Prometheus自动发现和kube-state-metrics指标记录(六)
一、官方配置(可直接忽略)
1.1 配置文件总览
Configuration file:
Prometheus通过命令行标志和配置文件进行配置。尽管命令行标志配置了不可变的系统参数(例如存储位置,要保留在磁盘和内存中的数据量等),但配置文件定义了与抓取作业及其实例相关的所有内容,以及哪些规则文件装载。要查看所有可用的命令行标志,请运行./prometheus -h。Prometheus可以在运行时重新加载其配置。 如果新配置格式不正确,则更改将不会应用。 通过向Prometheus进程发送SIGHUP或向/-/ reload端点发送HTTP POST请求(启用--web.enable-lifecycle标志时)来触发配置重载。 这还将重新加载所有已配置的规则文件。
要指定要加载的配置文件,请使用--config.file标志。该文件以YAML格式写入,由以下描述的方案定义。 方括号表示参数是可选的。 对于非列表参数,该值设置为指定的默认值。通用占位符定义如下:
<boolean>: 布尔值,可以采用true或false值 <duration>: 与正则表达式[0-9]+(ms|[smhdwy])匹配的持续时间 <labelname>: 与正则表达式[a-zA-Z_][a-zA-Z0-9_]*匹配的字符串 <labelvalue>: 一串unicode字符 <filename>: 当前工作目录中的有效路径 <host>: 由主机名或IP后跟可选端口号组成的有效字符串 <path>: 有效的URL路径 <scheme>: 一个字符串,可以使用值http或https <string>: 常规字符串 <secret>: 包含密码的常规字符串,例如密码 <tmpl_string>: 使用前已模板扩展的字符串
其他占位符分别指定。在这里可以找到有效的示例文件:https://github.com/prometheus/prometheus/blob/release-2.13/config/testdata/conf.good.yml
全局配置指定在所有其他配置上下文中有效的参数。 它们还用作其他配置部分的默认设置。
global: #默认情况下收集目标的频率。 [ scrape_interval: <duration> | default = 1m ] #收集数据请求超时之前的时间。 [ scrape_timeout: <duration> | default = 10s ] #评估规则的频率。 [ evaluation_interval: <duration> | default = 1m ] #与外部系统(federation, remote storage, Alertmanage)通信时添加到任何时间序列或警报的标签。 external_labels: [ <labelname>: <labelvalue> ... ] #规则文件指定了清单列表。 从所有匹配的文件中读取规则和警报 rule_files: [ - <filepath_glob> ... ] #scrape配置列表。 scrape_configs: [ - <scrape_config> ... ] #警报指定与Alertmanager相关的设置。 alerting: alert_relabel_configs: [ - <relabel_config> ... ] alertmanagers: [ - <alertmanager_config> ... ] #与远程写入功能相关的设置。 remote_write: [ - <remote_write> ... ] #与远程读取功能相关的设置。 remote_read: [ - <remote_read> ... ]
<scrape_config>
scrape_config部分指定了一组目标和参数,这些目标和参数描述了如何scrape它们。 在一般情况下,一个scrape配置指定一个作业。 在高级配置中,这可能会改变。可以通过static_configs参数静态配置目标,也可以使用受支持的服务发现机制之一动态发现目标。此外,relabel_configs允许在抓取之前对任何目标及其标签进行高级修改。其中,<job_name>在所有scrape配置中必须唯一。
#默认情况下,作业名称分配给抓取的指标。 job_name: <job_name> #从这项工作中scrape目标的频率。 [ scrape_interval: <duration> | default = <global_config.scrape_interval> ] #抓取此作业时的每次抓取超时。 [ scrape_timeout: <duration> | default = <global_config.scrape_timeout> ] #从目标获取指标的HTTP资源路径。 [ metrics_path: <path> | default = /metrics ] #honor_labels控制Prometheus如何处理已存在于抓取数据中的标签与Prometheus将在服务器端附加的标签(“作业”和“实例”标签,手动配置的目标标签以及由服务发现实现生成的标签)之间的冲突。 #如果将honor_labels设置为“true”,则通过保留已抓取数据中的标签值并忽略冲突的服务器端标签来解决标签冲突。 #如果将honor_labels设置为“false”,则通过将已抓取数据中的冲突标签重命名为“exported_ <original-label>”(例如“exported_instance”,“exported_job”),然后附加服务器端标签来解决标签冲突。 #将honor_labels设置为“true”对于诸如联合和刮除Pushgateway的用例很有用,在这种情况下应保留目标中指定的所有标签。 #请注意,此设置不会影响任何全局配置的“external_labels”。在与外部系统通信时,仅在时间序列尚无给定标签时才始终应用它们,否则将忽略它们。 [ honor_labels: <boolean> | default = false ] #Honor_timestamps控制Prometheus是否尊重抓取数据中的时间戳。 #如果将honor_timestamps设置为“true”,则将使用目标公开的指标的时间戳。 #如果将honor_timestamps设置为“ false”,则目标忽略的度量标准的时间戳将被忽略。 [ honor_timestamps: <boolean> | default = true ] #配置用于请求的网络协议方案。 [ scheme: <scheme> | default = http ] #可选的HTTP URL参数。 params: [ <string>: [<string>, ...] ] #使用配置的用户名和密码,在每个抓取请求上设置“ Authorization”标头。password和password_file是互斥的。 basic_auth: [ username: <string> ] [ password: <secret> ] [ password_file: <string> ] #使用配置的载体令牌在每个抓取请求上设置“Authorization”标头。 它与`bearer_token_file`互斥。 [ bearer_token: <secret> ] #使用从配置文件中读取的承载令牌,在每个抓取请求上设置“Authorization”标头。 它与`bearer_token`互斥。 [ bearer_token_file: /path/to/bearer/token/file ] #配置抓取请求的TLS设置。 tls_config: [ <tls_config> ] #可选的代理URL。 [ proxy_url: <string> ] #Azure服务发现配置列表。 azure_sd_configs: [ - <azure_sd_config> ... ] #Consul服务发现配置列表。 consul_sd_configs: [ - <consul_sd_config> ... ] #DNS服务发现配置列表。 dns_sd_configs: [ - <dns_sd_config> ... ] #EC2服务发现配置列表。 ec2_sd_configs: [ - <ec2_sd_config> ... ] #OpenStack服务发现配置列表。 openstack_sd_configs: [ - <openstack_sd_config> ... ] #文件服务发现配置列表。 file_sd_configs: [ - <file_sd_config> ... ] #GCE服务发现配置列表。 gce_sd_configs: [ - <gce_sd_config> ... ] #Kubernetes服务发现配置列表。 kubernetes_sd_configs: [ - <kubernetes_sd_config> ... ] #Marathon服务发现配置列表。 marathon_sd_configs: [ - <marathon_sd_config> ... ] #AirBnB的Nerve服务发现配置列表。 nerve_sd_configs: [ - <nerve_sd_config> ... ] #Zookeeper Serverset服务发现配置列表。 serverset_sd_configs: [ - <serverset_sd_config> ... ] #Triton服务发现配置列表。 triton_sd_configs: [ - <triton_sd_config> ... ] #此作业的带标签的静态配置目标列表。 static_configs: [ - <static_config> ... ] #目标重新标记配置的列表。 relabel_configs: [ - <relabel_config> ... ] #metric重新标记配置列表。 metric_relabel_configs: [ - <relabel_config> ... ] #每次scrape将接受的scraped样本数限制。 #如果在公制重新标记后存在的样本数量超过此数量,则整个刮擦将被视为不合格。 0表示没有限制。 [ sample_limit: <int> | default = 0 ]
<tls_config>
tls_config允许配置TLS连接。
#用于验证API服务器证书的CA证书。 [ ca_file: <filename> ] #用于服务器的客户端证书身份验证的证书和密钥文件。 [ cert_file: <filename> ] [ key_file: <filename> ] #ServerName扩展名,指示服务器的名称。 https://tools.ietf.org/html/rfc4366#section-3.1 [ server_name: <string> ] #禁用服务器证书的验证。 [ insecure_skip_verify: <boolean> ]
1.2 自动发现规则细分
<azure_sd_config>
Azure SD配置允许从Azure VM检索抓取目标。重新标记期间,以下meta标签可用于目标:
__meta_azure_machine_id: 机器ID __meta_azure_machine_location: 机器运行的位置 __meta_azure_machine_name: 机器名称 __meta_azure_machine_os_type: 机器操作系统 __meta_azure_machine_private_ip: 机器的专用IP __meta_azure_machine_public_ip: 机器的公共IP(如果存在) __meta_azure_machine_resource_group: 机器的资源组 __meta_azure_machine_tag_<tagname>: 机器的每个标签值 __meta_azure_machine_scale_set: vm所属的比例尺集的名称(仅当使用比例尺集时才设置此值) __meta_azure_subscription_id: 订阅ID __meta_azure_tenant_id: 租户ID
请参阅以下有关Azure发现的配置选项:
#访问Azure API的信息。Azure环境。 [ environment: <string> | default = AzurePublicCloud ] #身份验证方法,即OAuth或ManagedIdentity。See https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview [ authentication_method: <string> | default = OAuth] # 订阅ID。 始终需要。 subscription_id: <string> #可选的租户ID。 仅在authentication_method OAuth中需要。 [ tenant_id: <string> ] #可选的客户端ID。 仅在authentication_method OAuth中需要。 [ client_id: <string> ] #可选的客户secret。 仅在authentication_method OAuth中需要。 [ client_secret: <secret> ] #刷新间隔以重新读取实例列表。 [ refresh_interval: <duration> | default = 300s ] #从中收集指标的端口。 如果使用公共IP地址,则必须在重新标记规则中指定该地址。 [ port: <int> | default = 80 ]
<consul_sd_config>
Consul SD配置允许从Consul的Catalog API检索抓取目标。重新标记期间,以下meta标签可用于目标:
__meta_consul_address: 目标地址 __meta_consul_dc: 目标的数据中心名称 __meta_consul_tagged_address_<key>: 每个节点标记了目标的地址键值 __meta_consul_metadata_<key>: 目标的每个节点元数据键值 __meta_consul_node: 为目标定义的节点名称 __meta_consul_service_address: 目标的服务地址 __meta_consul_service_id: 目标的服务ID __meta_consul_service_metadata_<key>: 目标的每个服务元数据键值 __meta_consul_service_port: 目标的服务端口 __meta_consul_service: 目标所属服务的名称 __meta_consul_tags: 由标签分隔符连接的目标的标签列表
下面是示例:
#访问Consul API的信息。 将根据Consul文档要求进行定义。 [ server: <host> | default = "localhost:8500" ] [ token: <secret> ] [ datacenter: <string> ] [ scheme: <string> | default = "http" ] [ username: <string> ] [ password: <secret> ] tls_config: [ <tls_config> ] #为其检索目标的服务列表。 如果省略,则将scraped所有服务。 services: [ - <string> ] #See https://www.consul.io/api/catalog.html#list-nodes-for-service 去知道有关可以使用的可能过滤器的更多信息。 #标签的可选列表,用于过滤给定服务的节点。 服务必须包含列表中的所有标签。 tags: [ - <string> ] #节点元数据,用于过滤给定服务的节点。 [ node_meta: [ <name>: <value> ... ] ] #Consul标签通过其连接到标签标签中的字符串。 [ tag_separator: <string> | default = , ] #允许过期Consul results (see https://www.consul.io/api/features/consistency.html). 将减少Consul的负担。 [ allow_stale: <bool> ] #刷新提供的名称之后的时间。在大型设置中,增加此值可能是个好主意,因为目录将一直更改。 [ refresh_interval: <duration> | default = 30s ]
请注意,用于抓取目标的IP地址和端口被组装为<__ meta_consul_address>:<__ meta_consul_service_port>。 但是,在某些Consul设置中,相关地址在__meta_consul_service_address中。 在这种情况下,你可以使用重新标记功能来替换特殊的__address__标签。
重新标记阶段是基于任意标签为服务筛选服务或节点的首选且功能更强大的方法。 对于拥有数千项服务的用户,直接使用Consul API可能会更高效,该API具有基本的过滤节点支持(当前通过节点元数据和单个标签)。
<dns_sd_config>
基于DNS的服务发现配置允许指定一组DNS域名,这些域名会定期查询以发现目标列表。 从/etc/resolv.conf中读取要联系的DNS服务器。此服务发现方法仅支持基本DNS A,AAAA和SRV记录查询,但不支持RFC6763中指定的高级DNS-SD方法。在重新标记阶段,元标记__meta_dns_name在每个目标上均可用,并设置为产生发现的目标的记录名称。
#要查询的DNS域名列表。 names: [ - <domain_name> ] #要执行的DNS查询的类型。 [ type: <query_type> | default = 'SRV' ] #如果查询类型不是SRV,则使用的端口号。 [ port: <number>] #提供的名称之后的刷新时间。 [ refresh_interval: <duration> | default = 30s ]
其中<domain_name>是有效的DNS域名。 其中<query_type>是SRV,A或AAAA。
<ec2_sd_config>
EC2 SD配置允许从AWS EC2实例检索抓取目标。 默认情况下使用私有IP地址,但可以通过重新标记将其更改为公共IP地址。重新标记期间,以下meta标签可用于目标:
__meta_ec2_availability_zone: 实例在其中运行的可用区 __meta_ec2_instance_id: EC2实例ID __meta_ec2_instance_state: EC2实例的状态 __meta_ec2_instance_type: EC2实例的类型 __meta_ec2_owner_id: 拥有EC2实例的AWS账户的ID __meta_ec2_platform: 操作系统平台,在Windows服务器上设置为“ windows”,否则不存在 __meta_ec2_primary_subnet_id: 主网络接口的子网ID(如果有) __meta_ec2_private_dns_name: 实例的私有DNS名称(如果有) __meta_ec2_private_ip: 实例的私有IP地址(如果存在) __meta_ec2_public_dns_name: 实例的公共DNS名称(如果有) __meta_ec2_public_ip: 实例的公共IP地址(如果有) __meta_ec2_subnet_id: 实例在其中运行的子网ID的逗号分隔列表(如果有) __meta_ec2_tag_<tagkey>: 实例的每个标签值 __meta_ec2_vpc_id: 运行实例的VPC的ID(如果有)
请参阅以下有关EC2发现的配置选项:
#访问EC2 API的信息。 #AWS区域。如果为空,则使用实例元数据中的区域。 [ region: <string> ] #Custom endpoint to be used. [ endpoint: <string> ] #AWS API密钥。 如果为空,则使用环境变量“ AWS_ACCESS_KEY_ID”和“ AWS_SECRET_ACCESS_KEY”。 [ access_key: <string> ] [ secret_key: <secret> ] #用于连接到API的命名AWS配置文件。 [ profile: <string> ] #AWS Role ARN,是使用AWS API密钥的替代方法。 AWS Role ARN,是使用AWS API密钥的替代方法。 [ role_arn: <string> ] #刷新间隔以重新读取实例列表。 [ refresh_interval: <duration> | default = 60s ] #从中scrape指标的端口。 如果使用公共IP地址,则必须在重新标记规则中指定该地址。 [ port: <int> | default = 80 ] #筛选器可用于根据其他条件筛选实例列表。 可在此处找到可用的过滤条件:https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_DescribeInstances.html #筛选器API文档: https://docs.aws.amazon.com/AWSEC2/latest/APIReference/API_Filter.html filters: [ - name: <string> values: <string>, [...] ]
重新标记阶段是基于任意标签过滤目标的首选且功能更强大的方法。 对于具有数千个实例的用户,直接使用支持过滤实例的EC2 API可能会更有效。
<openstack_sd_config>
OpenStack SD配置允许从OpenStack Nova实例检索抓取目标。可以配置以下<openstack_role>类型之一来发现目标:
hypervisor:系统管理程序角色为每个Nova系统管理程序节点发现一个目标。 目标地址默认为虚拟机管理程序的host_ip属性。重新标记期间,以下meta标签可用于目标:
__meta_openstack_hypervisor_host_ip: 系统管理程序节点的IP地址。 __meta_openstack_hypervisor_name: 系统管理程序节点的名称。 __meta_openstack_hypervisor_state: 系统管理程序节点的状态。 __meta_openstack_hypervisor_status: 系统管理程序节点的状态。 __meta_openstack_hypervisor_type: 系统管理程序节点的类型。
instance:实例角色为Nova实例的每个网络接口发现一个目标。 目标地址默认为网络接口的专用IP地址。重新标记期间,以下meta标签可用于目标:
__meta_openstack_address_pool: 专用IP的池。 __meta_openstack_instance_flavor: OpenStack实例的风格。 __meta_openstack_instance_id: OpenStack实例ID。 __meta_openstack_instance_name: OpenStack实例ID。 __meta_openstack_instance_status: OpenStack实例的状态。 __meta_openstack_private_ip: OpenStack实例的私有IP。 __meta_openstack_project_id: 拥有此实例的项目(租户)。 __meta_openstack_public_ip: OpenStack实例的公共IP。 __meta_openstack_tag_<tagkey>: 实例的每个标记值。 __meta_openstack_user_id: 拥有租户的用户帐户。
请参阅以下有关OpenStack发现的配置选项:
#访问OpenStack API的信息。 #应该发现的实体的OpenStack角色。 role: <openstack_role> #The OpenStack Region. region: <string> #identity_endpoint指定使用适当版本的Identity API所需的HTTP端点。 尽管所有身份服务最终都需要它,但通常会由提供程序级别的功能来填充它。 [ identity_endpoint: <string> ] #如果使用Identity V2 API,则需要用户名.请咨询提供商的控制面板,以发现你帐户的用户名。 在Identity V3中,需要userid或username和domain_id或domain_name的组合。 [ username: <string> ] [ userid: <string> ] #Identity V2和V3 API的密码。 请咨询提供商的控制面板,以发现您帐户的首选身份验证方法。 [ password: <secret> ] #如果在Identity V3中使用用户名,则最多只能提供domain_id和domain_name之一。 否则,两者都是可选的。 [ domain_name: <string> ] [ domain_id: <string> ] #对于Identity V2 API,project_id和project_name字段是可选的。某些提供程序允许您指定project_name而不是project_id。有些同时需要。 供应商的身份验证策略将确定这些字段如何影响身份验证。 [ project_name: <string> ] [ project_id: <string> ] #如果使用应用程序凭据进行身份验证,则必须提供application_credential_id或application_credential_name字段。某些提供程序允许你创建用于身份验证的应用程序凭据,而不是密码。 [ application_credential_name: <string> ] [ application_credential_id: <string> ] #如果使用应用程序凭据进行身份验证,则application_credential_secret字段为必填字段。 [ application_credential_secret: <secret> ] #服务发现是否应列出所有项目的所有实例。 它仅与“instance”角色相关,通常需要管理员权限。 [ all_tenants: <boolean> | default: false ] #刷新间隔以重新读取实例列表。 [ refresh_interval: <duration> | default = 60s ] #从中scrape指标的端口。 如果使用公共IP地址,则必须在重新标记规则中指定该地址。 [ port: <int> | default = 80 ] #TLS配置。 tls_config: [ <tls_config> ]
<file_sd_config>
基于文件的服务发现提供了一种配置静态目标的更通用的方法,并用作插入自定义服务发现机制的接口。它读取一组包含零个或多个<static_config>的列表的文件。 对所有已定义文件的更改将通过磁盘监视来检测并立即应用。 文件可以以YAML或JSON格式提供。 仅应用导致形成良好目标组的更改。JSON文件必须包含使用以下格式的静态配置列表:
[
{
"targets": [ "<host>", ... ],
"labels": {
"<labelname>": "<labelvalue>", ...
}
},
...
]作为备用,文件内容也将以指定的刷新间隔定期重新读取。在重新标记阶段,每个目标都有一个元标记__meta_filepath。 它的值设置为从中提取目标的文件路径。有与此发现机制集成的列表。
#从中提取目标组的文件的模式。 files: [ - <filename_pattern> ... ] #刷新间隔以重新读取文件。 [ refresh_interval: <duration> | default = 5m ]
其中<filename_pattern>可能是以.json,.yml或.yaml结尾的路径。 最后的路径段可能包含与任何字符序列匹配的单个*,例如 my/path/tg_*.json。
<gce_sd_config>
GCE SD配置允许从GCP GCE实例中检索抓取目标。 默认情况下使用私有IP地址,但可以通过重新标记将其更改为公共IP地址。重新标记期间,以下meta标签可用于目标:
__meta_gce_instance_id: 实例的数字ID __meta_gce_instance_name: 实例的名称 __meta_gce_label_<name>: 实例的每个GCE标签 __meta_gce_machine_type: 实例机器类型的完整或部分URL __meta_gce_metadata_<name>: 实例的每个元数据项 __meta_gce_network: 实例的网络URL __meta_gce_private_ip: 实例的私有IP地址 __meta_gce_project: 实例在其中运行的GCP项目 __meta_gce_public_ip: 实例的公共IP地址(如果存在) __meta_gce_subnetwork: 实例的子网URL __meta_gce_tags: 以逗号分隔的实例标签列表 __meta_gce_zone: 实例在其中运行的GCE区域URL
请参阅以下有关GCE发现的配置选项:
#访问GCE API的信息。 #The GCP Project project: <string> #scrape目标区域。 如果需要多个区域,请使用多个gce_sd_configs。 zone: <string> #可以选择使用Filter通过其他条件来过滤实例列表,此过滤字符串的语法在过滤查询参数部分中进行了描述:https://cloud.google.com/compute/docs/reference/latest/instances/list [ filter: <string> ] #刷新间隔以重新读取实例列表 [ refresh_interval: <duration> | default = 60s ] #从中scrape指标的端口。如果使用公共IP地址,则必须在重新标记规则中指定该地址。 [ port: <int> | default = 80 ] #标签分隔符用于在串联时分隔标签 [ tag_separator: <string> | default = , ]
Google Cloud SDK默认客户端通过在以下位置查找(首选找到的第一个位置)来发现凭据:
GOOGLE_APPLICATION_CREDENTIALS环境变量指定的JSON文件 众所周知的路径$HOME/.config/gcloud/application_default_credentials.json中的JSON文件 从GCE元数据服务器获取
如果Prometheus在GCE中运行,则与其运行实例相关联的服务帐户应至少具有对计算资源的只读权限。 如果在GCE之外运行,请确保创建适当的服务帐户,并将凭据文件放在预期的位置之一。
<marathon_sd_config>
Marathon SD配置允许使用Marathon REST API检索刮擦目标。 Prometheus将定期检查REST端点是否有当前正在运行的任务,并为每个至少具有一个正常任务的应用程序创建目标组。重新标记期间,以下meta标签可用于目标:
__meta_marathon_app: 应用程序的名称(斜杠由破折号代替) __meta_marathon_image: 使用的Docker映像的名称(如果可用) __meta_marathon_task: Mesos任务的ID __meta_marathon_app_label_<labelname>: 附加到应用程序的所有Marathon标签 __meta_marathon_port_definition_label_<labelname>: 端口定义标签 __meta_marathon_port_mapping_label_<labelname>: 端口映射标签 __meta_marathon_port_index: 端口索引号(例如PORT1为1)
请参阅以下有关Marathon发现的配置选项:
#用于联系Marathon服务器的URL列表。需要至少提供一个服务器URL。 servers: - <string># Polling interval [ refresh_interval: <duration> | default = 30s ] #基于令牌的身份验证的可选身份验证信息https://docs.mesosphere.com/1.11/security/ent/iam-api/#passing-an-authentication-token #它与auth_token_file和其他身份验证机制互斥。 [ auth_token: <secret> ] #基于令牌的身份验证的可选身份验证信息https://docs.mesosphere.com/1.11/security/ent/iam-api/#passing-an-authentication-token #它与auth_token和其他身份验证机制互斥。 [ auth_token_file: <filename> ] #使用配置的用户名和密码在每个请求上设置``Authorization''标头,这与其他身份验证机制互斥.password和password_file是互斥的。 basic_auth: [ username: <string> ] [ password: <string> ] [ password_file: <string> ] #使用配置的载体令牌在每个请求上设置“Authorization”标头。它与`bearer_token_file`和其他身份验证机制互斥。注意:当前版本的DC/OS marathon(v1.11.0)不支持标准的Bearer令牌身份验证。 使用`auth_token`代替。 [ bearer_token: <string> ] #使用从配置文件中读取的承载令牌,对每个请求设置“ Authorization”标头。 它与`bearer_token`和其他身份验证机制互斥。注意:当前版本的DC/OS marathon(v1.11.0)不支持标准的Bearer令牌身份验证。 请改用auth_token_file。 [ bearer_token_file: /path/to/bearer/token/file ] #用于连接到marathon服务器的TLS配置 tls_config: [ <tls_config> ] #可选的代理URL。 [ proxy_url: <string> ]
默认情况下,Prometheus将scraped Marathon中列出的每个应用。 如果并非所有服务都提供Prometheus指标,则可以使用Marathon标签和Prometheus重新标签来控制实际上将被scraped的实例。 有关如何设置Marathon应用程序和Prometheus配置的实际示例,请参阅Prometheus marathon-sd配置文件。默认情况下,所有应用程序都将在Prometheus(配置文件中指定的一项)中显示为单个作业,也可以使用重新标记进行更改。
<nerve_sd_config>
Nerve SD配置允许从AirBnB的Nerve中检索scrape目标,这些scrape目标存储在Zookeeper中。重新标记期间,以下meta标签可用于目标:
__meta_nerve_path: Zookeeper中端点节点的完整路径 __meta_nerve_endpoint_host: 端点的主机 __meta_nerve_endpoint_port: 端点的端口 __meta_nerve_endpoint_name: 端点名称
配置如下:
#Zookeeper服务器。 servers: - <host> #路径可以指向单个服务,也可以指向服务树的根。 paths: - <string>[ timeout: <duration> | default = 10s ]
<serverset_sd_config>
Serverset SD配置允许从存储在Zookeeper中的Serverset检索抓取目标。 服务器集通常由Finagle和Aurora使用。重新标记期间,以下meta标签可用于目标:
__meta_serverset_path: Zookeeper中服务器集成员节点的完整路径 __meta_serverset_endpoint_host: 默认端点的主机 __meta_serverset_endpoint_port: 默认端点的端口 __meta_serverset_endpoint_host_<endpoint>: 给定端点的主机 __meta_serverset_endpoint_port_<endpoint>: 给定端点的端口 __meta_serverset_shard: 成员的分片号 __meta_serverset_status: 成员的状态
配置如下:
#Zookeeper服务器。 servers: - <host> #路径可以指向单个服务器集,也可以指向服务器集树的根。 paths: - <string>[ timeout: <duration> | default = 10s ]
Serverset数据必须为JSON格式,当前不支持Thrift格式。
<triton_sd_config>
#请参照官网
博文来自:www.51niux.com
二、基于文件的自动发现
static_configs: 静态服务发现。文件的自动发现配置是:file_sd_configs区域的配置,文件可以是YAML和JSON两种格式。
2.1 通过文件自动发现多node_export
先通过JSON方式来一波:
加载一个文件:
# vim prometheus.yml
- job_name: k8s_node file_sd_configs: - files: - /opt/prometheus/file_sd/k8s_node.json refresh_interval: 10s
#files下面指定文件的位置,当然也可以用- /opt/prometheus/file_sd/*.json代替匹配目录下的多个文件哈,refresh_interval表示prometheus每隔多久检测一下这些配置文件加载新的配置,当然第一次添加文件位置的时候需要重新加载prometheus,如果只是修改已经加载的json文件的话不需要重新加载prometheus,prometheus定时刷新有新的变化会重新加载。
# vim /opt/prometheus/file_sd/k8s_node.json
[
{
"targets": ["192.168.1.135:9100","192.168.1.136:9100"]
}
]
# curl -XPOST http://localhost:9090/-/reload
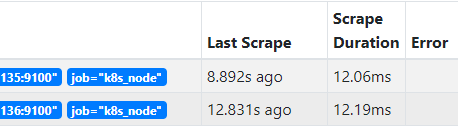
#从界面可以看到两台机器已经加载到监控里面来了哈。
target资源如果变化大的话可以把间隔时间调小点,如果比较稳定的话可以把间隔时间调大点比如60m。
#用下面promql语句可以查看上次更改时间:
prometheus_sd_file_mtime_seconds
加载多个文件:
# vim prometheus.yml
- job_name: k8s_node file_sd_configs: - files: - /opt/prometheus/file_sd/k8s_node.json - /opt/prometheus/file_sd/k8s_master.json refresh_interval: 10s
# vim /opt/prometheus/file_sd/k8s_master.json
[
{
"targets": ["192.168.1.137:9100"]
}
]
# curl -XPOST http://localhost:9090/-/reload
然后再通过yaml文件来一波:
# vim prometheus.yml
- job_name: k8s_node file_sd_configs: - files: - /opt/prometheus/file_sd/k8s*.yml refresh_interval: 10s
# curl -XPOST http://localhost:9090/-/reload
# vim /opt/prometheus/file_sd/k8s_node.yml
- targets: ["192.168.1.136:9100","192.168.1.137:9100"] labels: __env__: "prod" node_type: "node" - targets: ["192.168.1.157:9100"] labels: __env__: "env" node_type: "logstash"
#上面我们可以针对不同的targets标签,这样我们就知道这个采集的类型,然后还记得把__开头的标签是不会写到metrics数据的,但是node_type确实可以写到metrics中的。
# vim /opt/prometheus/file_sd/k8s_master.yml
- targets: - "192.168.1.135:9100" labels: __env__: "prod" node_type: "master"
#这是targets的另外一种写法,这样我们就可以通过node_type来区分k8s的master节点和node节点的数据了。
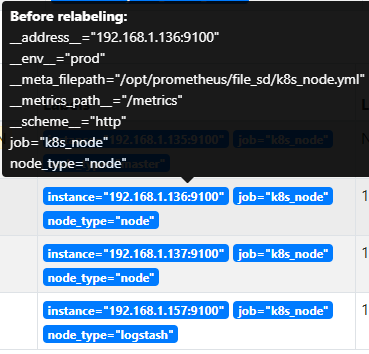
#可以看到每个targets类型的列表都打了不同的标签。如:node_cpu_seconds_total{node_type="master"} 我们就可以针对不同的标签做不同的数据采样和监控报警了。
博文来自:www.51niux.com
三、kube-state-metrics理论基础
3.1 kube-state-metrics
概述:
已经有了cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
我调度了多少个replicas?现在可用的有几个? 多少个Pod是running/stopped/terminated状态? Pod重启了多少次? 我有多少job在运行中
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。
指标分类:
指标类别包括:
CronJob Metrics DaemonSet Metrics Deployment Metrics Job Metrics LimitRange Metrics Node Metrics PersistentVolume Metrics PersistentVolumeClaim Metrics Pod Metrics Pod Disruption Budget Metrics ReplicaSet Metrics ReplicationController Metrics ResourceQuota Metrics Service Metrics StatefulSet Metrics Namespace Metrics Horizontal Pod Autoscaler Metrics Endpoint Metrics Secret Metrics ConfigMap Metrics
以pod为例:
kube_pod_info kube_pod_owner kube_pod_status_phase kube_pod_status_ready kube_pod_status_scheduled kube_pod_container_status_waiting kube_pod_container_status_terminated_reason …
对于pod的资源限制,一般情况下:200MiB memory 0.1 cores
超过100节点的集群:2MiB memory per node 0.001 cores per node
请注意,如果将CPU限制设置得太低,则将无法足够快地处理kube-state-metrics的内部队列,从而随着队列长度的增加而导致内存消耗增加。 如果遇到内存分配过多导致的问题,请尝试增加CPU限制。
因为kube-state-metrics-service.yaml中有prometheus.io/scrape: 'true'标识,因此会将metric暴露给prometheus,而Prometheus会在kubernetes-service-endpoints这个job下自动发现kube-state-metrics,并开始拉取metrics,无需其他配置。
使用kube-state-metrics后的常用场景有:
存在执行失败的Job: kube_job_status_failed{job=“kubernetes-service-endpoints”,k8s_app=“kube-state-metrics”}==1
集群节点状态错误: kube_node_status_condition{condition=“Ready”,status!=“true”}==1
集群中存在启动失败的Pod:kube_pod_status_phase{phase=~“Failed|Unknown”}==1
最近30分钟内有Pod容器重启: changes(kube_pod_container_status_restarts[30m])>0kube-state-metrics本质上是不断轮询api-server。度量标准在侦听端口的HTTP endpoint /metrics上导出(默认为8080)。
与metric-server的对比:
1. metric-server(或heapster)是从api-server中获取cpu、内存使用率这种监控指标,并把他们发送给存储后端,如influxdb或云厂商,他当前的核心作用是:为HPA等组件提供决策指标支持。
2. kube-state-metrics关注于获取k8s各种资源的最新状态,如deployment或者daemonset,之所以没有把kube-state-metrics纳入到metric-server的能力中,是因为他们的关注点本质上是不一样的。metric-server仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而kube-state-metrics是将k8s的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
3. 换个角度讲,kube-state-metrics本身是metric-server的一种数据来源,虽然现在没有这么做。
4. 另外,像Prometheus这种监控系统,并不会去用metric-server中的数据,他都是自己做指标收集、集成的(Prometheus包含了metric-server的能力),但Prometheus可以监控metric-server本身组件的监控状态并适时报警,这里的监控就可以通过kube-state-metrics来实现,如metric-serverpod的运行状态。
优化点和问题:
1.因为kube-state-metrics是监听资源的add、delete、update事件,那么在kube-state-metrics部署之前已经运行的资源,岂不是拿不到数据?kube-state-metric利用client-go可以初始化所有已经存在的资源对象,确保没有任何遗漏
2.kube-state-metrics当前不会输出metadata信息(如help和description)
3.缓存实现是基于golang的map,解决并发读问题当期是用了一个简单的互斥锁,应该可以解决问题,后续会考虑golang的sync.Map安全map。
4.kube-state-metrics通过比较resource version来保证event的顺序
5.kube-state-metrics并不保证包含所有资源
3.2 kube-state-metrics部署
github地址:https://github.com/kubernetes/kube-state-metrics
Kubernetes部署: https://github.com/kubernetes/kube-state-metrics#kubernetes-deployment
#要根据你的k8s集群版本选择对应的kube-state-metrics版本。
#wget https://github.com/kubernetes/kube-state-metrics/archive/v1.9.5.tar.gz
#tar zxf v1.9.5.tar.gz
# cd kube-state-metrics-1.9.5/examples/
# kubectl apply -f standard/
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created deployment.apps/kube-state-metrics created serviceaccount/kube-state-metrics created service/kube-state-metrics created
# kubectl get pods -n kube-system |grep kube-state-metrics
kube-state-metrics-54d587f66c-dc2mv 1/1 Running 0 12m
# kubectl logs kube-state-metrics-54d587f66c-dc2mv -n kube-system
I0315 03:07:11.290601 1 main.go:86] Using default collectors I0315 03:07:11.290665 1 main.go:98] Using all namespace I0315 03:07:11.290673 1 main.go:139] metric white-blacklisting: blacklisting the following items: W0315 03:07:11.290695 1 client_config.go:543] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. I0315 03:07:11.291800 1 main.go:184] Testing communication with server I0315 03:07:11.298582 1 main.go:189] Running with Kubernetes cluster version: v1.17. git version: v1.17.2. git tree state: clean. commit: 59603c6e503c87169aea6106f57b9f242f64df89. platform: linux/amd64 I0315 03:07:11.298603 1 main.go:191] Communication with server successful I0315 03:07:11.298723 1 main.go:225] Starting metrics server: 0.0.0.0:8080 I0315 03:07:11.298908 1 metrics_handler.go:96] Autosharding disabled I0315 03:07:11.300469 1 builder.go:146] Active collectors: certificatesigningrequests,configmaps,cronjobs,daemonsets,deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,limitranges,mutatingwebhookconfigurations,namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes,poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas,secrets,services,statefulsets,storageclasses,validatingwebhookconfigurations,volumeattachments I0315 03:07:11.299537 1 main.go:200] Starting kube-state-metrics self metrics server: 0.0.0.0:8081
3. 3 将kube-state-metrics中的数据采集出来
- job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
博文来自:www.51niux.com
四、kube-state-metrics指标记录
所有监控的指标:https://github.com/kubernetes/kube-state-metrics/tree/master/docs
4.1 ConfigMap Metrics
#查询地址指标数据地址:https://github.com/kubernetes/kube-state-metrics/blob/master/internal/store/configmap_test.go
http://www.programmersought.com/article/8189690165/
kube_configmap_info #gauge类型,有关configmap的信息 kube_configmap_created #gauge类型,Unix创建时间戳 kube_configmap_metadata_resource_version #gauge类型,表示configmap特定版本的资源版本。
4.2 CronJob Metrics
#查询地址:https://github.com/kubernetes/kube-state-metrics/blob/master/internal/store/cronjob_test.go
#其他的就不贴地址了哈,基本都是在https://github.com/kubernetes/kube-state-metrics/blob/master/internal/store/下面找指定名称_test.go标志的文件。
kube_cronjob_info #gauge类型,关于cronjob的信息 kube_cronjob_labels #gauge类型,Kubernetes标签转换为Prometheus标签。 kube_cronjob_created #gauge类型,Unix创建时间戳 kube_cronjob_next_schedule_time #gauge类型,下次应该安排cronjob。 在lastScheduleTime之后的时间,或者在cron作业的创建时间之后(如果从未计划过)。 使用它来确定作业是否延迟。 kube_cronjob_status_active #gauge类型,活动保持指向当前正在运行的作业的指针。 kube_cronjob_status_last_schedule_time #gauge类型,LastScheduleTime保留有关上一次成功调度作业的时间的信息。 kube_cronjob_spec_suspend #gauge类型,挂起标志告诉控制器挂起后续执行。 kube_cronjob_spec_starting_deadline_seconds #gauge类型,如果由于任何原因错过了计划时间,则开始工作的最后期限(以秒为单位)。
4.3 DaemonSet Metrics
kube_daemonset_created #gauge类型,Unix创建时间戳 kube_daemonset_status_current_number_scheduled #gauge类型,运行至少一个且应该运行的守护程序容器的节点数。 kube_daemonset_status_desired_number_scheduled #gauge类型,应该运行守护程序容器的节点数。 kube_daemonset_status_number_available #gauge类型,应该运行守护程序容器并具有一个或多个守护程序容器正在运行并且可用的节点数 kube_daemonset_status_number_misscheduled #gauge类型,运行守护程序容器但不应该运行的节点数。 kube_daemonset_status_number_ready #gauge类型,应该运行守护程序容器并已运行一个或多个守护程序容器并准备就绪的节点数。 kube_daemonset_status_number_unavailable #gauge类型,应该运行守护程序容器且没有任何守护程序容器正在运行并且可用的节点数 kube_daemonset_updated_number_scheduled #gauge类型,正在运行更新的守护程序pod的节点总数 kube_daemonset_metadata_generation #gauge类型,代表所需状态的特定生成的序列号。 kube_daemonset_labels #gauge类型,Kubernetes标签转换为Prometheus标签。
4.4 Deployment Metrics
kube_deployment_status_replicas #Gauge类型,每个deployment的副本数。 kube_deployment_status_replicas_available #Gauge类型,每个deployment的可用副本数 kube_deployment_status_replicas_unavailable #Gauge类型,每个deployment中不可用副本的数量 kube_deployment_status_replicas_updated #Gauge类型,每个deployment的更新副本数 kube_deployment_status_observed_generation #Gauge类型,deployment控制器观察到的生成 kube_deployment_status_condition #Gauge类型,部署的当前状态condition kube_deployment_spec_replicas #Gauge类型,deployment所需的Pod数 kube_deployment_spec_paused #Gauge类型,deployment是否暂停,并且deployment控制器不会处理。 kube_deployment_spec_strategy_rollingupdate_max_unavailable #Gauge类型, kube_deployment_spec_strategy_rollingupdate_max_surge #Gauge类型,滚动更新deployment期间的最大不可用副本数。 kube_deployment_metadata_generation #Gauge类型,代表期望状态的特定生成的序列号 kube_deployment_labels #Gauge类型,Kubernetes标签转换为Prometheus标签 kube_deployment_created #Gauge类型,Unix创建时间戳
4.5 Endpoint Metrics
kube_endpoint_address_not_ready #Gauge类型,endpoint中not ready的addresses数 kube_endpoint_address_available #Gauge类型,endpoint中可用的addresses数。 kube_endpoint_info #Gauge类型,有关endpoint的信息 kube_endpoint_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_endpoint_created #Gauge类型,Unix创建时间戳
4.6 Horizontal Pod Autoscaler Metrics
kube_horizontalpodautoscaler_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_horizontalpodautoscaler_metadata_generation #Gauge类型,通过HorizontalPodAutoscaler控制器观察到的生成。 kube_horizontalpodautoscaler_spec_max_replicas #Gauge类型,自动定标器可以设置的容器数量上限; 不能小于MinReplicas。 kube_horizontalpodautoscaler_spec_min_replicas #Gauge类型,自动定标器可以设置的Pod数量下限,默认为1。 kube_horizontalpodautoscaler_spec_target_metric #Gauge类型,此自动定标器在计算所需副本数时使用的度量标准。 kube_horizontalpodautoscaler_status_condition #Gauge类型,此自动定标器的条件。 kube_horizontalpodautoscaler_status_current_replicas #Gauge类型,此自动缩放器管理的Pod的当前副本数。 kube_horizontalpodautoscaler_status_desired_replicas #Gauge类型,此自动缩放器管理的所需Pod副本数。
4.7 Ingress Metrics
kube_ingress_info #Gauge类型,有关ingress的信息 kube_ingress_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_ingress_created #Gauge类型,Unix创建时间戳 kube_ingress_metadata_resource_version #Gauge类型,代表特定ingress版本的资源版本。 kube_ingress_path #Gauge类型,ingress host, paths and backend service 信息。 kube_ingress_tls #Gauge类型,ingress TLS host and secret 信息。
4.8 Job Metrics
kube_job_info #Gauge类型,有关job的信息。 kube_job_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_job_owner #Gauge类型,有关job所有者的信息。 kube_job_spec_parallelism #Gauge类型,在任何给定时间,job应运行的pod的最大期望数量。 kube_job_spec_completions #Gauge类型,运行job所需的成功完成的Pod数量。 kube_job_spec_active_deadline_seconds #Gauge类型,在系统尝试终止job之前,作业相对于startTime的活动持续时间(以秒为单位)。 kube_job_status_active #Gauge类型,正在运行的pod数。 kube_job_status_succeeded #Gauge类型,成功reached Phase的pod数量。 kube_job_status_failed #Gauge类型,Failed reached Phase的pod数量。 kube_job_status_start_time #Gauge类型,StartTime表示作业Job Manager job的时间。 kube_job_status_completion_time #Gauge类型,CompletionTime表示job完成的时间。 kube_job_complete #Gauge类型,job已完成执行。 kube_job_failed #Gauge类型,job执行失败。 kube_job_created #Gauge类型,Unix创建时间戳
4.9 Lease Metrics
kube_lease_owner #Gauge类型,有关lease所有者的信息。 kube_lease_renew_time #Gauge类型,Kube lease续订时间。
4.10 LimitRange Metrics
kube_limitrange #Gauge类型,有关limitrange的信息。 kube_limitrange_created #Gauge类型,Unix创建时间戳
4.11 MutatingWebhookConfiguration Metrics
kube_mutatingwebhookconfiguration_info #Gauge类型,有关MutatingWebhookConfiguration的信息。 kube_mutatingwebhookconfiguration_created #Gauge类型,Unix创建时间戳。 kube_mutatingwebhookconfiguration_metadata_resource_version #Gauge类型,资源版本,表示MutatingWebhookConfiguration的特定版本。
4.12 Namespace Metrics
kube_namespace_created #Gauge类型,Unix创建时间戳。 kube_namespace_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_namespace_status_condition #Gauge类型,命名空间的状态。 kube_namespace_status_phase #Gauge类型,kubernetes命名空间状态阶段。
4.13 Network Policy Metrics
kube_networkpolicy_created #Gauge类型,Unix创建时间戳。 kube_networkpolicy_labels #Gauge类型, kube_networkpolicy_spec_egress_rules #Gauge类型,规格出口规则 kube_networkpolicy_spec_ingress_rules #Gauge类型,规格入口规则
4.14 Node Metrics
kube_node_info #Gauge类型,有关群集节点的信息。 kube_node_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_node_role #Gauge类型,集群节点的角色。 kube_node_spec_unschedulable #Gauge类型,节点是否可以调度新的Pod。 kube_node_spec_taint #Gauge类型,群集节点的污点。 kube_node_status_capacity #Gauge类型,节点不同资源的容量。 kube_node_status_allocatable #Gauge类型,可用于调度的节点的不同资源的可分配资源。 kube_node_status_condition #Gauge类型,群集节点的状况。 kube_node_created #Gauge类型,Unix创建时间戳。
4.15 PersistentVolume Metrics
kube_persistentvolume_capacity_bytes #Gauge类型,persistentvolume(持久卷)容量(以字节为单位)。 kube_persistentvolume_status_phase #Gauge类型,该阶段指示某个卷是否可用,绑定到声明或由声明释放。 kube_persistentvolume_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_persistentvolume_info #Gauge类型,有关持久卷的信息。
4.16 PersistentVolumeClaim Metrics
kube_persistentvolumeclaim_access_mode #Gauge类型,永久卷声明指定的访问模式。 kube_persistentvolumeclaim_info #Gauge类型,有关持久卷声明的信息。 kube_persistentvolumeclaim_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_persistentvolumeclaim_resource_requests_storage_bytes #Gauge类型,持久卷声明所请求的存储容量。 kube_persistentvolumeclaim_status_condition #Gauge类型,有关持续量索赔的不同条件的状态的信息。 kube_persistentvolumeclaim_status_phase #Gauge类型,永久批量声明当前处于此阶段。
4.17 PodDisruptionBudget Metrics
kube_poddisruptionbudget_created #Gauge类型,Unix创建时间戳。 kube_poddisruptionbudget_status_current_healthy #Gauge类型,当前健康pod的数量 kube_poddisruptionbudget_status_desired_healthy #Gauge类型,所需的健康pod的最小数量 kube_poddisruptionbudget_status_pod_disruptions_allowed #Gauge类型,当前允许的pod中断次数 kube_poddisruptionbudget_status_expected_pods #Gauge类型,此中断预算计算的pod总数 kube_poddisruptionbudget_status_observed_generation #Gauge类型,更新此PDB状态时观察到的最新一代
4.18 Pod Metrics
kube_pod_info #Gauge类型,有关pod的信息。 kube_pod_start_time #Gauge类型,pod的unix时间戳记中的开始时间。 kube_pod_completion_time #Gauge类型,pod的unix时间戳记中的完成时间。 kube_pod_owner #Gauge类型,有关Pod所有者的信息。 kube_pod_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_pod_status_phase #Gauge类型,Pod当前阶段。 kube_pod_status_ready #Gauge类型,描述容器是否准备好处理请求。 kube_pod_status_scheduled #Gauge类型,描述pod的调度过程的状态。 kube_pod_container_info #Gauge类型,有关容器中container的信息。 kube_pod_container_status_waiting #Gauge类型,描述容器当前是否处于等待状态。 kube_pod_container_status_waiting_reason #Gauge类型,描述容器当前处于等待状态的原因。 kube_pod_container_status_running #Gauge类型,描述容器当前是否处于运行状态。 kube_pod_container_status_terminated #Gauge类型,描述容器当前是否处于终止状态。 kube_pod_container_status_terminated_reason #Gauge类型,描述容器当前处于终止状态的原因。 kube_pod_container_status_last_terminated_reason #Gauge类型,描述容器处于终止状态的最后原因。 kube_pod_container_status_ready #Gauge类型,Describes whether the containers readiness check succeeded. kube_pod_container_status_restarts_total #Gauge类型,每个容器的容器重新启动次数。 kube_pod_container_resource_requests #Gauge类型,容器请求的请求资源数。 kube_pod_container_resource_limits #Gauge类型,容器请求的限制资源数量。 kube_pod_overhead #Gauge类型 kube_pod_created #Gauge类型,Unix创建时间戳。 kube_pod_deletion_timestamp #Gauge类型,Unix删除时间戳 kube_pod_restart_policy #Gauge类型,描述此pod使用的重新启动策略。 kube_pod_init_container_info #Gauge类型,有关Pod中init容器的信息。 kube_pod_init_container_status_waiting #Gauge类型,描述初始化容器当前是否处于等待状态。 kube_pod_init_container_status_waiting_reason #Gauge类型,Describes the reason the init container is currently in waiting state. kube_pod_init_container_status_running #Gauge类型,描述初始化容器当前是否处于运行状态。 kube_pod_init_container_status_terminated #Gauge类型,描述初始化容器当前是否处于终止状态。 kube_pod_init_container_status_terminated_reason #Gauge类型,描述初始化容器当前处于终止状态的原因。 kube_pod_init_container_status_last_terminated_reason #Gauge类型,描述初始化容器处于终止状态的最后原因。 kube_pod_init_container_status_ready #Gauge类型,描述初始化容器准备情况检查是否成功。 kube_pod_init_container_status_restarts_total #Counter类型,初始化容器的重新启动次数。 kube_pod_init_container_resource_limits #Gauge类型,初始化容器请求的限制资源数。 kube_pod_spec_volumes_persistentvolumeclaims_info #Gauge类型,有关Pod中持久卷声明卷的信息。 kube_pod_spec_volumes_persistentvolumeclaims_readonly #Gauge类型,描述是否以只读方式安装了持久卷声明。 kube_pod_status_reason #Gauge类型,pod状态原因 kube_pod_status_scheduled_time #Gauge类型,Pod移至计划状态时的Unix时间戳 kube_pod_status_unschedulable #Gauge类型,描述pod的unschedulable状态。
4.19 ReplicaSet Metrics
kube_replicaset_status_replicas #Gauge类型,每个ReplicaSet的副本数。 kube_replicaset_status_fully_labeled_replicas #Gauge类型,每个ReplicaSet的全标签副本数。 kube_replicaset_status_ready_replicas #Gauge类型,每个ReplicaSet的就绪副本数。 kube_replicaset_status_observed_generation #Gauge类型,ReplicaSet控制器观察到的生成。 kube_replicaset_spec_replicas #Gauge类型,ReplicaSet所需的pods数。 kube_replicaset_metadata_generation #Gauge类型,代表所需状态的特定生成的序列号。 kube_replicaset_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_replicaset_created #Gauge类型,Unix创建时间戳。 kube_replicaset_owner #Gauge类型,有关副本集所有者的信息。
4.20 ReplicationController metrics
kube_replicationcontroller_status_replicas #Gauge类型,每个ReplicationController的副本数。 kube_replicationcontroller_status_fully_labeled_replicas #Gauge类型,每个ReplicationController具有完全标记的副本数。 kube_replicationcontroller_status_ready_replicas #Gauge类型,每个ReplicationController的就绪副本数。 kube_replicationcontroller_status_available_replicas #Gauge类型,每个ReplicationController可用副本的数量。 kube_replicationcontroller_status_observed_generation #Gauge类型,ReplicationController控制器观察到的生成。 kube_replicationcontroller_spec_replicas #Gauge类型,ReplicationController所需的Pod数。 kube_replicationcontroller_metadata_generation #Gauge类型,代表所需状态的特定生成的序列号。 kube_replicationcontroller_created #Gauge类型,Unix创建时间戳。 kube_replicationcontroller_owner #Gauge类型,有关ReplicationController所有者的信息。
4.21 ResourceQuota Metrics
kube_resourcequota #Gauge类型,有关资源配额的信息。 kube_resourcequota_created #Gauge类型,Unix创建时间戳。
4.22 Secret Metrics
kube_secret_info #Gauge类型,有关secret的信息。 kube_secret_type #Gauge类型,Type about secret. kube_secret_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_secret_created #Gauge类型,Unix创建时间戳。 kube_secret_metadata_resource_version #Gauge类型,代表secret特定版本的资源版本。
4.23 Service Metrics
kube_service_info #Gauge类型,有关service的信息。 kube_service_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_service_created #Gauge类型,Unix创建时间戳。 kube_service_spec_type #Gauge类型,Type about service. kube_service_spec_external_ip #Gauge类型,服务外部IP。 每个IP一个组。 kube_service_status_load_balancer_ingress #Gauge类型,服务负载均衡器入口状态
4.24 Stateful Set Metrics
kube_statefulset_status_replicas #Gauge类型,每个StatefulSet的副本数。 kube_statefulset_status_replicas_current #Gauge类型,每个StatefulSet的当前副本数。 kube_statefulset_status_replicas_ready #Gauge类型,每个StatefulSet的就绪副本数。 kube_statefulset_status_replicas_updated #Gauge类型,每个StatefulSet的更新副本数。 kube_statefulset_status_observed_generation #Gauge类型,StatefulSet控制器观察到的生成。 kube_statefulset_replicas #Gauge类型,StatefulSet所需的pod数。 kube_statefulset_metadata_generation #Gauge类型,表示StatefulSet所需状态的特定生成的序列号。 kube_statefulset_created #Gauge类型,Unix创建时间戳。 kube_statefulset_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_statefulset_status_current_revision #Gauge类型,指示用于按顺序[0,currentReplicas)生成Pod的StatefulSet的版本。 kube_statefulset_status_update_revision #Gauge类型,指示用于按顺序[replicas-updatedReplicas,replicas]生成Pod的StatefulSet的版本。
4.25 StorageClass Metrics
kube_storageclass_info #Gauge类型,有关storageclass的信息。 kube_storageclass_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_storageclass_created #Gauge类型,Unix创建时间戳。
4.26 ValidatingWebhookConfiguration Metrics
kube_validatingwebhookconfiguration_info #Gauge类型,有关ValidatingWebhookConfiguration的信息。 kube_validatingwebhookconfiguration_created #Gauge类型,Unix创建时间戳。 kube_validatingwebhookconfiguration_metadata_resource_version #Gauge类型,表示ValidatingWebhookConfiguration特定版本的资源版本。
4.27 Vertical Pod Autoscaler Metrics
kube_verticalpodautoscaler_spec_resourcepolicy_container_policies_minallowed #Gauge类型,VerticalPodAutoscaler可以为与名称匹配的容器设置的最小资源。 kube_verticalpodautoscaler_spec_resourcepolicy_container_policies_maxallowed #Gauge类型,VerticalPodAutoscaler可以为与名称匹配的容器设置的最大资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_lowerbound #Gauge类型,在VerticalPodAutoscaler更新程序逐出容器之前,容器可以使用的最少资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_target #Gauge类型,VerticalPodAutoscaler为容器推荐的目标资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_uncappedtarget #Gauge类型,VerticalPodAutoscaler建议的目标资源,用于忽略边界的容器。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_upperbound #Gauge类型,在VerticalPodAutoscaler更新程序逐出容器之前,容器可以使用的最大资源。 kube_verticalpodautoscaler_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_verticalpodautoscaler_spec_updatepolicy_updatemode #Gauge类型,VerticalPodAutoscaler的更新模式。
4.28 Vertical Pod Autoscaler Metrics
kube_verticalpodautoscaler_spec_resourcepolicy_container_policies_minallowed #Gauge类型,VerticalPodAutoscaler可以为与名称匹配的容器设置的最小资源。 kube_verticalpodautoscaler_spec_resourcepolicy_container_policies_maxallowed #Gauge类型,VerticalPodAutoscaler可以为与名称匹配的容器设置的最大资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_lowerbound #Gauge类型,在VerticalPodAutoscaler更新程序逐出容器之前,容器可以使用的最少资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_target #Gauge类型,VerticalPodAutoscaler为容器推荐的目标资源。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_uncappedtarget #Gauge类型,VerticalPodAutoscaler建议的目标资源,用于忽略边界的容器。 kube_verticalpodautoscaler_status_recommendation_containerrecommendations_upperbound #Gauge类型,在VerticalPodAutoscaler更新程序逐出容器之前,容器可以使用的最大资源。 kube_verticalpodautoscaler_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_verticalpodautoscaler_spec_updatepolicy_updatemode #Gauge类型,VerticalPodAutoscaler的更新模式。
4.29 VolumeAttachment Metrics
kube_volumeattachment_info #Gauge类型,有关volumeattachment的信息。 kube_volumeattachment_created #Gauge类型,Unix创建时间戳。 kube_volumeattachment_labels #Gauge类型,Kubernetes标签转换为Prometheus标签。 kube_volumeattachment_spec_source_persistentvolume #Gauge类型,PersistentVolume源参考。 kube_volumeattachment_status_attached #Gauge类型,Information about volumeattachment. status kube_volumeattachment_status_attachment_metadata #Gauge类型,volumeattachment metadata.
