Prometheus查询语句PromQL(三)
#好的经历了上一章,我们对官网的翻译以及Prometheus及node_export的安装,已经采集了一些数据可以进行一些可视化展示了。
一、还是要跟着官网简单了解一下(直接忽略)
1.1 EXPRESSION BROWSER(浏览器展示)
表达式浏览器位于Prometheus服务器上的/graph上,可让你输入任何表达式并在表中或随时间绘制图形中查看其结果。这主要用于临时查询和调试。 对于图形,请使用Grafana or Console templates。
1.2 Grafana
Grafana支持查询Prometheus。 从Grafana 2.5.0(2015-10-28)开始包含Prometheus的Grafana数据源。剩下的操作会用实操代替。
1.3 CONSOLE TEMPLATES
控制台模板允许使用Go模板语言创建任意控制台。 这些是从Prometheus服务器提供的。控制台模板是创建可在源代码管理中轻松管理的模板的最强大方法。 不过,这是一条学习曲线,因此刚接触这种监视方式的用户应首先尝试使用Grafana。
Getting started(入门):
Prometheus附带了一组示例控制台,助你一臂之力。可以在运行的Prometheus上的/consoles/index.html.example上找到这些文件,如果Prometheus的带有job="node"标签的scraping Node Exporters,它们将显示Node Exporter控制台。
示例控制台包含5个部分:
顶部的导航栏 左侧菜单 底部的时间控制 中心的主要内容,通常是图形 右边的table
导航栏用于链接到其他系统,例如其他Prometheis 1,文档以及你认为有意义的其他内容。 该菜单用于在同一Prometheus服务器中导航,这对于能够快速打开另一个选项卡中的控制台以关联信息非常有用。 两者都在console_libraries/menu.lib中配置。时间控件允许更改图表的持续时间和范围。 控制台URL可以共享,其他URL将显示相同的图形。
主要内容通常是图形。提供了一个可配置的JavaScript图形库,该库将处理来自Prometheus的请求数据,并通过Rickshaw(https://shutterstock.github.io/rickshaw/)进行呈现。
最后,可以使用右侧的表格以比图表更紧凑的形式显示统计信息。
Example Console(控制台示例):
这是一个基本的控制台。 它在右侧表中显示任务的数量,其中有多少正在运行,平均CPU使用率以及平均内存使用率。 主要内容具有“每秒查询数”图。
{{template "head" .}}
{{template "prom_right_table_head"}}
<tr>
<th>MyJob</th>
<th>{{ template "prom_query_drilldown" (args "sum(up{job='myjob'})") }}
/ {{ template "prom_query_drilldown" (args "count(up{job='myjob'})") }}
</th>
</tr>
<tr>
<td>CPU</td>
<td>{{ template "prom_query_drilldown" (args
"avg by(job)(rate(process_cpu_seconds_total{job='myjob'}[5m]))"
"s/s" "humanizeNoSmallPrefix") }}
</td>
</tr>
<tr>
<td>Memory</td>
<td>{{ template "prom_query_drilldown" (args
"avg by(job)(process_resident_memory_bytes{job='myjob'})"
"B" "humanize1024") }}
</td>
</tr>
{{template "prom_right_table_tail"}}
{{template "prom_content_head" .}}
<h1>MyJob</h1>
<h3>Queries</h3>
<div id="queryGraph"></div>
<script>
new PromConsole.Graph({
node: document.querySelector("#queryGraph"),
expr: "sum(rate(http_query_count{job='myjob'}[5m]))",
name: "Queries",
yAxisFormatter: PromConsole.NumberFormatter.humanizeNoSmallPrefix,
yHoverFormatter: PromConsole.NumberFormatter.humanizeNoSmallPrefix,
yUnits: "/s",
yTitle: "Queries"
})
</script>
{{template "prom_content_tail" .}}
{{template "tail"}}prom_right_table_head和prom_right_table_tail模板包含右侧表。 这是可选的。prom_query_drilldown是一个模板,它将评估传递给它的表达式,对其进行格式设置并链接到表达式浏览器中的表达式。 第一个参数是表达式。 第二个参数是要使用的单位。 第三个参数是如何格式化输出。 仅第一个参数是必需的。
prom_query_drilldown的第三个参数的有效输出格式:
Not specified:默认Go显示输出。 humanize:使用度量标准前缀显示结果。 humanizeNoSmallPrefix:对于大于1的绝对值,请使用度量标准前缀显示结果。 对于小于1的绝对值,请显示3个有效数字。 这对于避免人为化可产生的每秒单位很有用。 humanize1024:使用1024而不是1000的底数显示人性化结果。通常将其与B作为第二个参数一起使用,以产生单位,例如KiB和MiB。 printf.3g:显示3位有效数字。
可以定义自定义格式。 有关示例,请参见prom.lib:https://github.com/prometheus/prometheus/blob/master/console_libraries/prom.lib
Graph Library(图库):
图形库的调用方式为:
<div id="queryGraph"></div>
<script>
new PromConsole.Graph({
node: document.querySelector("#queryGraph"),
expr: "sum(rate(http_query_count{job='myjob'}[5m]))"
})
</script>头模板加载所需的Javascript和CSS。
图形库的参数:
expr #需要。要表达的图形。可以是列表。 node #需要。要渲染到的DOM节点。 duration #可选的。图的持续时间。默认为1小时。 endTime #可选的。Unixtime,图形结束于。默认为现在。 width #可选的。图的宽度,不包括标题。默认为自动检测。 height #可选的。图形的高度,不包括标题和图例。默认为200像素。 min #可选的。最小x轴值。默认为最低数据值。 max #可选的。y轴最大值。默认为最高数据值。 renderer #可选的。图的类型。选项是线和area(堆叠图)。默认为line。 name #可选的。图例标题中的图例和悬停详细信息。如果传递了字符串,则[[label]]将替换为标签值。如果传递了一个函数,它将传递一个标签映射,并且应将名称作为字符串返回。 可以是列表。 xTitle #可选的。x轴的标题。默认为时间。 yUnits #可选的。y轴的单位。默认为空。 yTitle #可选的。y轴的标题。默认为空。 yAxisFormatter #可选的。y轴的数字格式器。默认为PromConsole.NumberFormatter.humanize。 yHoverFormatter #可选的。悬停详细信息的数字格式化程序。默认为PromConsole.NumberFormatter.humanizeExact。 colorScheme #可选的。绘图要使用的配色方案。可以是十六进制颜色代码的列表,也可以是Rickshaw支持的颜色方案名称之一。 默认为“colorwheel”。
#配色方案名称:https://github.com/shutterstock/rickshaw/blob/master/src/js/Rickshaw.Fixtures.Color.js
如果expr和name均为列表,则它们的长度必须相同。 该名称将应用于对应表达式的图。
yAxisFormatter和yHoverFormatter的有效选项:
PromConsole.NumberFormatter.humanize:使用度量标准前缀进行格式化。 PromConsole.NumberFormatter.humanizeNoSmallPrefix:对于大于1的绝对值,请使用度量标准前缀格式化。对于绝对值小于1的格式,请使用3个有效数字。这对于避免PromConsole.NumberFormatter.humanize可以生成的单位(例如milliqueries per second)很有用。 PromConsole.NumberFormatter.humanize1024:使用1024而不是1000的底数格式化人性化的结果。
metric prefixes:https://en.wikipedia.org/wiki/Metric_prefix
二、结合着数据各种查询走一波
#理论知识请参照此链接的二、三部分:http://www.51niux.com/?id=244
2.1 先来个简单查询了解下数据结构
指标的定义:
node_cpu_seconds_total{cpu="0",instance="192.168.1.141:9100",job="docker-es",mode="idle"} 6130818.09#上图是我们根据查询语句node_cpu_seconds_total查出来的众多记录中的一条记录。
指标名称(metric name):
上面记录中的node_cpu_seconds_total就是指标名称。
指标名称用于说明指标的含义,例如http_request_total代表HTTP的请求总数。指标名称必须由字母、数值下画线或者冒号组成,符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*,其中的冒号指标不能用于exporter。
标签(label):
{cpu="0",instance="192.168.1.141:9100",job="docker-es",mode="idle"} 中cpu,instance,job,mode都是标签名,后面""中的就是标签值。
标签可体现指标的维度特征,用于过滤和聚合。它通过标签名(label name)和标签值(labelvalue)这种键值对的形式,形成多种维度。例如,对于指标 http_request_total,可以有{status="200",method="POST"}和{status="200",method="GET"}这两个标签。在需要分别获取GET和POST返回200的请求时,可分别使用上述两种指标;在需要获取所有返回200的请求时,可以通过http_request_total{status="200"}完成数据的聚合,非常便捷和通用。指标的某些标签是以“__”开头的,这些标签是在Prometheus系统内部使用的。在形式上,http_request_total{status="200"} 和 {__name__="http_request_total",status="200"}代表相同的指标。Prometheus 指标采用标签的方式能够很好地与容器结合,无论是原生Docker还是Kubernetes,都通过标签关联资源。
指标的分类:
Prometheus指标分为Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)和Summary(摘要)这4类,上一章已经详细讲解过了。
Counter是计数器类型,它的特点是只增不减,例如机器启动时间、HTTP访问量等。
Gauge是仪表盘,表征指标的实时变化情况,可增可减,例如内存的使用量等,大部分监控数据都是 Gauge 类型的。
Summary 同 Histogram 一样,都属于高级指标,用于凸显数据的分布状况。
Histogram反映了某个区间内的样本个数,通过{le="上边界"}指定这个范围内的样本数。
#上面是这四种指标的大概意思,那么我们怎么来区分采集上来的指标数据属于那种分类呢,当然就是根据其特性去分类了。
#当然前期呢,我们可以通过参照node_export传上来的指标数据去做区分学习,因为传上来的数据都是注释的。
访问浏览器:http://192.168.1.141:9100/metrics
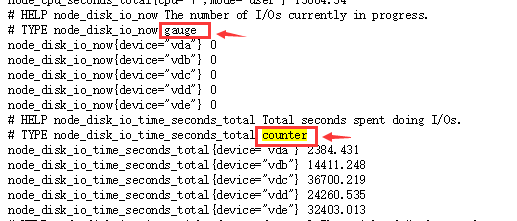
#如上图你其实是可以根据HELP了解这个数据是什么数据,根据TYPE了解这个数据属于什么指标。
列出所有指标项及注意项:
#如果我们想列出所有指标怎么办呢?
({__name__=~".+"})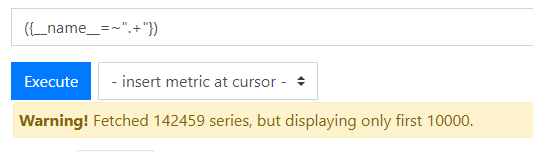
#上图的意思是查询到了14W多条数据但是只显示1W条,注意现在千万别点击Graph,除非你想把prometheus服务干死,这么多数据绘图什么概念......当然一般也不建议这么查询数据。这就是前面所说的避免慢查询和超载。怎么来判断你这条语句不会造成系统太大的负担呢,一个是返回的结果的时间快,另一个如果你想使用graph功能,数据一定不要太多哈。
#如果我们想显示当前每个metric有多少个呢?
count by (__name__)({__name__=~".+"})#如果我们想干掉维度(Cardinality)过高的指标
# 统计每个指标的时间序列数,超出 10000 的报警
count by (__name__)({__name__=~".+"}) > 10000可以通过上面的方式找到使用比较高的指标,然后判断这种指标有没有必要采集或者里面的label有没有必要存在,然后在 Scrape 配置里 Drop 掉导致维度过高的 label,这样可以减少一些"坏指标",导致查询的时候数据量过大而OOM搞死Prometheus 实例。
博文来自:www.51niux.com
2.2 使用PromQL结合node_export上传的数据进行查询
#作为一个初学者来说要了解Querying中的函数啊操作符的具体意义啊还是结合node的监控数据来学习好一点。
关于node的CPU查询:
=和=~的区别:
node_cpu_seconds_total{instance="192.168.1.141:9100"}
node_cpu_seconds_total{instance=~"192.168.1.141.*"}
#看上图这里要注意啊,是CPU有几个核都会显示出来的。
#上面两句话的效果是一致的,如果你懒得输入端口好了就可以使用下面的表达式。
node_cpu_seconds_total{instance="192.168.1.141:9100|192.168.1.142:9100"} #这句话就什么都取不出来,因为不存在192.168.1.141:9100|192.168.1.142:9100这个instance。
node_cpu_seconds_total{instance=~"192.168.1.14[1-2].*"} #这句话呢就是把结尾是141和142的instance给过滤出来,比如还有143就过滤不出来了。
node_cpu_seconds_total{instance=~"192.168.1.141:9100|192.168.1.142:9100"} #这句话跟上面是一样的,多个匹配条件用|做分割
node_cpu_seconds_total{instance=~"192.168.1.141.*|192.168.1.142.*"} #当然也可以这样写了。
{__name__="node_cpu_seconds_total",instance=~"192.168.1.14[1-2].*",mode="idle"} #这句话跟下面那句话的结果是一样的
{__name__="node_cpu_seconds_total" } and {instance=~"192.168.1.14[1-2].*"} and {mode="idle"} #当然也可以这样写,但是不支持!=和!~哦,不过支持or哦。
{__name__!="node_cpu_seconds_total",job="docker-es",instance!="192.168.1.141:19100"} #当然也可以取metric不是node_cpu_seconds_total的指标,但是第二个规则不能取反。而且如果__name__取反的话,这个规则不能单独自己出现。再加一个!~和!=:
node_cpu_seconds_total{instance=~"192.168.1.14[1-2].*",instance="192.168.1.143:9100",mode="idle"} #这种肯定就取不出什么东西,这里多条标签是and的关系。
node_cpu_seconds_total{instance=~"192.168.1.14.*",instance!="192.168.1.143:9100",mode="idle"} #这是在查询出的结果中将143给去掉。
node_cpu_seconds_total{instance=~"192.168.1.14.*",instance!="192.168.1.143",mode="idle"} #这种因为取反失败,143还是会显示的。
node_cpu_seconds_total{instance=~"192.168.1.14.*",instance!~"192.168.1.143.*|192.168.1.141.*",mode="idle"} #这里就是在查询结果中将141和143去掉。范围向量选择器:
#上面得出来的值都是当时那个时刻采集的值也就是最近的一次的值。

#上图很清晰的给我们展示了counter这种数据指标类型的特性,就是一直增加不会有下降的时候。
node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[3m]
#显示右侧的结果为:
Value
6150954.22 @1583768291.609
6150968.8 @1583768306.596
6150983.45 @1583768321.596
6150998.07 @1583768336.596
6151012.61 @1583768351.596
6151027.21 @1583768366.596
6151041.82 @1583768381.596
6151056.44 @1583768396.596
6151070.95 @1583768411.596
6151085.55 @1583768426.596
6151100.14 @1583768441.596
6151114.72 @1583768456.596#因为我是15秒采集一次所以一分钟是四个值,那么3分钟内的监控数据就是3*4=12个数据,上面显示的结构就是(值@时间戳),可见是倒叙排序
函数(rate和irate):
irate和rate都会用于计算某个指标在一定时间间隔内的变化速率。但是它们的计算方法有所不同:irate取的是在指定时间范围内的最近两个数据点来算速率,而rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果。
irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。irate 只能用于绘制快速变化的计数器,在长期趋势分析或者告警中更推荐使用 rate 函数。因为使用 irate 函数时,速率的简短变化会重置 FOR 语句,形成的图形有很多波峰。
rate(node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[3m]) #这是取出3分钟内node各核CPU的idle每秒时间。集合运算符:
avg(rate(node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[5m]) * 100) by (instance) #计算某个实例cpu的空闲率,avg就是irate的平均数,然后by自居就是通过什么标签聚合
#Value是98.48333333386108
sum(rate(node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[5m]) * 100) by (instance) #因为我是8核所以将所有的cpu的核数的值聚合
#Value是786.1999999980133
round((100 - avg(rate(node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[5m]) * 100) by (instance)),0.01) #取出CPU的使用率,round是四舍五入成整数,但是我们加了0.01就是表示精确小数点后两位。
#Value是1.52
round(sum(rate(node_cpu_seconds_total{mode="idle",instance="192.168.1.141:9100"}[5m]) * 100) by (instance)/sum(irate(node_cpu_seconds_total{instance="192.168.1.141:9100"}[5m]) * 100) by (instance),0.0001) #算cpu的空闲率
#Value是0.9676
round(avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])),0.01) #取所有instance的cpu的空闲率,但是你这里只会显示instance一个标签#注意 PromQL 里要先 rate() 再 sum(),不能 sum() 完再 rate()。
#如果想统计每个实例多少个CPU,并且想多显示一些标签:
count by (mode,job,instance) (rate(node_cpu_seconds_total{mode="idle"}[1m]))
count without(instance,cpu,mode) (rate(node_cpu_seconds_total{mode="idle"}[1m])) #这是显示结果中不以instance,cpu和mode聚合
count by(job) (rate(node_cpu_seconds_total{mode="idle"}[1m])) #这句话就跟上面意思一样了,如果我们的label里面只有(job,instance,cpu和mode)
#如果要统计一个实例的cpu各方面的指标并且让其降序排序呢
sort_desc(avg by(mode) (rate(node_cpu_seconds_total{instance="192.168.1.141:9100"}[1m])) * 100)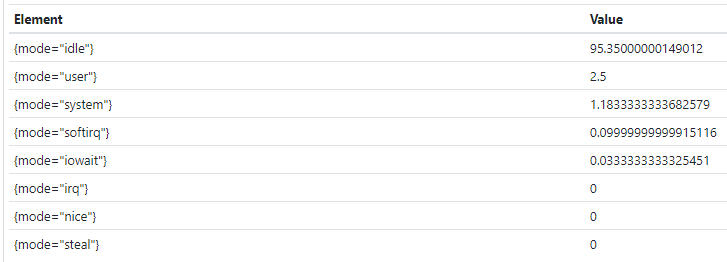
#如果要统计cpu空闲率最低的三个实例呢(最高就是用top了)?默认显示的结果也是上面的数值小底部的数值大这种排序方式。
bottomk(3,avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100)#如果要统计每个实例cpu里面多核聚合后多指标的值?
avg by(mode,instance) (rate(node_cpu_seconds_total[1m])) * 100
#如果要统计出每个实例cpu里面多核聚合后多指标的值并且cpu的空闲率要大于95呢?
avg by(instance,mode) (rate(node_cpu_seconds_total[1m])) * 100 and avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100 >95
avg by(instance) (rate(node_cpu_seconds_total[1m])) * 100 unless avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100 <95
#unless就是并且取反后面的结果,并且除非的意思。increase()和rate():
increase函数:该函数配合counter数据类型使用,获取区间向量中的第一个和最后一个样本并返回其增长量。如果除以一定时间就可以获取该时间内的平均增长率
rate()函数:该函数配合counter类型数据使用,取counter在这个时间段中的平均每秒增量。比方网卡1分钟增长了1024字节,那么结果就是1024字节/60。
avg(increase(node_cpu_seconds_total{mode="idle"}[1m])/60) by (instance)
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)#上面两句话取出来的结果是一样的,只不过rate()是直接算出区间向量的平均速率,而increase()你要自己去除于秒数。
#当然也可以这样计算cpu的总使用率:
(1 - sum(increase(node_cpu_seconds_total{mode='idle'}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)) * 100#上面的话的意思大概就是先用increase()函数把cpu空闲率1分钟的增量算出来,然后用sum把各个核的增加加合,然后用同样的方法把cpu的所有时间的增量算出来,然后1-空闲/总量(空闲百分比)。
计算CPU其他的时间:
#通过上面的一系列对比已经大概掌握了常用的查询语句,下面写一下其他时间统计的例子:
#iowait io等待时间占比
sum(increase(node_cpu_seconds_total{mode="iowait"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#irq 硬中断时间占比
sum(increase(node_cpu_seconds_total{mode="irq"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#soft irq软中断时间占比
sum(increase(node_cpu_seconds_total{mode="softirq"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#steal虚拟机的分片时间占比
sum(increase(node_cpu_seconds_total{mode="steal"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#nice进程分配nice值的时间占比
sum(increase(node_cpu_seconds_total{mode="nice"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#user用户态时间占比
sum(increase(node_cpu_seconds_total{mode="user"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)#sytem内核态时间占比
sum(increase(node_cpu_seconds_total{mode="system"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total{}[1m]) ) by(instance)关于node的内存查询:
博文来自:www.51niux.com
我们先根据metrics页面把node_memory_的相关项统计一下并且记录下大概是什么意思虽然我们大部分用不上
node_memory_Active_anon_bytes #gauge类型, 最近被访问过的匿名页和交换区缓存(包括 tmpfs),/proc/meminfo信息中的Active(anon)字段。 node_memory_Active_bytes #gauge类型,最近被频繁使用的内存,除非绝对必要,否则通常不会回收,/proc/meminfo信息中的Active字段。 node_memory_Active_file_bytes #gauge类型,最近被访问过的与文件对应的内存页,/proc/meminfo信息中的Active(file)字段。 node_memory_AnonHugePages_bytes #gauge类型,AnonHugePages 占用的内存大小,/proc/meminfo信息中的AnonHugePages字段。 node_memory_AnonPages_bytes #gauge类型,用户进程中匿名内存页大小,/proc/meminfo信息中的AnonPages字段。 node_memory_Bounce_bytes #gauge类型,bounce buffers 占用的内存。 node_memory_Buffers_bytes #gauge类型,内存中的Buffers_bytes。 node_memory_Cached_bytes #gauge类型,Cached缓存占的内存大小。 node_memory_CommitLimit_bytes #gauge类型,当前系统可分配的内存量,/proc/meminfo信息中的CommitLimit字段。 node_memory_Committed_AS_bytes #gauge类型,当前系统已经分配的内存量,包括已分配但尚未使用的内存大小,/proc/meminfo信息中的Committed_AS字段。 node_memory_DirectMap1G_bytes #gauge类型,映射为 1G 的内存页的内存数量,/proc/meminfo信息中的DirectMap1G字段。 node_memory_DirectMap2M_bytes #gauge类型, 映射为 2M 的内存页的内存数量,/proc/meminfo信息中的DirectMap2M字段。 node_memory_DirectMap4k_bytes #gauge类型,映射为 4kB 的内存页的内存数量,/proc/meminfo信息中的DirectMap4K字段。 node_memory_Dirty_bytes #gauge类型,需要写回磁盘的数据大小,/proc/meminfo信息中的Dirty字段。 node_memory_HardwareCorrupted_bytes #gauge类型,内核识别为已损坏或不工作的内存量,/proc/meminfo信息中的HardwareCorrupted字段。 node_memory_HugePages_Free #gauge类型,系统当前总共拥有的空闲 HugePages 数目,/proc/meminfo信息中的HugePages_Free字段。 node_memory_HugePages_Rsvd #gauge类型,内存中额HugePages_Rsvd的数目,/proc/meminfo信息中的HugePages_Rsvd字段。 node_memory_HugePages_Surp #gauge类型,超过系统设定的常驻HugePages数目的数目,/proc/meminfo信息中的HugePages_Surp字段。 node_memory_HugePages_Total #gauge类型,统当前总共拥有的HugePages数目,/proc/meminfo信息中的HugePages_Total字段。 node_memory_Hugepagesize_bytes #gauge类型,每一页HugePages的大小,/proc/meminfo信息中的Hugepagesize字段。 node_memory_Inactive_anon_bytes #gauge类型,长时间未被访问过的匿名页和交换区缓存(包括 tmpfs),/proc/meminfo信息中的Inactive(anon)字段。 node_memory_Inactive_bytes #gauge类型,最近使用较少的内存, 优先被回收利用,/proc/meminfo信息中的Inactive字段。 node_memory_Inactive_file_bytes #gauge类型,上长时间未被访问过的与文件对应的内存页,/proc/meminfo信息中的Inactive(file)字段。 node_memory_KernelStack_bytes #gauge类型,内核栈大小(常驻内存,不可回收),/proc/meminfo信息中的KernelStack字段。 node_memory_Mapped_bytes #gauge类型,mapped 缓存页占用的内存,/proc/meminfo信息中的Mapped字段。 node_memory_MemAvailable_bytes #gauge类型,已使用的内存(不包括Buffer缓存和Cached缓存),MemAvailable: Free + Buffers + Cached - 不可回收的部分。不可回收部分包括:共享内存段,tmpfs,ramfs等,/proc/meminfo信息中的MemAvailable字段。 node_memory_MemFree_bytes #gauge类型,空闲内存,/proc/meminfo信息中的MemFree字段。 node_memory_MemTotal_bytes #gauge类型,内存总大小,/proc/meminfo信息中的MemTotal字段。 node_memory_Mlocked_bytes #gauge类型,被mlock()系统调用锁定的内存大小,/proc/meminfo信息中的Mlocked字段。 node_memory_NFS_Unstable_bytes #gauge类型,发给NFS server但尚未写入硬盘的缓存大小,/proc/meminfo信息中的NFS_Unstable字段。 node_memory_PageTables_bytes #gauge类型,用于在虚拟和物理内存地址之间映射的内存,/proc/meminfo信息中的PageTables字段。 node_memory_SReclaimable_bytes #gauge类型,通过slab分配的内存中可回收的部分,/proc/meminfo信息中的SReclaimable字段。 node_memory_SUnreclaim_bytes #gauge类型, 通过slab分配的内存中不可回收的部分,/proc/meminfo信息中的SUnreclaim字段。 node_memory_Shmem_bytes #gauge类型,共享内存的大小,/proc/meminfo信息中的Shmem字段。 node_memory_Slab_bytes #gauge类型,内核用于缓存数据结构以供自己使用的内存(如 inode,dentry 等缓存),/proc/meminfo信息中的Slab字段。 node_memory_SwapCached_bytes #gauge类型,用于跟踪已从交换区中提取出来但尚未修改的页面的内存,/proc/meminfo信息中的SwapCached字段。 node_memory_SwapFree_bytes #gauge类型,交换分区的空闲大小,/proc/meminfo信息中的SwapFree字段。 node_memory_SwapTotal_bytes #gauge类型,交换分区的大小,/proc/meminfo信息中的SwapTotal字段。 node_memory_Unevictable_bytes #gauge类型,不可被回收的内存,/proc/meminfo信息中的Unevictable字段。 node_memory_VmallocChunk_bytes #gauge类型, vmalloc可分配的最大的逻辑连续的内存大小,/proc/meminfo信息中的VmallocChunk字段。 node_memory_VmallocTotal_bytes #gauge类型,vmalloc可使用的总内存大小,/proc/meminfo信息中的VmallocTotal字段。 node_memory_VmallocUsed_bytes #gauge类型,vmalloc已用的总内存大小,/proc/meminfo信息中的VmallocUsed字段。 node_memory_WritebackTmp_bytes #gauge类型,FUSE用于临时写回缓冲区的内存,/proc/meminfo信息中的WritebackTmp字段。 node_memory_Writeback_bytes #gauge类型,正准备主动回写硬盘的缓存大小,/proc/meminfo信息中的Writeback字段。
#了解了上面每个metric指标的意义后就可以写下面的计算公式了
#计算内存使用率:
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100
关于node的load查询:
node_load1 #gauge类型 node_load15 #gauge类型 node_load5 #gauge类型
node_load1{instance=~"192.168.1.141.*"} #某个实例的1分钟负载
node_load5{instance=~"192.168.1.141.*"} #某个实例的5分钟负载
node_load15{instance=~"192.168.1.141.*"} #某个实例的15分钟负载
关于磁盘IO:
node_disk_io_now #gauge类型,每个磁盘分区每秒正在处理的的I/O数。 node_disk_io_time_seconds_total #counter类型,执行I/O的总秒数。 node_disk_io_time_weighted_seconds_total #counter类型,每个磁盘分区输入/输出操作花费的加权秒数 node_disk_read_bytes_total #counter类型,每个磁盘成功读取的总字节数 node_disk_read_time_seconds_total #counter类型,每个磁盘所有读取花费的总秒数 node_disk_reads_completed_total #counter类型,每个磁盘分区读取成功完成总数。 node_disk_reads_merged_total #counter类型,每个磁盘分区合并读完成总次数。 node_disk_write_time_seconds_total #counter类型,每个磁盘分区写入所花费的总秒数。 node_disk_writes_completed_total #counter类型,每个磁盘分区成功完成的写入总数。 node_disk_writes_merged_total #counter类型,每个磁盘分区合并写完成次数。 node_disk_written_bytes_total #counter类型,每个磁盘分区成功写入的总字节数。 node_textfile_scrape_error #gauge类型,如果打开或读取文件时出错,则为1,否则为0。
#每个实例磁盘分区每秒读完成次数
irate(node_disk_reads_completed_total[5m])
#每个实例磁盘分区每秒写完成次数
irate(node_disk_writes_completed_total[5m])
#每个实例磁盘分区每秒的读取的字节数。
irate(node_disk_read_bytes_total[1m])
irate(node_disk_read_bytes_total{device="vda"}[1m]) > 30000000 #只显示设备是vda并且读I/O是30MB/S的。#每个实例磁盘分区每秒的写入的字节数。
irate(node_disk_written_bytes_total[1m]))
irate(node_disk_written_bytes_total{device="vda"}[1m]) > 30000000 #只显示设备是vda并且写I/O是30MB/S的。#每个实例磁盘分区读花费的秒数。
irate(node_disk_read_time_seconds_total[1m])
#每个实例磁盘分区写花费的秒数。
(irate(node_disk_write_time_seconds_total[1m]))
#每个实例磁盘分区io空闲百分比
100 - (avg(irate(node_disk_io_time_seconds_total[5m])) by (instance,device) * 100)
关于磁盘空间:
node_filesystem_avail_bytes #gauge类型,非root用户可用的文件系统空间(以字节为单位) node_filesystem_device_error #gauge类型,获取给定设备的统计信息时是否发生错误 node_filesystem_files #gauge类型,文件系统总inode数 node_filesystem_files_free #gauge类型,文件系统总可用inode数 node_filesystem_free_bytes #gauge类型,文件系统可用空间(以字节为单位) node_filesystem_readonly #gauge类型,文件系统只读状态0为不只读。 node_filesystem_size_bytes #gauge类型,文件系统大小(以字节为单位) node_filefd_allocated #gauge类型,文件描述符统计:已分配 node_filefd_maximum #gauge类型,文件描述符统计:最大
查看挂载分区可用磁盘空间:
node_filesystem_avail_bytes{instance="192.168.1.141:9100"}/1024/1024
node_filesystem_free_bytes{instance="192.168.1.141:9100"}/1024/1024 #下面的要比上面/分区得出来的数略大,主要用这个参数就行
sort_desc(sum(node_filesystem_free_bytes{instance="192.168.1.141:9100"}/1024/1024) without (instance)) #可以通过sum在取出来的值的基础上再去掉一些不想显示的标签
#ceil(v instant-vector) #返回向量中所有样本值(向上取整数)
#如果要正则统计多台机器多个挂载分区的使用率:
(node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs"} - node_filesystem_free_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs"}) / node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs"} * 100
ceil((node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"} - node_filesystem_free_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"}) / node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"} *100)
sum(ceil((node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"} - node_filesystem_free_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"}) / node_filesystem_size_bytes{mountpoint=~"/|/data.*",fstype=~"ext.*|xfs|rootfs",instance=~"192.168.1.141.*"} *100)) without (instance)

#df -m 查看一下这台机器的磁盘空闲状态方便对比
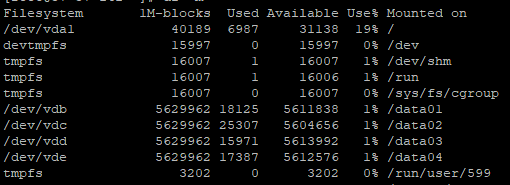
#预计磁盘挂载4个小时之后磁盘挂载分区剩余情况
predict_linear(node_filesystem_free_bytes[2h], 4 * 3600)
#磁盘分区inode的使用率
(1 - node_filesystem_files_free{fstype=~"ext4|xfs"} / node_filesystem_files{fstype=~"ext4|xfs"}) * 100#节点的文件描述符打开个数
node_filefd_allocated node_filefd_allocated/node_filefd_maximum*100 #那么这句话就是文件描述符使用的百分比了
博文来自:www.51niux.com
关于系统启动时间:
node_boot_time_seconds #gauge类型,节点启动时间,以Unix时间 node_time_seconds #gauge类型,自1970年以来的系统时间(以秒为单位) up #guage类型,判断主机是否存活,1为存活,0为不存活。
#获取节点的运行时间
time() - node_boot_time_seconds{} #当前时间减去启动时间,不就是节点的运行时间嘛关于节点网络(只记录下常用的吧):
node_network_address_assign_type #gauge类型,/sys/class/net/<iface>的address_assign_type的值 node_network_carrier #gauge类型 node_network_carrier_changes_total #gauge类型。 node_network_device_id #gauge类型 node_network_dormant #gauge类型 node_network_flags #gauge类型 node_network_iface_id #gauge类型 node_network_iface_link #gauge类型 node_network_iface_link_mode #gauge类型 node_network_info #gauge类型,值始终为1。 node_network_mtu_bytes #gauge类型 node_network_net_dev_group #gauge类型 node_network_protocol_type #gauge类型 node_network_receive_bytes_total #counter类型,各个网卡的入流量 node_network_receive_compressed_total #counter类型,各个网卡接收的压缩数据包总数 node_network_receive_drop_total #counter类型,各个网卡接收的丢弃的数据包总数 node_network_receive_errs_total #counter类型,各个网卡接收的错误数据包总数 node_network_receive_fifo_total #counter类型,各个网卡接收的 fifo包总数 node_network_receive_frame_total #counter类型 node_network_receive_multicast_total #counter类型,各个网卡接收的多播的包数 node_network_receive_packets_total #counter类型,各个网卡接收到的数据包总数 node_network_transmit_bytes_total #counter类型,各个网卡的出网流量 node_network_transmit_carrier_total #counter类型,各个网卡检测到的载波损耗的数量 node_network_transmit_colls_total #counter类型,各个网卡上检测到的冲突数 node_network_transmit_compressed_total #counter类型,各个网卡发送的压缩数据包总数 node_network_transmit_drop_total #counter类型,各个网卡发送的丢弃的数据包总数 node_network_transmit_errs_total #counter类型,各个网卡发送的错误数据包总数 node_network_transmit_fifo_total #counter类型,各个网卡发送的 fifo 包总数 node_network_transmit_packets_total #counter类型,各个网卡发送的数据包总数 node_network_transmit_queue_length #gauge类型 node_network_up #gauge类型,如果操作状态为"up",则值为1,否则为0
#统计网卡的入流量
sum by (instance) (rate(node_network_receive_bytes_total{device="eth0"}[5m]))
avg by (instance) (rate(node_network_receive_bytes_total{device="eth0"}[5m])) #注意当你一个网卡的时候用sum或者avg其实是没区别的
sum by (instance) (rate(node_network_receive_bytes_total{device=~"eth0|lo"}[5m])) #只是举例子,一般不统计lo网卡流量。但你当一个机器多个网卡的时候就不能用avg了,现在统计的是这台机器的机器流量而不是网卡流量#统计网卡的出流量
sum by (instance) (rate(node_network_transmit_bytes_total{device=~"eth0"}[5m]))
sum by (instance,device) (rate(node_network_transmit_bytes_total{device!~"lo"}[5m])) #这种方式就是统计多网卡的流量关于进程:
process_cpu_seconds_total #counter类型,用户和系统花费的总时间(以秒为单位) process_max_fds #gauge类型,打开文件描述符的最大数量 process_open_fds #guage类型,打开文件描述符的数量 process_resident_memory_bytes #gauge类型,驻留内存大小(以字节为单位) process_start_time_seconds #gauge类型,从Unix纪元开始的进程开始时间(以秒为单位) process_virtual_memory_bytes #gauge类型,虚拟内存大小(以字节为单位) process_virtual_memory_max_bytes #gauge类型,可用虚拟内存的最大数量(以字节为单位) node_procs_blocked #gauge类型,等待I/O完成的已阻止进程数 node_procs_running #gauge类型,处于可运行状态的进程数
