为分隔符。
nologin
# echo "qemu:x:107:107:qemu user:/:/:/sbin/nologin"|awk -F "[:/]+" {'print $(NF-2)'}
qemu user
#awk -F ":|/| " #当然还有这种用法,双引号里面是:/和空格,用管道符分开,当然很少用。
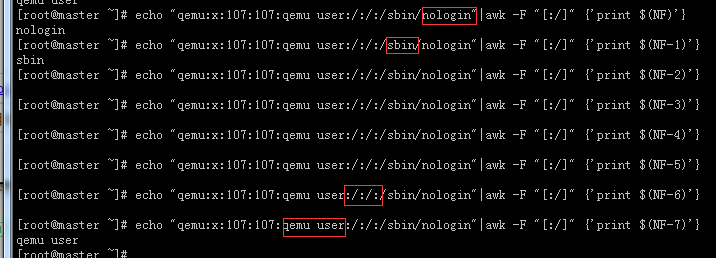
#这里是两个知识点,首先(NF-2)就是代表取倒数第三行,这个用法是经常用到的,那么(NF-1)就是取倒数第二行。另一个就是[:/]+为什么要加+号呢,代表以1个或多个:/来做分隔符,如果你不加的话,当一行内容中出现多个分隔符在一起的情况,就会出现取出来是空值得情况。如出现上图中的情况,你取值是不理想的。
# echo "qemu:x:107:107:qemu user:/:/:/sbin/nologin"|awk -F "[:/]" {'print $1;print $2;print $3;print $NF'} #还可以这样打印,不做这个用法很少用。
qemu
x
107
nologin
示例3,显示多行内容并自定义显示
# cat /etc/passwd|grep ldap #要处理的内容
ldap:x:55:55:LDAP User:/var/lib/ldap:/sbin/nologin
ldapuser01:x:2531:2532::/home/ldapuser01:/bin/bash
ldapuser02:x:2532:2533::/home/ldapuser02:/bin/bash
ldaptest1:x:2533:2534::/home/ldaptest1:/bin/bash
ldaptest2:x:2534:2535::/home/ldaptest2:/bin/bash
# cat /etc/passwd|grep ldap|awk -F ":" '{print $1 $NF}' #可以制定输出多列的但是你可以发现$1和$NF里面制定的空格是没用的,内容还是连在了一起
ldap/sbin/nologin
ldapuser01/bin/bash
ldapuser02/bin/bash
ldaptest1/bin/bash
ldaptest2/bin/bash
# cat /etc/passwd|grep ldap|awk -F ":" '{print $1,$(NF-1),$NF}' #我们可以用,逗号将输出的内容分开一下,中间以空行隔开
ldap /var/lib/ldap /sbin/nologin
ldapuser01 /home/ldapuser01 /bin/bash
ldapuser02 /home/ldapuser02 /bin/bash
ldaptest1 /home/ldaptest1 /bin/bash
ldaptest2 /home/ldaptest2 /bin/bash
# cat /etc/passwd|grep ldap|awk -F ":" '{print $1"\t"$(NF)"\tline:---"$(NF-1)}' #首先我们输出的块区域不用按顺序来,另外用“”双引号里面制定分隔符的形式可以来自定义分隔符,这里我就制定了$1"\t"$(NF)用[tab]来分隔,(NF)"---"$(NF-1)之间用[tab]line:--来分隔。
ldap /sbin/nologin line:---/var/lib/ldap
ldapuser01 /bin/bash line:---/home/ldapuser01
ldapuser02 /bin/bash line:---/home/ldapuser02
ldaptest1 /bin/bash line:---/home/ldaptest1
ldaptest2 /bin/bash line:---/home/ldaptest2
示例4,打印指定行
# awk '/root/' /etc/passwd #打印文件中带有root关键字的行
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
# awk '/^root/,/^adm/' /etc/passwd #打印文件中开头是root的行到开头是adm关键字的行
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
# awk 'NR==1 {print $0}' /etc/passwd #打印第一行一整行
root:x:0:0:root:/root:/bin/bash
# awk 'NR==10,NR==15 {print NR,$0}' /etc/passwd #打印10到15行的内容,# awk 'NR==10,NR==15 {print }' /etc/passwd 也可以的但是不显示行号
10 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
11 operator:x:11:0:operator:/root:/sbin/nologin
12 games:x:12:100:games:/usr/games:/sbin/nologin
13 gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
14 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
15 nobody:x:99:99:Nobody:/:/sbin/nologin
# awk -F ":" 'END {print $NF}' /etc/passwd #指定:为分隔符,打印最后一行的最后一列
/sbin/nologin
# awk '/^root/,/^adm/{print NR,$0}' /etc/passwd #打印匹配内容的行号,NR示awk开始执行程序后所读取的数据行数
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
# awk 'END{print NR,$1}' /etc/passwd|awk {'print $1'} #那这又是一种获取一个文件行数的方法
55
# awk -F "[: /]+" {'print NR,NF,$1,$NF'} /etc/passwd|head -3 #NR代表文件当前的记录号也就是行号,NF代表被切割的域数,以及第一个和最后域
1 8 root bash
2 8 bin nologin
3 8 daemon nologin
博文来自:www.51niux.com
三、内置变量示例
示例1,NR和FNR的对比
FNR与NR功能类似,不同的是awk每打开一个新文件,FNR便从0重新累计,而NR表示awk开始执行程序后所读取的数据行数。
# cat /root/2.txt #测试文本
a
b
# cat /root/3.txt #测试文本
c
d
# awk '{print NR,$0}' /root/2.txt /root/3.txt #NR累计行数
1 a
2 b
3 c
4 d
# awk '{print FNR,$0}' /root/2.txt /root/3.txt #FNR不累计行数
1 a
2 b
1 c
2 d
示例2,FS和OFS的对比
FS是输入分隔符,默认是空格或者tab,OFS是输出分隔符,默认是一个空格。前面已经接触到了#awk -F: '{print $1,$NF}' /etc/passwd,:就是FS得值,逗号就是OFS的值。
# echo "aaa bbb"|awk '{OFS="#";print $1,$2}'
aaa#bbb
# echo "aaa bbb"|awk 'BEGIN{OFS="#"}{print $1,$2}' #BEGIN是程序初始阶段还没有进行文本处理之前执行的语句。
aaa#bbb
# echo "aa#a b#bb"|awk 'BEGIN{FS="#"}END{print $1}' #或者就是这种形式,让BEGIN预设内部变量FS。BEGIN一个很重要作用是awk读取输入文件之前可以给内置变量赋值,然后再读取输入文件,这样就可以避免了先按照默认分隔符来操作第一行,然后从文件第二行开始再用新的分隔符来执行。
aa #所以如果是简单的操作,就直接用-F ""指定分隔符的这种形式就可以了,下面的一个例子是针对上面的解释举例。
# cat 3.txt 测试文本
aa#a bb#b
c#cc dd#d
# cat 3.txt |awk '{FS="#";print $1}' #第一行还是按照默认的空格进行的分隔
aa#a
c
# cat 3.txt |awk '{FS="#";print $2}' #第二行按照新的分隔符来执行了。
bb#b
cc dd
示例3,小例子对$0的重构
# cat 3.txt |awk '{OFS=":";print $1,$2"\t"$0}' #可以看到$0是没有变化的,因为$0在初始的时候会存储一份,也就是初始值,跟$1它们是分开存放的。
aa#a:bb#b aa#a bb#b
c#cc:dd#d c#cc dd#d
# cat 3.txt |awk '{OFS=":";$2=$2;print $0}' #如果给字段变量赋一个新值,那么awk会自动地使用内部变量OFS重新生成$0
aa#a:bb#b
c#cc:dd#d
示例4,RS和ORS的对比
# cat 3.txt |awk 'BEGIN {RS="#"}{print}' #RS输入分隔符,缺省为\n。
aa
a bb
b
c
cc dd
d
# awk 'BEGIN{ FS = "#";RS=""} {$2=$2;print $0}' 3.txt #NF配合RS似乎能变得很有意思。
aa a bb b c cc dd d
# awk 'BEGIN{ FS = "#";RS=""} {$2=$2;print $NF}' 3.txt
d
# awk 'BEGIN {ORS=";"}{print}' 3.txt #ORS输出记录分隔符,缺省为换行符
aa#a bb#b;c#cc dd#d;
# cat 3.test #测试文本,我们只输出分隔符分割的域,有三行内容以上的。
TAG 1
aaa
bbb
TAG 2
ccc
ddd
eee
fff
TAG 3
ggg
hhh
yyy
# awk -vRS="TAG [0-9]+" 'NF>2{for(i=1;i<=NF;i++){print NR-1,$i}}' 3.test
2 ccc
2 ddd
2 eee
2 fff
3 ggg
3 hhh
3 yyy
#上面的例子,就是以TAG数字来分隔,然后判断行数大于2的就累加输出。结合下面的输出再理解一下。
# awk -vRS="TAG [0-9]+" {'print $0,NF'} 3.test
0
aaa
bbb
2
ccc
ddd
eee
fff
4
ggg
hhh
yyy
3
# awk -vRS="TAG [0-9]+" {'print $0,NR'} 3.test
1
aaa
bbb
2
ccc
ddd
eee
fff
3
ggg
hhh
yyy
4
示例5、ARGC、ARGV和FILENAME的对比
# awk {'print ARGC'} 3.txt #ARGC:代表命令行上除了选项-v, -f 及其对应的参数之外所有参数的个数。print ARGC显示我们有两个参数。
2
2
# awk {'print ARGV[0],ARGV[1]'} 3.txt # ARGV[ ] 是一字符串数组,ARGV[0],ARGV[1],。。。ARGV[ARGC-1]分别代表命令行上相对应的参数。
awk 3.txt #可见我们第一个参数是awk ,第二个参数才是文件3.txt。
awk 3.txt
# awk {'print FILENAME'} 3.txt 2.txt #3.txt和2.txt里面都是两行内容,所以打印了两个3.txt,打印了两个2.txt,FILENAME表示打印当前文件名
3.txt
3.txt
2.txt
2.txt
写一个简单的for循环格式输出打印ARGV[n]里的内容
# awk 'BEGIN{for (i=0;i<ARGC-1;++i){printf "ARGV[%d] = %s\n",i,ARGV[i]}}' 3.txt 2.txt #i<ARGC-1 就是ARGC在这里应该是3,所以就是i<2
ARGV[0] = awk
ARGV[1] = 3.txt
# awk 'BEGIN{for (i=0;i<ARGC;++i){printf "ARGV[%d] = %s\n",i,ARGV[i]}}' 3.txt 2.txt
ARGV[0] = awk
ARGV[1] = 3.txt
ARGV[2] = 2.txt
#首先现在BEGIN里面定义好:for (i=0;i<ARGC;++i):for循环,i从0开始,当i<3的时候符合循环条件,++1就是为了让循环执行下去,每次自加1.先从0开始,然后0+1=1,再回来判断是否<ARGC,如果匹配就再次循环,以此类推。printf :printf是格式化打印,ARGV[%d] = %s\n :%d和%s一个表示数字行书一个表示字符串形式,他们都等着被后方传参呢,,i,ARGV[i] :i将值传给了前面的%d,ARGV[i]将值传给了前面的%s,顺序不能乱哦。
如下面:
# awk 'BEGIN{for (i=0;i<ARGC;++i){printf "ARGV[%s] = %s\n",ARGV[i],i}}' 3.txt 2.txt #ARGV[i],i顺序变了,下面的输出也就发生了更改,ARGV[%s]就要从ARGV[%d]变成ARGV[%s],因为%d是数字格式不支持字符串的输入。
ARGV[awk] = 0
ARGV[3.txt] = 1
ARGV[2.txt] = 2
示例6、ARGIND的用法
# awk {'print ARGIND'} 3.txt 2.txt #ARGIND是命令行中当前文件的位置
1
1
2
2
# cat 2.txt
a
b
# cat 3.txt
aa#a bb#b
c#cc dd#d
a
比较两个文件,列出3.txt里面完全不包含2.txt里面的行,也就是要将3.txt文件里面的a去掉,只输出前两行。
# awk 'ARGIND==1 {a[$0]} ARGIND>1&&!($0 in a) {print $0}' 2.txt 3.txt
aa#a bb#b
c#cc dd#d
#当ARGIN==1,也就是当正在处理文件2.txt的时候{a[$0]}初始化也就是对2.txt里面的内容进行初始化,ARGIND>1&&!($0 in a)当处理第二个文件或者第N个文件的时候反正不是第一个文件的时候,我们这里第二个文件是3.txt,并且判断$0是没有在a中定义因为我们加了!,{print $0}就打印出来那一行。
示例7、CONVFMT的用法
# awk 'BEGIN{a=100;b="10test20";print(a+b);}'
110
# awk 'BEGIN{a=100;b="20test20";print(a+b);}'
120
# awk 'BEGIN{a=100;b="20test20";print(a b);}'
10020test20
#先了解上面的用法。awk的action必须被{}包括,各个不同的action之间以换行或者分号分隔。awk中使用+进行假发运算,自动将字符串转换为整数。如若在字符串中遇到非数字符,则将其及后面的字符作为0加到前面的数值中。连接字符串或者连接数字和字符串时,只需将字符串变量卸载一起并用括号括起来,但是字符串变量之间一定要加空格。
# awk 'BEGIN{a=123.321;print a " is a number";print a+1.654}' #这是没有加CONVFMT的效果输出。
123.321 is a number
124.975
# awk 'BEGIN{a=123.321;CONVFMT="/%3.1f";print a " is a number";print a+1.654}' #CONVFMT="/%3.1f";将数字格式定义为小数点后面留一位。
/123.3 is a number
124.975
#awk提供内置变量CONVFMT定义浮点数(整数转字符串时不受影响)转换为字符串时的格式规则。对变量进行转字符串操作后,浮点数不会按照CONVFMT定义的精度重新赋值,而是保持原来的值。
示例8、ENVIRON的用法
# awk 'BEGIN{print ENVIRON["USER"];}'
root
# awk 'BEGIN{print ENVIRON["HOSTNAME"];}'
master.hadoop
# ENVIRON获取linux的环境变量。通过 ENVIRON[](字典型数组),可以通过对应键值获得它的值。那么键值在哪里查看呢?# env来查看
示例9、FIELDWIDTHS的用法
20170311112220是一个时间戳,我们如何将它转换为标准的时间格式呢?
# echo "20170311112220"|awk 'BEGIN{FIELDWIDTHS="4 2 2 2 2 2"}{print $1"-"$2"-"$3,$4":"$5":"$6}'
2017-03-11 11:22:20
#FIELDWIDTHS是按宽度来分隔一行数据,这时候FS分隔符已经被忽略了。"4 2 2 2 2 2" 宽度之间必须以空格隔开。4就代表$1的宽度,以此类推
# cat 3.txt #测试文本
aa#a bb#b
c#cc dd#d
a
# awk 'BEGIN{FIELDWIDTHS="1 2 3 2 2 2"}{print $1"-"$2"-"$3"-"$4"|"$5}' 3.txt
a-a#-a b-b#|b
c-#c-c d-d#|d
a---|
示例10、IGNORECASE的用法
# cat 1.test #测试文本
abc 321
ABC 123
AB zouni
erdadsa
BC haha
12321 BC
sadsadsadsadsa
vxcxzbnz
dsadsa
# awk '$1~"[A-Z]"{print NR,$1,$NF}' 1.test #这里我们先过滤第一行是开些的行,并输出行号,第一列和最后一列。
2 ABC 123
3 AB zouni
5 BC haha
# awk 'BEGIN{IGNORECASE=1}$1~"[A-Z]"{print NR,$1,$NF}' 1.test #IGNORECASE=1就表示,忽略大小写,可以看到结果没有第一行是数字的
1 abc 321
2 ABC 123
3 AB zouni
4 erdadsa erdadsa
5 BC haha
7 sadsadsadsadsa sadsadsadsadsa
8 vxcxzbnz vxcxzbnz
9 dsadsa dsadsa
示例11、 LINT用法
# awk '$1==ABC{print NR,$1,$NF}' 1.test #这句话是错误的,但是Warning信息默认是不输出的
# awk --lint '$1==ABC{print NR,$1,$NF}' 1.test #该选项允许检查程序的不兼容性或者模棱两可的代码,当提供参数 fatal的时候,它会对待Warning消息作为Error。默认--lint就相当于--lint=[fatal]
awk: (FILENAME=1.test FNR=1) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=2) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=3) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=4) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=5) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=6) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=7) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=8) warning: reference to uninitialized variable `ABC'
awk: (FILENAME=1.test FNR=9) warning: reference to uninitialized variable `ABC'
博文来自:www.51niux.com
示例12、OFMT的用法
# awk 'BEGIN{a=123.321;OFMT="%.2f";print a;print a+1.654}' #打印数字的时候,可以用OFMT来限制数字的格式。%.2f:%表示接下来要定义的格式,.2就表示打印浮点数的时候打印小数点后面的两位 。
123.32
124.97
# awk 'BEGIN{a=123.321;OFMT="%.2f";print a " is a number";print a+1.654}' #通过这个例子可以看出123.321 is a number已经变成了字符串,所以是不生效的。
123.321 is a number
124.97
示例13、PROCINFO的用法
# awk --version
GNU Awk 3.1.7
# awk 'BEGIN{print PROCINFO["version"]}'
3.1.7
#awk进程信息数组,指标可以使egid,euid, gid ,pgrpid, pid, ppid, uid, version
示例14、RT的用法
# echo "111 aaa|222 bbb|333 ccc"|awk 'BEGIN{RS="|"}{print $0,RT}'
111 aaa |
222 bbb |
333 ccc
# echo "111 aaa|222 bbb|333 ccc"|awk 'BEGIN{RS="|"}{print RT}'
|
|
#当RT是利用RS匹配出来的内容。如果RS是某个固定的值时,RT就是RS的内容。
# echo "111 aaa|222 bbb|333 ccc"|awk 'BEGIN{RS="[a-z]+"}{print $0,RS,RT}'
111 [a-z]+ aaa
|222 [a-z]+ bbb
|333 [a-z]+ ccc
[a-z]+
[root@master ~]# echo "111 aaa|222 bbb|333 ccc"|awk 'BEGIN{RS="[a-z]+"}{print RT}'
aaa
bbb
ccc
#把RS记录分割符设置成一个正则,匹配一个或多个字母的字符段为记录分割符。RT就是当RS为正则表达式时的匹配到的每个记录的分割符的内容即为RT变量表示。
# echo "111 aaa|222 bbb|333 ccc"|awk -v RS='[0-9]+' '{s+=RT}END{print s}'
666
#上面的例子是将出现的数字相加,那么我们就让RS指定数字为分隔符,这样RT就相当于数字了,然后我们让RT累加,最后END只打印最后结果而不打印过程,所以最后print s,就是我们最后所有数字相加的结果。
示例15、RSTART和RLENGTH的使用
# awk 'BEGIN{start=match("Abcd Ef Kig",/ [A-Z][a-z]+ /);print RSTART,RLENGTH}' #"Abcd Ef Kig" 这个字符匹配的是“空格大写字符小写字符+空格”,可以看到第一个匹配的条件是Ef,然后他的位置是Abcd的后面,正好是第五个位置,然后空格Ef空格,长度正好是4
5 4
# awk 'BEGIN{start=match("Abcde Ef Kig",/ [A-Z][a-z]+ /);print RSTART,RLENGTH}' #我这里将Abcd变成了Abcde,然后开始位置就变成了6
6 4
# awk 'BEGIN{start=match("Abcde Eaf Kig",/ [A-Z][a-z]+ /);print RSTART,RLENGTH}' #我这里将Ef变为了Eaf,开始位置没有变化,长度发生了变化
6 5
# awk 'BEGIN{start=match("Abcde E1f Kig",/ [A-Z][a-z]+ /);print RSTART,RLENGTH}' #这里没有匹配的条件,所以返回了0,长度用-1表示。
0 -1
#这里用到的是match函数的普通用法,match(字符串,正则表达式)内置变量RSTART表示匹配开始的位置,RLENGTH表示匹配的长度,如果匹配到了,返回匹配到的开始位置,否则返回0
另外:
gawk允许用户自定义自己的变量以便在程序代码中使用,变量名命名规则与大多数编程语言相同,只能使用字母、数字和下划线,且不能以数字开头。gawk变量名称区分字符大小写。
在脚本中赋值变量:
在gawk中给变量赋值使用赋值语句进行
在命令行中使用赋值变量 :
gawk命令也可以在“脚本”外为变量赋值,并在脚本中进行引用。
如:
输出一个变量,并赋值
# awk 'BEGIN{v="jiushi test testing";print v}'
jiushi test testing
# awk -v var="yiqi test" 'BEGIN{print var}'
yiqi test
