Centos7.2 ganglia(三)之详解和扩展
一、 ganglia指标详解
1.1 基本指标(默认的gmond指标)
cpu metrics(12):
cpu_aidle:自启动开始CPU空闲时间所占百分比,单位是百分比
#cpu_ctxt:自系统启动以来CPU发生的上下文交换的次数,单位是每秒多少次
cpu_idle:CPU空闲,系统没有显著磁盘I/O请求的时间所占的百分比
#cpu_intr :CPU参与I/O终端的时间所占百分比
cpu_nice : 以user level、nice level 运行时的CPU占用率,单位百分比
#cpu_sintr :CPU参与I/O软中断的时间所占的百分比,单位百分比
cpu_steal :管理程序维护另一个虚拟处理器时,虚拟 CPU 等待实际 CPU 的时间的百分比。(Steal 值比较高的话,你需要向主机供应商申请扩容虚拟机。服务器上的另一个虚拟机可能拥有更大更多的 CPU 时间片,你可能需要申请升级以与之竞争。低 steal 值意味着你的应用程序在目前的虚拟机上运作良好。因为你的虚拟机不会经常地为了 CPU 时间与其它虚拟机激烈竞争,虚拟机会更快地响应。)
cpu_system: 系统进程对CPU的占用率。
cpu_user: 以user level运行时的CPU占用率
cpu_wio: 用于进程等待磁盘I/O而使CPU处于空闲状态的百分比
#procs_blocked:被资源阻塞的任务数(I/O,页面调度,等等.)通常情况下是接近0的
#procs_created :线程创建的耗时
disk metrics(5):
disk_free:所有分区的总空闲磁盘空间。
#disk_free_absolute_rootfs:根分区的磁盘剩余空间。
#disk_free_percent_rootfs:根分区的剩余空间的百分比。
disk_total:总存储空间。
part_max_used:所有分区已经占用的百分比。
load metrics(3):
load_fifteen:十五分钟平均负荷
load_five:五分钟平均负荷
load_one:一分钟平均负荷
mem_buffers(5):
mem_buffers: 缓冲(buffer)内存容量
mem_cached: 缓存(cache)容量
mem_free: 可用内存容量
mem_shared: 共享内存容量
swap_free: 可用交换内存容量
network metrics(4):
bytes_in: 每秒收到的字节数
bytes_out: 每秒发出的字节数
pkts_in:每秒收到的包数
pkts_out:每秒发出的包数
process metrics:
proc_run:正在运行的进程总数
proc_total:进程总数
另外系统的指标:
os_release: 操作系统发布日期,字符串类型
gexec: gexec可用,布尔类型
mtu: 网络最大传输单位,整数型
location: 主机位置,字符串类型
os_name: 操作系统名称,字符串类型
boottime: 系统最近启动时间
sys_clock: 系统时钟时间,单位是时间
heartbeat: 上一次心跳发送时间,整数型
machine_type: 系统架构,字符串类型
博文来自:www.51niux.com
二、gmond利用Mod_python模块扩展性能指标
使用固定指标集合会对主机占用很少,但是想要需要基础指标之外的性能指标的话,就需要扩展功能。如果采用模块接口的方式扩展gmond,用户可以通过配置将gmond的主机占用到可控。
Mod_Python是一种gmond指标模块,但是本身并不手机指标,而是作为其他指标收集模块的代理。Mod_Python使用C语言编写,其主要目的是为其他gmond模块运行提供一个内嵌的Python脚本语言环境。
如果你的gmond是通过rpm包安装的形式安装的,会发现此主机gweb上面所显示的指标明显比编译安装方式显示的指标要多很多,那是因为rpm包安装的时候默认已经讲python第三方扩展模块开启了,rpm包的pyconf文件所在的位置是:/etc/ganglia/conf.d,如果是编译安装呢,这些文件默认是在源码包的gmond/python_modules下面,要将对应的.py文件复制到modpython.conf里面指定的python_modules下面。
在编译安装的时候ganglia已经自动安装了对python的支持,该动态可加载模块路径为:/usr/local/ganglia/lib64/ganglia/modpython.so。相对应的配置文件为:/usr/local/ganglia/etc/conf.d/modpython.conf。
下面为通过rpm包安装的方式配置文件里面的内容 :
#cat /usr/local/ganglia/etc/conf.d/modpython.conf
modules {
module {
name = "python_module" #注意这里name取值必须和Python模块的.py文件的名字相匹配。
path = "modpython.so" #模块的名称
params = "/usr/local/ganglia/lib64/ganglia/python_modules" #Mod_python会在该位置搜索以.py结尾的文件
}
}
include ("/usr/local/ganglia/etc/conf.d/*.pyconf") #Python模块配置文件的扩展名推荐为.pyconf,这里指定了pyconf文件所在的位置。
经过上面知识讲解,我们来手工为编译安装的版本添加一个第三方的指标:
第一步:修改modpython.conf配置文件
# cat /usr/local/ganglia/etc/conf.d/modpython.conf
modules {
module {
name = "python_module"
path = "modpython.so"
params = "/usr/local/ganglia/lib64/python_modules" #将目录修改一下
}
}
include ("/usr/local/ganglia/etc/conf.d/*.pyconf")
第二步:创建目录以及拷贝py文件
# mkdir /usr/local/ganglia/lib64/python_modules #创建存放.py文件的目录
# cp /tools/ganglia-3.7.2/gmond/python_modules/*/*.py /usr/local/ganglia/lib64/python_modules/ #将所有的源码包中的py文件拷贝到我们设置的目录
# ln -s /usr/local/ganglia/lib64/ganglia/modpython.so /usr/local/ganglia/lib64/python_modules/
第三步:创建python指标模块文件
# cd /usr/local/ganglia/etc/conf.d/
# vi mem_stats.pyconf
modules {
module {
name = "mem_stats" #这里的名称的取值必须和Python模块的.py文件的名字相匹配。
language = "python" #这里语言必须是python,因为我们是用的python加载扩展模块
}
}
collection_group {
collect_every = 30
time_threshold = 45
metric {
name = "mem_writeback"
title = "Mem actively being written to disk"
value_threshold = 1.0
}
metric {
name = "mem_dirty"
title = "Mem waiting to be written to disk"
value_threshold = 1.0
}
metric {
name = "mem_anonpages"
title = "AnonPages"
value_threshold = 1.0
}
metric {
name = "mem_mapped"
title = "Memory Mapped"
value_threshold = 1.0
}
metric {
name = "mem_hardware_corrupted"
title = "Memory HardwareCorrupted"
value_threshold = 1.0
}
}
查看效果(memory的指标从基本的5个变为了10个,我们创建的那五个指标生效了):

#第三方模块就是这样创建,如果希望再自定义,就需要就自己编写py文件了,如果就用源码包中自带的就足够的话,因为大部分是用不到的嘛,可以自己更改下.pyconf文件并将.py文件打包,来通过cp的方式让其他节点也有扩展。
三、一些问题:
1.通过日志查找问题:
# /usr/local/ganglia/sbin/gmond -d 10 >/tmp/gmond.log 2>&1 #调试模式运行gmond实例,将其输出导入到指定文件,以便我们进行查看。
2.通过命令快速查看情况
# /usr/local/ganglia/bin/gstat -a1n #加了n之后就是以IP地址进行表示,查看集群中所有主机的信息清单,如CPU内核数、正在运行的进程数、负载等。
# /usr/local/ganglia/bin/gstat -d #列出故障主机
3.dns问题
当gmond第一次接收到来自其他节点的指标数据包时,必须进行名称查找以确定与数据源地址相匹配的主机名。
如果/etc/hosts即可满足查找,那么该过程将非常迅速;如果必须通过DNS查找,则该查找过程会降低进程速度,gmond是单线程设计,在首次启动时,需要对操作前一到两分钟内接收到的所有数据包进行类似的名称查找。如果大量的主机同时发送数据包,或者DNS速度缓慢甚至不可用,一切正常运行之前,所有的指标数据都无法手机。所以最好在接受指标的主机,将这些主机的的主机名添加到/etc/hosts文件中。
4. 时间同步
所有被Ganglia系统监控的主机都要保持时间同步。
博文来自:www.51niux.com
四、ganglia的gmetad层次结构
4.1 gangjia结构说明
父级gmetad:192.168.1.102(从192.168.1.101和192.168.1.102组里收集信息)
子级gmetad:192.168.1.101(负责收集test1和test2组的信息),192.168.1.110(负责收集test3组的信息)
单播组:test1(192.168.1.103,192.168.1.104,192.168.1.105) 192.168.1.103:8666 192.168.1.104:8666 为中心节点
多播组:test2(192.168.1.101,192.168.1.106,192.168.1.107) 192.168.1.106:8668 192.168.1.107:8668 为中心节点
单组播混合组:test3(192.168.1.108,192.168.1.109,192.168.1.111,192.168.1.112)192.168.1.108:8666 为中心节点
单组播混合组:test4(192.168.1.108,192.168.1.109,192.168.1.111,192.168.1.112)192.168.1.109:8667为中心节点
4.2 各节点配置的搭建
4.2.1 test3和test4组里面节点的搭建(只粘贴部分需要修改的地方,所有gmond的端口以中心节点的端口为主,非默认的8649端口)
192.168.1.110(gmetad服务的配置):
# cat /usr/local/ganglia/etc/gmetad.conf #增加下面两个组
data_source "test3" 192.168.1.108:8666
data_source "test4" 192.168.1.109:8667
192.168.1.108(gmond服务的配置):
# cat /usr/local/ganglia/etc/gmond.conf
cluster {
name = "test3" #作为中心节点,要定义自己所在的组,不然gweb那里显示的是默认的unspecified
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel { #定义一个udp单播通道
host = 192.168.1.109 #向中心节点192.168.1.109 发送数据
port = 8667 #发送端口
ttl = 1
}
192.168.1.109(gmond服务的配置):
# vi /etc/ganglia/gmond.conf #你看我109就是rpm包安装的,配置文件路径不一致,所以生产的话就统一编译安装指定路径,安装的东西统一也好维护。
cluster {
name = "test4" #作为中心节点,要定义自己所在的组,不然gweb那里显示的是默认的unspecified
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel { #如果109同时也在一个组播通道中,倒是不用定义这个udp通道。
host = 127.0.0.1 #这里应该是192.168.1.109,为了演示后面的截图效果,这里改为了127.0.0.1。为什么不能定义本地发送,主要是你传输的IP就会反向DNS解析。而你/etc/hosts里面127.0.0.1对应的是localhost
port = 8667
ttl = 1
}
udp_recv_channel { #定义一个接收通道来接收其他节点发送过来的数据
port = 8667
retry_bind = true
}
tcp_accept_channel { #定义一个tcp的接收端口,来接收gmetad来采集数据
port = 8667
gzip_output = no
}
192.168.1.111和192.168.1.112(gmond服务的配置):
cluster {
#name = "unspecified" #我们这里指定自己是哪个组是定义状态,定义自己主要是哪个组,主要是通过IP加端口来判断你这个节点是存在哪个组的,而这种不是中心节点的只需要把数据发送给中心节点就好了。
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel { #再加一个向单播IP发送数据的udp通道,因为udp是不需要像TCP三次握手再发送数据的,是不管你答不答应反正我就是把数据丢给你。
host = 192.168.1.109
port = 8667
ttl = 1
}
#好配置完毕后,重启gmond服务,和重启gmetad服务,查看下面的效果图:

#从上图可以看出test3组已经可以再gweb上面查看了,但是呢192.168.1.108作为中心节点,所显示的图形是本地名称而非IP,是的了,那只能通过在配置文件中添加:override_hostname = "192.168.1.108"来让其按照我们指定的名称来显示了。但是如果组里面存在Centos7的系统又会message日志里面狂刷/usr/local/ganglia/sbin/gmond[1851]: Incorrect format for spoof argument. exiting。组里面都是Centos6系统不存在这个问题。

#从上图中可以看出我们的单播组也出现了,192.168.1.109是红色是为了显示效果将host=192.168.1.109改为了host=127.0.0.1。因为我们host设置的是127.0.0.1所以gweb上面显示的图是localhost。
最后查看一下端口占用情况:
192.168.1.108,192.168.1.110,192.168.1.112的端口占用:
#netstat -lntup|grep gmond
tcp 0 0 0.0.0.0:8666 0.0.0.0:* LISTEN 1860/gmond
udp 0 0 239.2.11.71:8666 0.0.0.0:* 1860/gmond
# netstat -lntup|grep gmond
tcp 0 0 0.0.0.0:8666 0.0.0.0:* LISTEN 1652/gmond
tcp 0 0 0.0.0.0:8667 0.0.0.0:* LISTEN 1652/gmond #定义的接收8667的tcp连接端口
udp 0 0 239.2.11.71:8666 0.0.0.0:* 1652/gmond #刚才为了演示效果,将这个通道注释掉了,只发送不接收,如果通道开启的话,gweb那里也会显示192.168.1.109这张图,因为也从别的节点收数据
udp 0 0 0.0.0.0:8667 0.0.0.0:* 1652/gmond #这是我们定义的8667端口来接收数据
4.2.2 test2组里面的节点搭建
192.168.1.101(gmetad服务配置):
# cat /etc/ganglia/gmetad.conf
data_source "test" 10 192.168.1.106:8668 10 192.168.1.107:8668 #gmetad默认每隔15秒通过tcp连接去该主机下载xml文件,在主机上面加的是自定义的秒数,这里就是10秒钟去采集一次。我这里估计设置成test组,但是等会你可以看下图会发现,下图中显示的是test2,也就是gmond节点里面如果定义了cluster {name}的名称,这里的设置组名称就不好使了也就是会被替换掉。
data_source "test1" 10 192.168.1.103:8666 10 192.168.1.104:8666
192.168.1.101,192.168.1.106,192.168.1.107(gmond配置)
# sed -i 's#8649#8668#g' /etc/ganglia/gmond.conf #将默认的8649端口改为8668,因为我们所有测试机都在同一个内网,所以组播端口不能一样。如果端口要一致,那么通道的IP就要不一致。
cluster {
name = "test2" #都配置上name也是可以的,一般配置文件也都会配置上自己属于哪个cluster组。
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
#重启gmond和gmetad查看效果:

好了下面我们将192.168.1.106的gmond关闭,看看gweb还是否能收到数据?

#除了192.168.1.106,其他的还是可以照旧在gweb上面显示的,这就是双采集节点的作用,gmetad会在不能成功轮训节点1时去轮询节点2.(双活cluster方式)
4.2.3 test1组的各节点的搭建
192.168.1.103,192.168.1.104,192.168.1.105的gmond配置:
# cat /usr/local/ganglia/etc/gmond.conf
cluster {
name = "test1"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel { #将组播改为单播模式,mcast_join 和host只能存在一个
#mcast_join = 239.2.11.71
host = 192.168.1.103
port = 8666
ttl = 1
}
udp_send_channel { #要定义两个通道
host = 192.168.1.104
port = 8666
ttl = 1
}
udp_recv_channel { #将组播的接收通道改为单播的接收通道
#mcast_join = 239.2.11.71
port = 8666
#bind = 239.2.11.71
retry_bind = true
# buffer = 10485760
}
tcp_accept_channel {
port = 8666
gzip_output = no
}
#重启gmond和gmetad服务,查看效果:

好了下面我们将192.168.1.103的gmond关闭,看看gweb还是否能收到数据?

博文来自:www.51niux.com
4.3 gmetad多级层级结果的搭建
子节点上面的设置:
192.168.1.101上面的设置:
# cat /etc/ganglia/gmetad.conf
gridname "101MyGrid" #这里要设置成其他的名称不能用默认的MyGrid,反正就是这些gmetad里面的gridname的名称不能相同。
trusted_hosts 127.0.0.1 192.168.1.102 #让192.168.1.102拥有对8651端口的xml的访问权限
authority "http://192.168.1.101/ganglia/" #这里要改。不然URL产生的是http://localhost.localdomain/ganglia/这种形式。因为点击图的时候就跳转url,点击组跳转url会是:http://localhost.localdomain/ganglia/?t=yes&gw=fwd&gs=unspecified%40http%3A%2F%2Flocalhost.localdomain%2Fganglia%2F这种形式。
192.168.1.110上面的设置:
# cat /etc/ganglia/gmetad.conf
gridname "110MyGrid"
trusted_hosts 127.0.0.1 192.168.1.102
authority "http://192.168.1.110/ganglia/"
父节点上面的设置:
# cat /etc/ganglia/gmetad.conf #添加两个节点的110端口
data_source "101" 192.168.1.101:8651 #“”定义什么无所谓,不过一定要定义上,最好设置的有点意义标志性
data_source "110" 192.168.1.110:8651
三个节点重启gmetad和httpd服务,查看下面的截图效果:



#所以如果gmetad节点太多的话,可以通过这种形式来汇总一下,但是gmetad的httpd服务一定要是存活状态。不然点击对应的gmetad节点是不能跳转的。
如果你想的是从其他gmetad节点,将其内部的节点数据都收集过来进行汇总(这个汇总节点配置要杠杠的):
# vi /etc/ganglia/gmetad.conf
scalable off #将注释去掉重启gmetad服务
下面让我们查看效果:


最后:ganglia和nagios结合会在nagios那里做记录。
ganglia还可有其他一些内容:如用sFlow做代理,ganglia的一些扩展指标的解释,利用NVML模块进行GPU监控等,因为没有用到,就不做记录了。
注:
在集群全部为单播的情况下,在某个机房出现了个问题,出现了hn.kd.ny.adsl图形。大概原因知道,但是为什么出现这种情况就不知道了。这个问题是反向解析的问题。
具体问题:
主机节点,通过抓包发现数据是能正常发送传输的,配置文件没问题,然后抓取数据传输的xml文件发现,出问题的节点到中心节点,中心节点的数据汇聚XML文件里面,<HOST NAME和 IP都是发送数据的IP,但是在gmetad节点上面查看XML文件的话,就变成了<HOST NAME="hn.kd.ny.adsl" IP="192.168.1.208",所以是中心节点反向解析出现了问题,然后汇总数据向gmetad发送的时候当然也就是错的主机名称了。
gmetad向中心节点抓取数据,如果手工查看的话:#telnet 192.168.1.101 8649 #192.168.1.101就是数据的中心汇聚节点,8649就是gmond对外的tcp端口。
中心节点自己查看:#telnet 127.0.0.1 8649|grep hn.kd 发现<HOST NAME="hn.kd.ny.adsl" IP=“192.168.1.209”
用#nslookup IP地址查看,返现出现hn.kd.ny.adsl的都会有反向解析的记录,如下面:
Non-authoritative answer:
208.1.168.192.in-addr.arpa name = hn.kd.ny.adsl.
然后使用不同的dns服务器并且反向解析别的网段:# dig -x IP网关 @8.8.8.8,发现是那个网段的问题。也就是运营商对哪个网段做了相应的设置。
gmond中心节点查看数据节点发送过来的数据,如果手工查看的话:#nc 192.168.1.208 8649 #nc是连接udp的命令。192.168.1.208就是出问题的节点IP,8649就是gmond发送数据的对外udp端口。

只能采取临时的办法,在中心采集节点的/etc/hosts文件里面配置一条:192.168.1.208 192.168.1.208. 让其对此IP的反向解析依然是此IP的IP地址而不是hn.kd.ny.adsl。当然在gmond配置文件里面定义:override_hostname强制覆盖也能解决,但是在Centos7下面这个参数又会造成message狂刷日志(不设置override_hostname能解决狂刷日志的问题)。因为还要和nagios配合,设置了override_hostname就不能再nrpe里面定义localhost了,而要设置成override_hostname定义的名称。不利于批量部署。
注:gmond的端口进程问题(gmond进程僵死问题):
在实际的生产中,gmond有的时候存在这样一种情况,就是进程在,端口在,但是你访问它的端口(比如默认端口8649),能连接但是获取不了数据,正常情况下是一跟gmond的端口建立连接就会获取到数据的,但是当出现僵死情况的时候基本就处于半连接状态,如tcp的话就是最后一次握手建立不了。这时候你执行check_ganglia.py进程也会卡在那里。如果是gmetad设置的中心节点,正常的情况是中心节点挂掉会再次向后备节点发起tcp请求,但是出现这种情况的时候,gmetad的IP:端口的检测形式是可以发请求过去的,所以就不会轮询到备用节点,但是这个僵死的中心节点又不能返回数据,只是让gmetad可以连接过来,这种情况就会造成这台中心节点所负责所有节点的数据都无法发送到gmetad端,也就不能将数据写入到rrd库中。
因为gmond节点这种现象,如果是自己也就是自己发送不了数据,然后在集群上面显示down的情况,如果是这台机器担当了gmond的中心节点,就会造成大面积的数据无法发送,集群一片down的情况。
所以应该对这种现象进行监控,监控也是很简单的,你就让监控程序去连接它的gmond端口,如果获取不到数据,就将gmond节点重启一次,如果问题还是没有解决就报警出来,一般重启会解决,gmond就正常了,具体什么原因造成的不太清楚,随机性。
注:磁盘写性能的问题:
使用SSD硬盘来解决磁盘写性能问题:
#当然这种情况你可以考虑找个有raid卡缓存的机器,利用raid卡的缓存提高读写性能,当然提升也有限不如SSD合算,下面是不做raid的情况。

#你会发现你的磁盘写性能特别差,才写2MB/S的数据磁盘I/O使用率就已经100%了而且还有很多的await。不要惊讶也不要以为磁盘坏掉了,一个15000转的sas盘写100-200MB/S轻轻松啊。
#捋顺一下思路,当然你cacti监控几百台机器也不会出现这个问题,因为一般cacti也就是监控流量嘛,算一下也就几百上千个rrds数据库文件。但是如果用ganglia的话,一个主机可能就要出100张图甚至更多,那么随便来一百台机器就是1W张rrds数据库文件,随着监控机器量级的提升,每分钟要写的rrds数据库文件也会增加,而每个rrds数据库文件都是小文件,这也就是相当于随机写,并非大文件的顺序写,而机械硬盘在随机写方面性能本来就很差,更何况是这么大量的随机写操作,自然你就会发现磁盘的写性能好差啊。所以ganglia如果是机械硬盘又想多监控节点的话,那么监控图就要做优化,只监控必要的性能指标。如果又想多监控节点又想多监控性能指标,可以考虑更换ssd硬盘,下面是ssd硬盘在监控了1000多台机器的随机写情况:
 #从图中可以看出磁盘写方面还有很大的富余(1000多个节点的监控)。
#从图中可以看出磁盘写方面还有很大的富余(1000多个节点的监控)。
使用内存(tmpfs文件系统)来解决小规模集群磁盘写性能问题:
先来捋顺一下思路,sas机械盘顺序写的性能是很不错的在200MB/s左右。那么我们如何将写从随机写改成顺序写呢?就是数据先存到一个地方赞一赞,然后直接一股脑的发给磁盘写入,这就是顺序写入了。
比如,你这个集群比较小,里面也就100多台机器(一个rrds库文件为666KB,如果有一百个指标检测就是666KB*100约等于61MB,如果是100台机器的话整个rrds库目录的大小就是61MB*100约等于6GB,然后__SummaryInfo__目录根目录下面是几百或者几千左右个rrds库文件一个文件大小是1.3MB大概是1个G到几个G,每个小组下面都会有一个此目录大概是几百个rrds库1.3MB大小的文件目录大小大概是几百MB),那么这么大概一算下来,你一个100多台节点监控的rrds库的目录大小可能就要10几G。如果上千台了呢,就是100多G的目录大小,如果用内存来存的话100多G的内存多少钱?但是我一块1000块钱的SSD就搞定了如上图也才使用了一半的性能。所以说这种使用tmpfs文件系统的方式只能是适用于小集群更甚至是特定的场景(比如你ganglia监控服务器是一台虚拟机,而此机器所在的宿主机其他资源已经分配的差不多了但是内存还剩了好多,那就可以多分点内存做个tmpfs文件系统来搞一下)。
下面是操作步骤:

#如我现在给gmetad节点加到了32G内存,这是一台虚拟机。
停掉gmetad进程:
#/etc/init.d/gmetad stop
#/etc/init.d/gmond stop
#service httpd stop
备份旧的rrds文件目录:
#mv /var/lib/ganglia/rrds /var/lib/ganglia/rrds.bak
创建tmpfs文件系统并挂载:
#mkdir /mnt/rrds
#mount -t tmpfs -o size=20G tmpfs /mnt/rrds #创建tmpfs文件系统
#ln -s /mnt/rrds /var/lib/ganglia/rrds #将挂载目录软连接到rrds库文件的存放位置
#chown nobody:nobody /mnt/rrds -R #根据自己gmetad的进程用户来设置目录权限

#从图中查看可以看到已经挂载了一个20G的tmpfs的临时文件,在这个rrds目录里面写就是写到内存里面了哦。
将备份的数据写入到内存中(如果以前的内容不要了就没必要执行此步):
#rsync -av /var/lib/ganglia/rrds.bak/* /mnt/rrds/ #这一步是将之前备份的数据写入到内存中,下图可以看到磁盘读写情况。

#这里是用iostat查看的状态信息,现在正在把之前备份的数据从目录里面往内存里面写入,可见每秒从硬盘读取100MB/S写入到内存中。

#再次执行,就会提示已经都同步完了,不会再往内存里面写内容了。

#可以看到内存(tmpfs)已经使用了13G,还剩7G左右的可用内存。
启动相关服务:
#chown -R nobody:nobody /mnt/rrds
#/etc/init.d/gmetad restart
#/etc/init.d/gmond start
#service httpd start
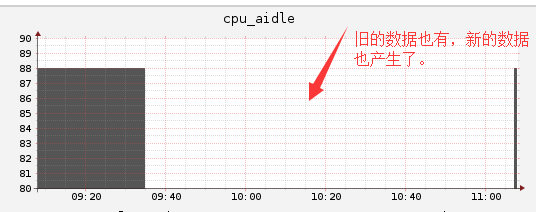
#从图上可以看到旧的数据也保留下来了,新的数据也产生了,当然中间断层这么大是因为我中间干了点别的事情,正常的操作的话中间也就1两分钟的断层。
后续部分:
tmpfs文件系统的开机挂载就不用说了,这个肯定是要做的。
然后就是因为数据都存在了内存中,那么机器如果意外重启就会导致内存中的数据全部丢失,显然要做个多长时间将内存里面的数据刷新到磁盘中的操作。
#time rsync -av /var/lib/ganglia/rrds/ /home/ganglia.bak/`date +%F-%H-%M` #如我先判断一下13G的数据从内存写到磁盘中需要多长时间,最终的目录一定要是时间格式啊,这样你可以知道你这份数据是几点几分的数据当然进入目录里面看下rrds库文件的时间也是可以判断。
![FR$F6CX}}9S]ROH%9N$0OZ6.png](http://www.51niux.com/zb_users/upload/2017/09/201709011504235820898898.png)
#这是宿主机所在磁盘的写入情况,可见在180MB/S左右的写。因为是批量写入嘛,就变成顺序写了,顺序写当然是很快的。(如果还是原来随机写的情况下宿主机也就7MB/s就已经100%了)
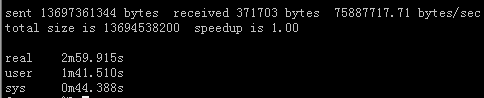
#最终结果是用了将近3分钟。
#好了那么下面就是做定时任务了,看你对数据的监控数据的重视程度了,可以10分钟来一波也可以1小时来一波或者1天来一波,反正同步到硬盘就是几分钟的事情,写性能也已经发挥到最大了。
#然后开机启动就是,先不启动gmetad服务,先挂载tmpfs文件系统,然后将最新的一份数据从指定的备份目录里面导入一份进入挂载文件系统也就是内存中,然后再启动gmetad服务和httpd服务。
#这种方式真的很烧钱,16G内存现在的价格是在1000多元(只能应付100台节点的监控,当然读写没延迟都写内存了!),32G的内存是3000多,一个SSD的200多G价格在1000-3000元之间(就可以监控千台节点写入web读取都没问题)。只能说这种方式是在特定的场景下。如果规模再大,单盘SSD都不行了的话,可以考虑集群拆分不要都汇聚到一个节点了,然后前面讲过的可以通过一个主入口来实现节点的跳转,当然不想拆分集群,就想让所有的节点最终都汇入到一个总节点的话,存储这里就要采集分布式的思路来分散读写了。
#当然如果还是小集群的话,可以将采集时间调大一点比如5分钟收集一波数据写到rrds库文件,或者直接使用Centos7系统吧,在写性能方面也会看到有很大的提升,随机写基本能跑到7MB/S,但是有一点就是如果util跑到了100%,这时候你的操作就巨卡几乎快啥也不能干了,就是读方面快为0了,这时候你再用web来查看ganglia的数据也就卡爆了,所以系统更换只是有小的提升,性能最终还是要落在硬件和架构层面的。
注:gmond的netstat的CPU占用过高问题:
gmond调用了py脚本来采集tcp的连接状态,当连接数上万的时候会发现用netstat会非常卡占用cpu非常高,这跟netstat的机制有关系的,而gmond的py插件又默认使用的是netstat的方法来采集tcp连接数状态,如下图:

#当服务器连接非常多时,用netstat几乎要占用一核cpu的百分百性能。
#解决方法也很简单:
进入ganglia/lib64/ganglia/python_modules目录下:
#vim tcpconn.py
#下面是要修改的内容
self.popenChild = subprocess.Popen(["netstat", '-t', '-a', '-n'], stdout=subprocess.PIPE)
self.popenChild = popen2.Popen3("netstat -t -a -n")
if line[tcp_state_at] == 'ESTABLISHED':#下面是修改后的内容
self.popenChild = subprocess.Popen(["ss", '-t', '-a', '-n'], stdout=subprocess.PIPE)
self.popenChild = popen2.Popen3("ss -t -a -n")
if line[tcp_state_at] == 'ESTAB':#就改三行就完事了,就是将netstat命令换成了ss命令,然后重启gmond命令就OK了,你会发现问题解决了。当然这东西就是懂自然改起来就轻松。
