open-falcon快速入门(二)
#学习新东西的时候最好先跟着官网文档走一下,这样能迅速的了解都有哪些功能。
一、快速入门
#这里主要根据官网的逻辑介绍走:https://book.open-falcon.org/zh_0_2/usage/getting-started.html
1.1 查看监控数据
agent只要部署到机器上,并且配置好了heartbeat和transfer就自动采集数据了,我们就可以去dashboard上面搜索监控数据查看了。dashboard是个web项目,浏览器访问。左侧输入endpoint搜索,endpoint是什么?应该用什么搜索?对于agent采集的数据,endpoint都是机器名,去目标机器上执行hostname,看到的输出就是endpoint,拿着hostname去搜索。
搜索到了吧?嗯,选中前面的复选框,点击“查看counter列表”,可以列出隶属于这个endpoint的counter,counter是什么?counter=${metric}/sorted(${tags})
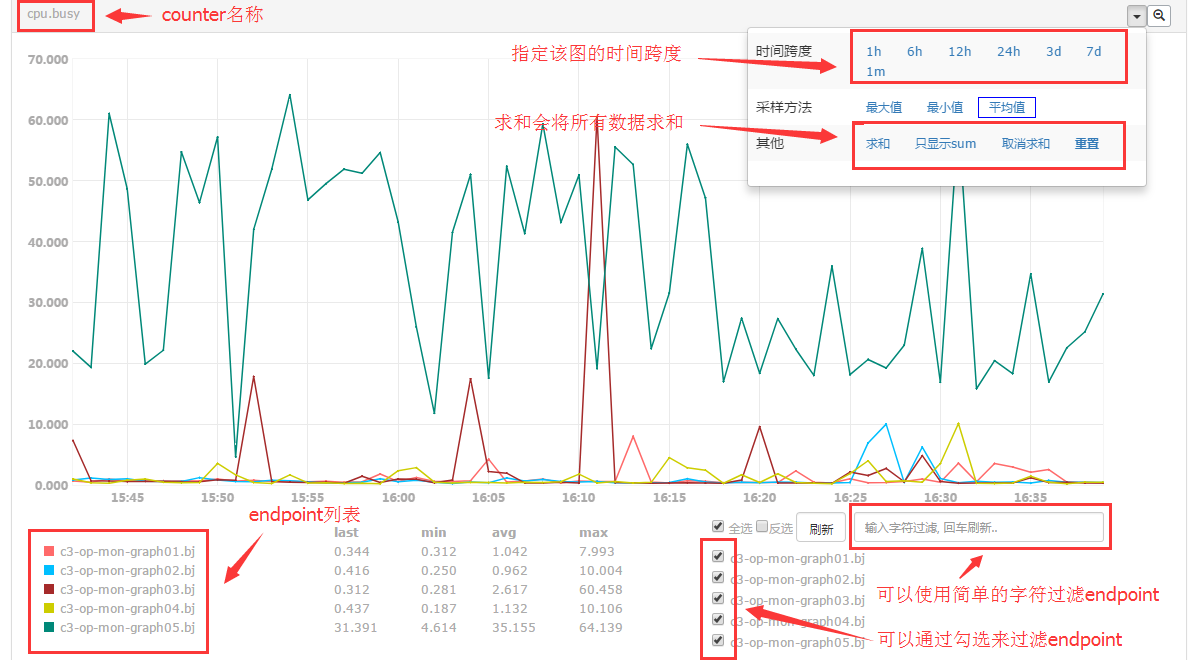
假如我们要查看cpu.busy,在counter搜索框中输入cpu并回车。看到cpu.busy了吧,点击,会看到一个新页面,图表中就是这个机器的cpu.busy的近一小时数据了,想看更长时间的?右上角有个小三角,展开菜单,可以选择更长的时间跨度
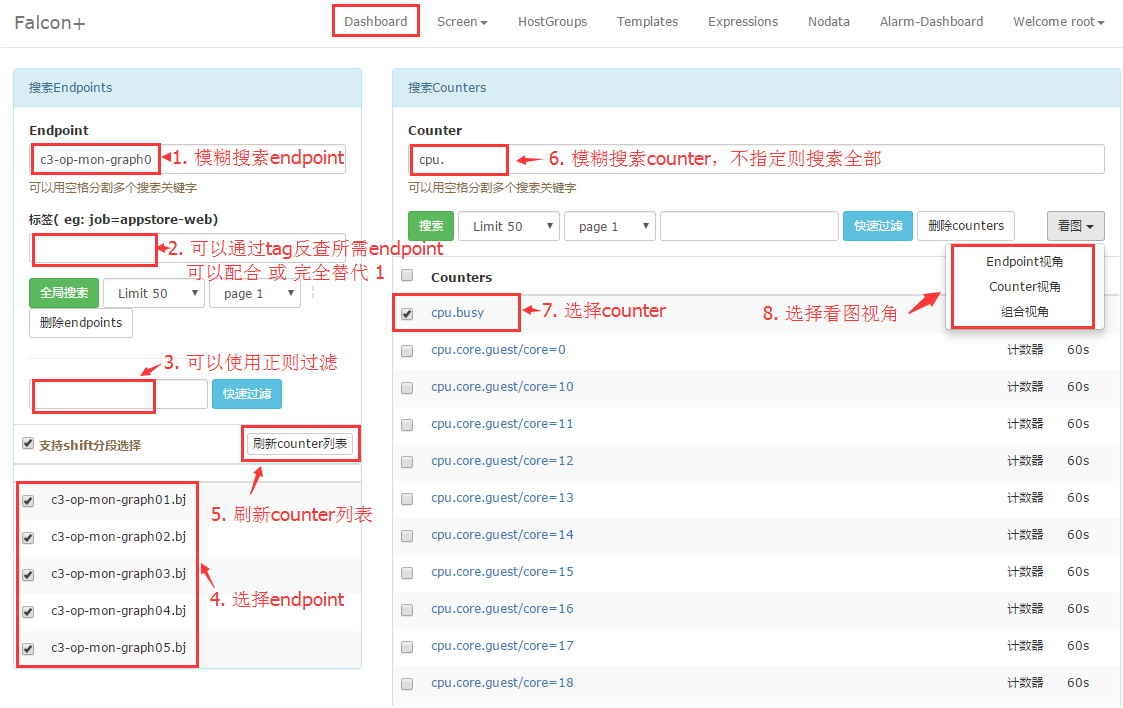
首先说Endpoints和Counter搜索:
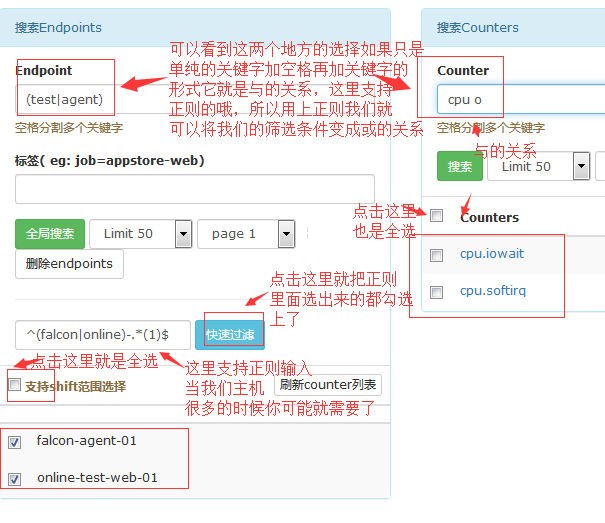
#上图很有意思,测试的时候主机少怎么都没事,但是生产环境主机很多的就需要用到正则了。
博文来自:www.51niux.com
再说看图:
#我们如何将我们选中的主机让其某个性能指标在一张图中或者让几个主机选中的性能指标在一个屏幕上面输出呢?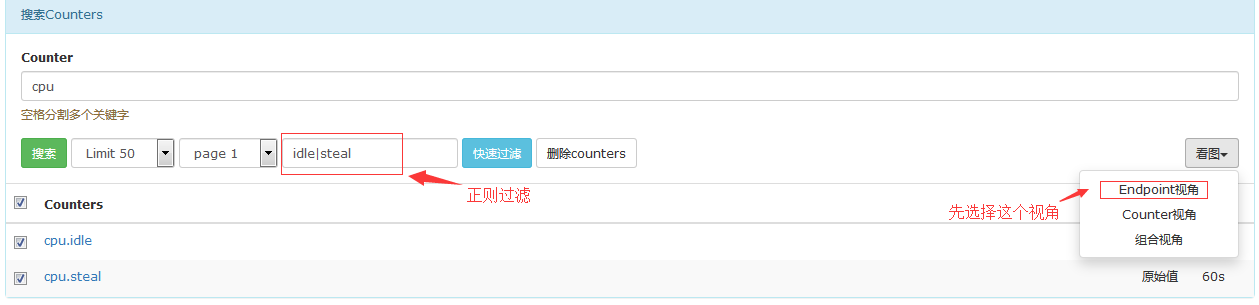
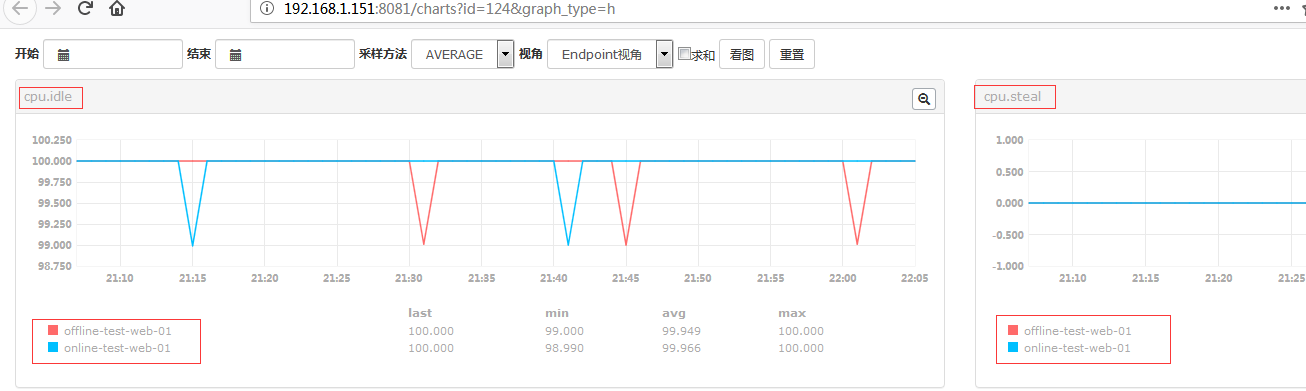
#上图就是Endpoint视角。
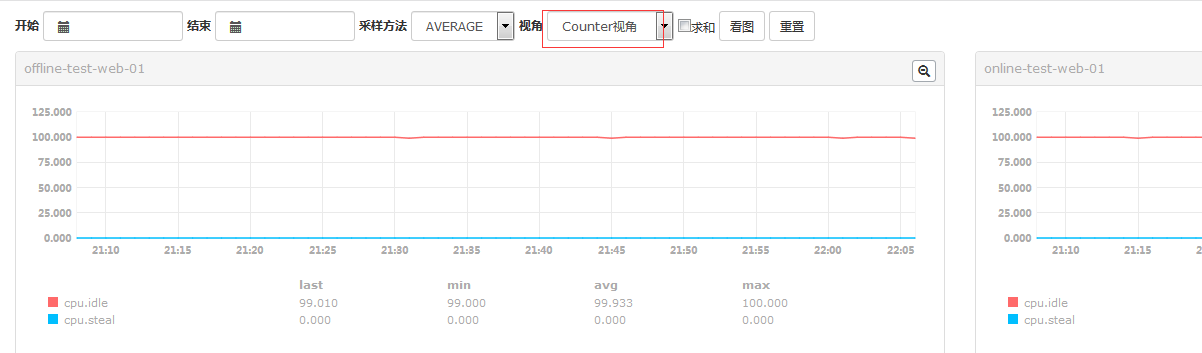
#上图是Counter视角。
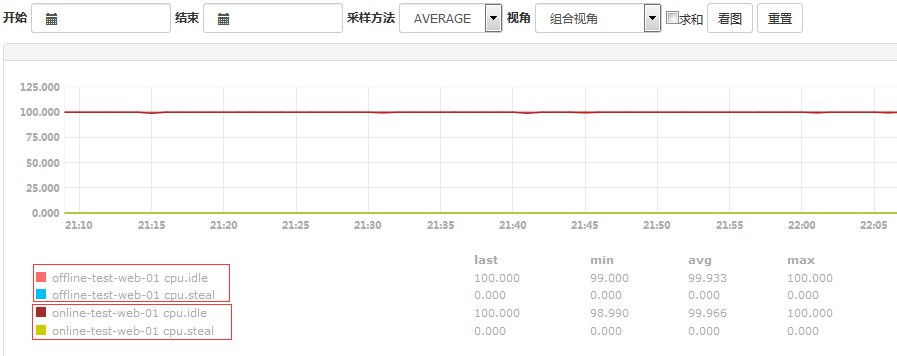
#上图是组合视角。当然上图中的求和也可以点击啊,就是让图中的值相加,采样方法那里还有一个MAX和MIN。
博文来自:www.51niux.com
1.2 如何配置报警策略
配置报警接收人:
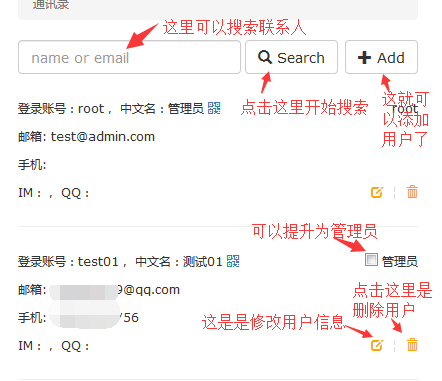
falcon的报警接收人不是一个具体的手机号,也不是一个具体的邮箱,因为手机号、邮箱都是容易发生变化的,如果变化了去修改所有相关配置那就太麻烦了。我们把用户的联系信息维护在一个叫 帐户/Profile 里,以后如果要修改手机号、邮箱,只要修改自己的帐户信息即可。报警接收人也不是单个的人,而是一个组(Teams),比如falcon这个系统的任何组件出问题了,都应该发报警给falcon的运维和开发人员,发给falcon这个团队,这样一来,新员工入职只要加入falcon这个Team即可;员工离职,只要从falcon这个Team删掉即可。
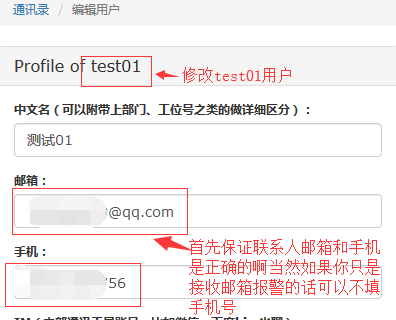
#首先进入通讯录修改帐户信息,保证邮箱和手机号正确:
#然后进入team进行报警组管理:
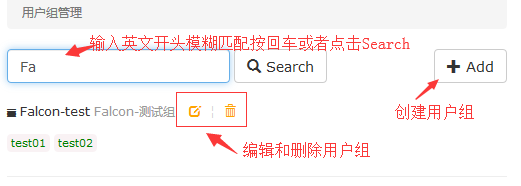
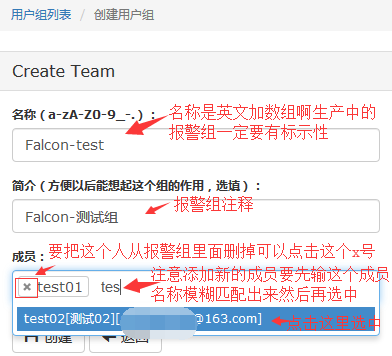
#用户创建完之后点击创建一个用户报警组就创建了。
博文来自:www.51niux.com
查看一下表的对应关系:
MariaDB [graph]> use uic; MariaDB [uic]> show tables; +---------------+ | Tables_in_uic | +---------------+ | rel_team_user | | session | | team | | user | +---------------+ MariaDB [uic]> select * from user;

#上面那个role给了管理员数字是1。
MariaDB [uic]> select * from team;
+----+--------------+------------------+---------+---------------------+
| id | name | resume | creator | created |
+----+--------------+------------------+---------+---------------------+
| 1 | Falcon-test | Falcon-测试组 | 1 | 2018-11-10 22:26:46 |
| 2 | Falcon-test2 | falcon-测试2 | 1 | 2018-11-10 22:37:05 |
+----+--------------+------------------+---------+---------------------+
MariaDB [uic]> select * from rel_team_user;
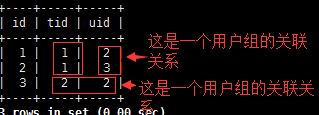
#tid就是用户组id,uid就是用户的id号,这就是用户组和用户之间的关联表。
创建HostGroup:
比如我们要对redis的端口进行监控,那首先创建一个HostGroup,把所有部署了redis的机器都塞进去,以后要扩容或下线机器的时候直接从这个HostGroup增删机器即可,报警策略会自动生效、失效。这个HostGroup取名为:Sales-Op-Redis,这个名称有讲究,sales是销售部门,OP是运维团队,Redis是服务名称。


在往组里加机器的时候如果报错,需要检查portal的数据库中host表,看里边是否有相关机器。那host表中的机器从哪里来呢?agent有个heartbeat(hbs)的配置,agent每分钟会发心跳给hbs,把自己的ip、hostname、agent version等信息告诉hbs,hbs负责写入host表。如果host表中没数据,需要检查这条链路是否通畅。
创建策略模板:
portal最上面有个Templates链接,这就是策略模板管理的入口。我们进去之后创建一个模板,名称姑且也叫:Sales-Op-Redis,与HostGroup名称相同,在里边配置一个端口监控,通常进程监控有两种手段,一个是进程本身是否存活,一个是端口是否在监听,此处我们使用端口监控。
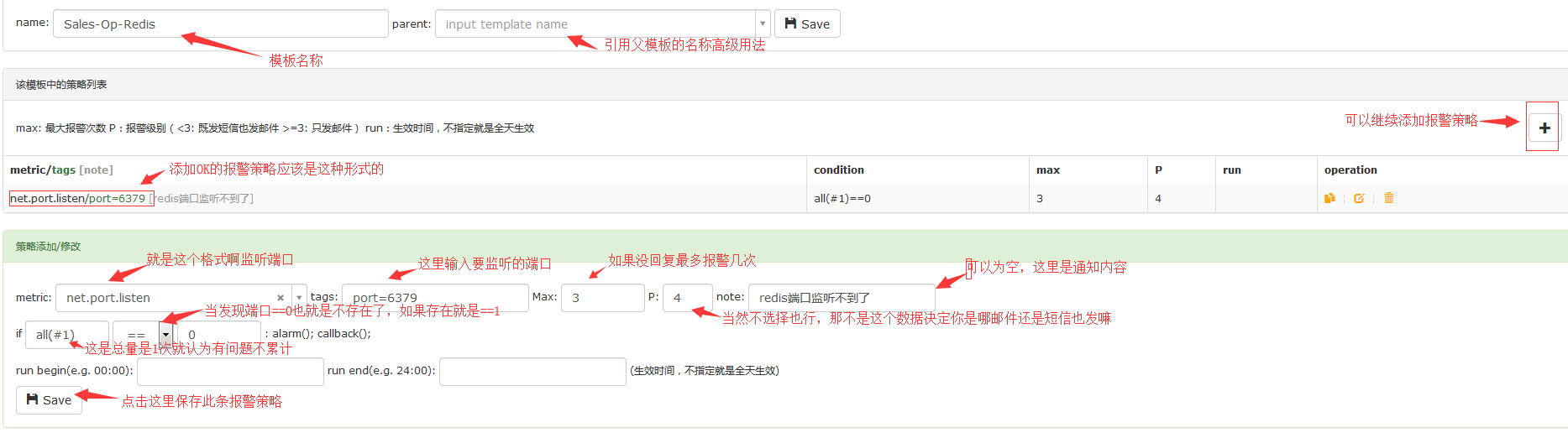
#将策略绑定到某个HostGroup,那么这个HostGroup下的机器就要去采集6379这个端口的情况了。这个信息是通过agent和hbs的心跳机制下发的。agent通过ss -tln拿到当前有哪些端口在监听,如果6379在监听,就设置value=1,汇报给transfer,如果发现6379没在监听,就设置value=0,汇报给transfer。
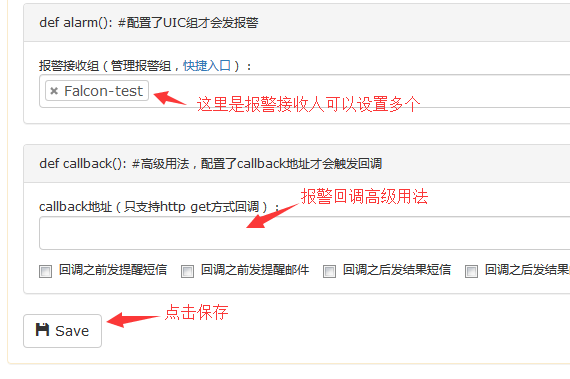
报警函数说明:
配置报警策略的时候open-falcon支持多种报警触发函数,比如all(#3) diff(#10)等等。 这些#后面的数字表示的是最新的历史点,比如#3代表的是最新的三个点。该数字默认不能大于10,大于10将当作10处理,即只计算最新10个点的值。
说明:#后面的数字的最大值,即在 judge 内存中保留最近几个点,是支持自定义的,具体参考 book 中描述(http://book.open-falcon.org/zh_0_2/distributed_install/judge.html) ; 源码位置 => cfg.example.json
all(#3): 最新的3个点都满足阈值条件则报警 max(#3): 对于最新的3个点,其最大值满足阈值条件则报警 min(#3): 对于最新的3个点,其最小值满足阈值条件则报警 sum(#3): 对于最新的3个点,其和满足阈值条件则报警 avg(#3): 对于最新的3个点,其平均值满足阈值条件则报警 diff(#3): 拿最新push上来的点(被减数),与历史最新的3个点(3个减数)相减,得到3个差,只要有一个差满足阈值条件则报警 pdiff(#3): 拿最新push上来的点,与历史最新的3个点相减,得到3个差,再将3个差值分别除以减数,得到3个商值,只要有一个商值满足阈值则报警 lookup(#2,3): 最新的3个点中有2个满足条件则报警; stddev(#7) = 3:离群点检测函数,取最新 **7** 个点的数据分别计算得到他们的标准差和均值,分别计为 σ 和 μ,其中当前值计为 X,那么当 X 落在区间 [μ-3σ, μ+3σ] 之外时,则认为当前值波动过大,触发报警;
更多请参考3-sigma算法:https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule。
将HostGroup与模板绑定:
一个模板是可以绑定到多个HostGroup的,现在我们重新回到HostGroups页面,找到Sales-Op-Redis这个HostGroup,右侧有几个超链接,点击【templates】进入一个新页面,输入模板名称,绑定一下就行了。


HostGroup添加主机:
#现在谁要进行6379的端口监控就加到这个HostGroup里面来就可以了。



#上图中什么情况会有报错提示呢,就是你所添加的主机已经存在这个HostGroup里面了就会有报错提示,提示你已经存在。
博文来自:www.51niux.com
1.3 open-falcon实现邮件报警
#上面已经把一个简单的端口报警设置完毕了,但是完事了吗,肯定没完事,现在还没有配置报警媒介并不能真正报警
安装mail-provider:
# cd $GOPATH/src
# cd github.com/open-falcon/
# git clone https://github.com/open-falcon/mail-provider.git
# cd mail-provider/
# go get ./...
# ./control build
# ./control pack
# mkdir /usr/local/open-falcon/mail-provider
# tar zxf falcon-mail-provider-0.0.1.tar.gz -C /usr/local/open-falcon/mail-provider/
# cd /usr/local/open-falcon/mail-provider/
# ls -lh
总用量 8.3M -rw-r--r-- 1 root root 264 11月 11 00:06 cfg.json -rwxr-xr-x 1 root root 2.1K 11月 10 23:38 control -rwxr-xr-x 1 root root 8.3M 11月 11 01:03 falcon-mail-provider
# vim cfg.json
{
"debug": true,
"http": {
"listen": "0.0.0.0:4000",
"token": ""
},
"smtp": {
"addr": "smtp.163.com:25",
"username": "51niux@163.com",
"password": "51niux",
"from": "51niux@163.com"
}
}#password那里是客户端授权码
# ./control start
# ps -ef|grep mail|grep -v grep
root 25746 1 0 01:06 pts/2 00:00:00 ./falcon-mail-provider -c cfg.json
# netstat -lntup|grep 4000
tcp6 0 0 :::4000 :::* LISTEN 25746/./falcon-mail
# curl http://127.0.0.1:4000/sender/mail -d "tos=51niux@51niux.com&subject=报警测试&content=这是一封测试邮件" #发送邮件测试一下

#如上图出现success就是表示验证成功了,如果没有问题你的指定邮箱肯定受到邮件了。
安装sender:
# cd $GOPATH/src
# cd github.com/open-falcon/
# git clone https://github.com/open-falcon/sender.git
# cd sender/
# go get ./...
# ./control build
# ./control pack
# mkdir /usr/local/open-falcon/sender
# tar zxf falcon-sender-0.0.0.tar.gz -C /usr/local/open-falcon/sender/
# cd /usr/local/open-falcon/sender/
# ls -lh
总用量 9.1M -rw-r--r-- 1 root root 426 11月 11 00:14 cfg.json -rwxr-xr-x 1 root root 2.0K 11月 11 00:08 control -rwxr-xr-x 1 root root 9.1M 11月 11 00:12 falcon-sender -rw-r--r-- 1 root root 8 11月 11 00:12 gitversion drwxr-xr-x 2 root root 36 11月 11 00:30 var
# vim cfg.json
{
"debug": true,
"http": {
"enabled": true,
"listen": "0.0.0.0:6066"
},
"redis": {
"addr": "127.0.0.1:6379",
"maxIdle": 5
},
"queue": {
"sms": "/sms",
"mail": "/mail"
},
"worker": {
"sms": 10,
"mail": 50
},
"api": {
"sms": "http://11.11.11.11:8000/sms",
"mail": "http://127.0.0.1:4000/sender/mail"
}
}#就是将mail那里修改成http://127.0.0.1:4000/sender/mail
# ./control start
# ps -ef|grep sender
root 26448 1 7 01:19 pts/2 00:00:00 ./falcon-sender -c cfg.json
# netstat -lntup|grep send
tcp6 0 0 :::6066 :::* LISTEN 26448/./falcon-send
测试一下:
现在停掉一台机器的redis服务。

# tail -20 var/app.log #可以查看下日志可以看到提示邮件已经发出去了
2018/11/11 00:45:37 mail.go:50: ==mail==>>>> <Tos:51niux@51niux.com, Subject:[P4][PROBLEM][online-test-web-01][][redis端口监听不到了 all(#1) net.port.listen port=6379 0==0][O3 2018-11-11 00:44:00], Content:PROBLEM P4 Endpoint:online-test-web-01 Metric:net.port.listen Tags:port=6379 all(#1): 0==0 Note:redis端口监听不到了 Max:3, Current:3 Timestamp:2018-11-11 00:44:00 http://127.0.0.1:8081/portal/template/view/1 > 2018/11/11 00:45:37 mail.go:51: <<<<==mail== success
邮件查看:

# vim /usr/local/open-falcon/judge/config/cfg.json #配置文件中配置了连续两个报警之间至少相隔的秒数
"minInterval": 300,
二、Nodata配置
2.1 配置Nodata
使用Nodata,需要进行两个配置: Nodata配置 和 策略配置。下面,我们以一个例子,讲述如何使用Nodata提供的服务。
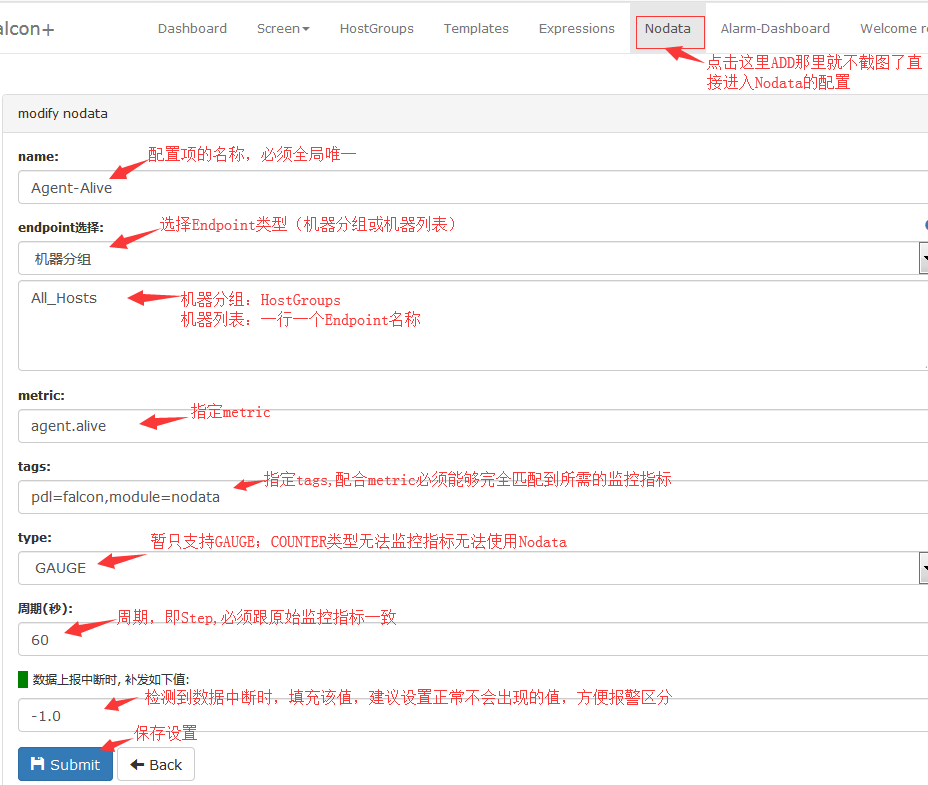
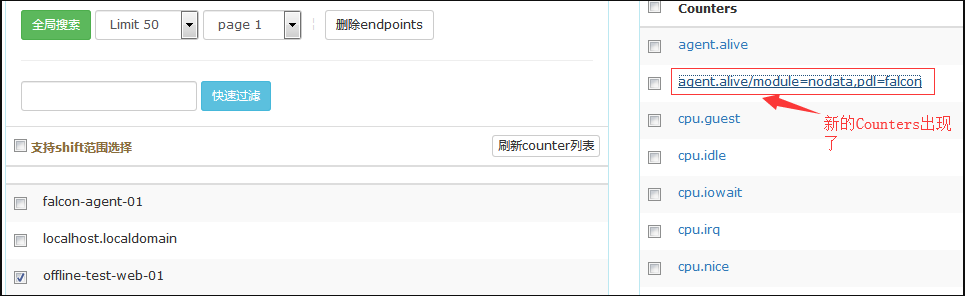
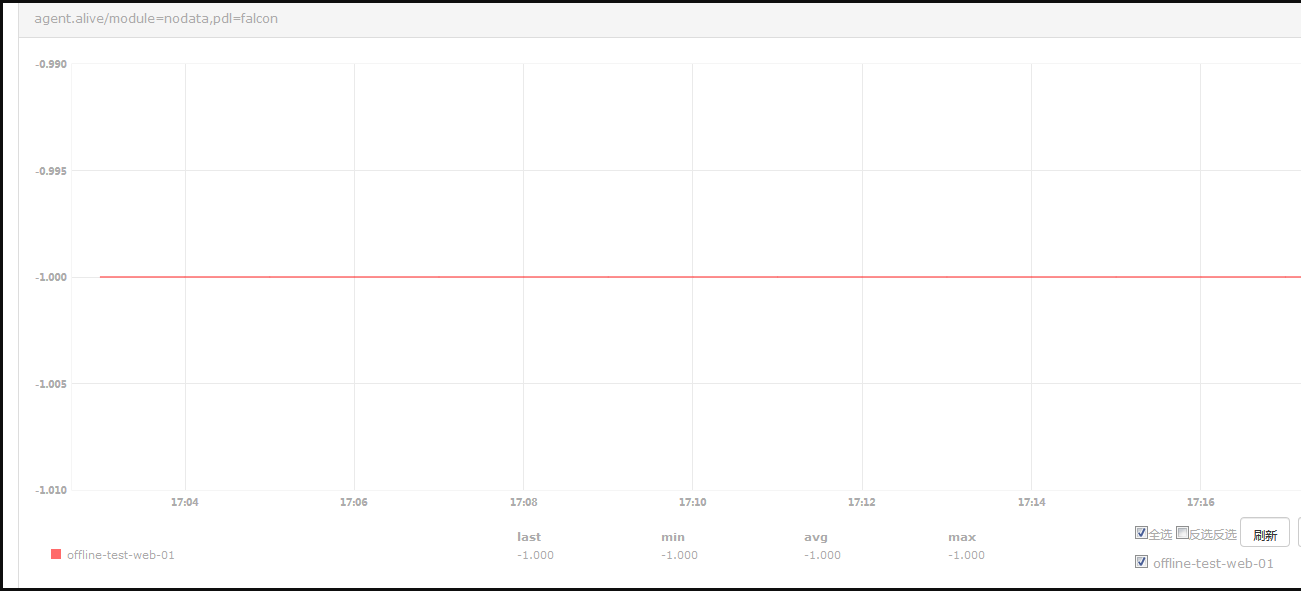
#从上图看-1,以后成功了,其实并木有,因为你会发现不管关闭agent和开启agent都始终是-1.
解决agent.alive/pdl=falcon,module=nodata一直为-1的问题:
# ./open-falcon monitor nodata #查看了nodata的日志
2018/11/11 17:32:00 judge_cron.go:43: judge cron, time 0s, start 2018-11-11 17:32:00 2018/11/11 17:32:00 collector_cron.go:99: fetchItemAndStore keys:[online-test-web-02/agent.alive/module=nodata,pdl=falcon offline-test-web-01/agent.alive/module=nodata,pdl=falcon online-test-web-01/agent.alive/module=nodata,pdl=falcon], key_size:3, ret_size:3 2018/11/11 17:32:00 collector_cron.go:45: collect cron, cnt 3, time 0s, start 2018-11-11 17:32:00 2018/11/11 17:3bsp;time 0s, start 2018-11-11 17:32:00 2018/11/11 17:32:00 sender.go:107: send items: [<JsonMetaData Endpoint:online-test-web-02, Metric:agent.alive, Tags:module=nodata,pdl=falcon, DsType:GAUGE, Step:60, Value:-1, Timestamp:1541928600> <JsonMetaData Endpoint:offline-test-web-01, Metric:agent.alive, Tags:module=nodata,pdl=falcon, DsType:GAUGE, Step:60, Value:-1, Timestamp:1541928600> <JsonMetaData Endpoint:online-test-web-01, Metric:agent.alive, Tags:module=nodata,pdl=falcon, DsType:GAUGE, Step:60, Value:-1, Timestamp:1541928600>] 2018/11/11 17:32:00 sender.go:63: sender cron, cnt 3, time 0s, start 2018-11-11 17:32:00 2018/11/11 17:32:20 collector_cron.go:99: fetchItemAndStore keys:[online-test-web-02/agent.alive/module=nodata,pdl=falcon offline-test-web-01/agent.alive/module=nodata,pdl=falcon online-test-web-01/agent.alive/module=nodata,pdl=falcon], key_size:3, ret_size:3 2018/11/11 17:32:20 collector_cron.go:45: collect cron, cnt 3, time 0s, start 2018-11-11 17:32:20
这里官方教程有一点误导人,如果在你没有对agent做什么tag设置的情况下,监控原生的那个agent.alive,他是没有标签的,所以nodata那里配置不应该打上tag.当我们按照官方教程上那么设置tag之后,nodata就会去监控agent.alive/module=nodata,pdl=falcon这一项,这一Counter本来就没有数据,是nodata自己创建的。所以nodata每次都去获取agent.alive/module=nodata,pdl=falcon这项数据,发现为空,补为-1,所以这一项肯定是永远为-1的。
下面重新修改一下Nodata的配置:
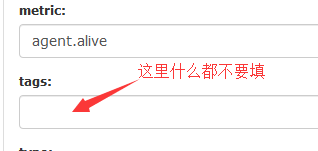
查看一下agent.alive这个metric的图形:
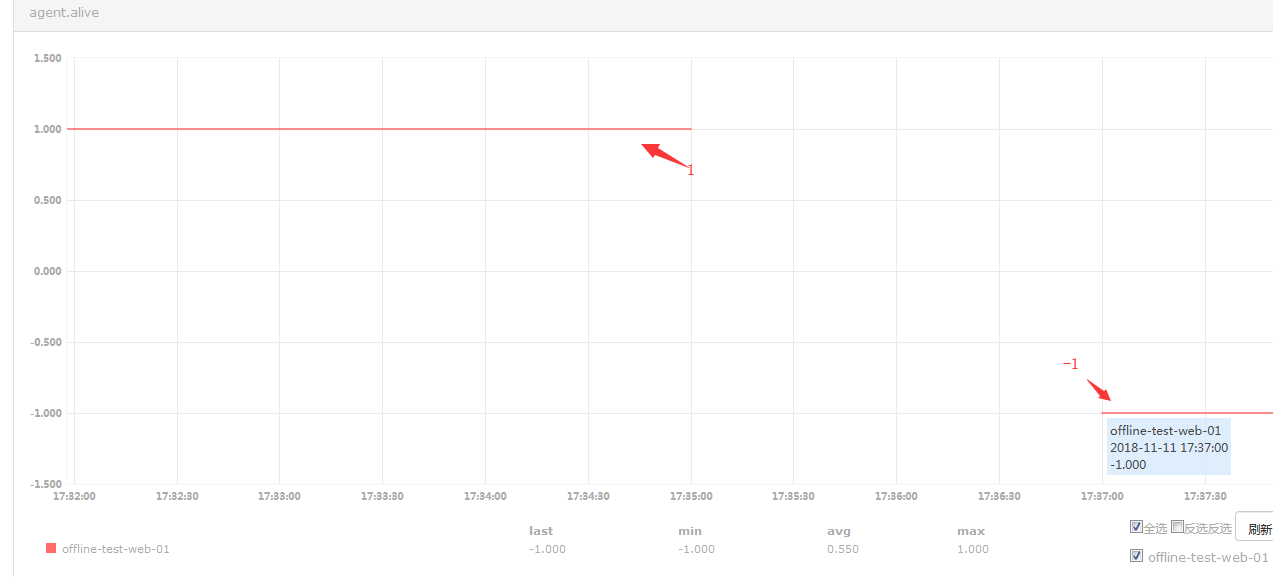
#这样agent存活或者正常就会有数据上报value就是1,如果异常就不会是空值而造成无法跟0匹配大小,异常就是-1了。
2.2 Templates设置
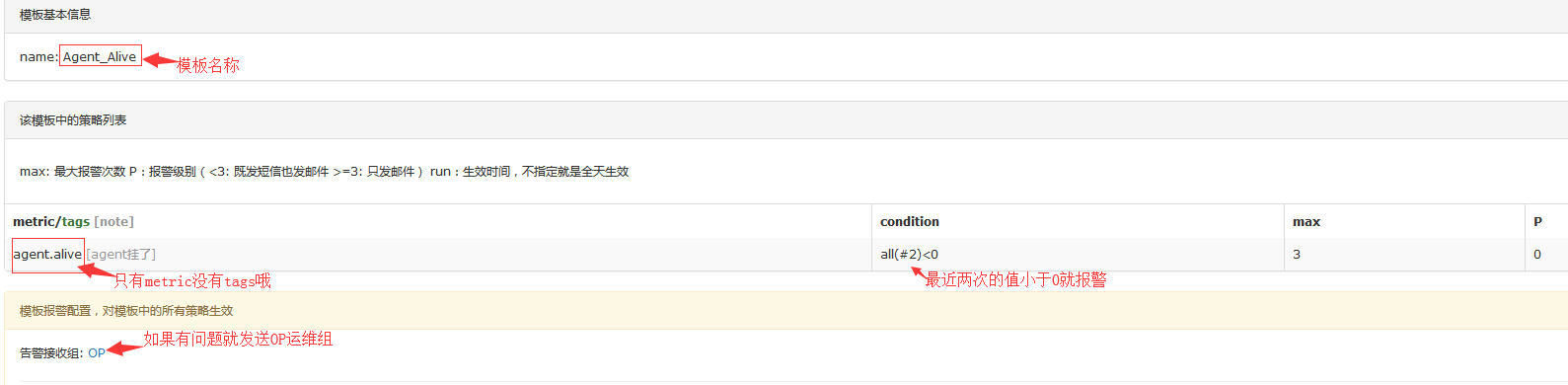
2.3 HostGroups设置
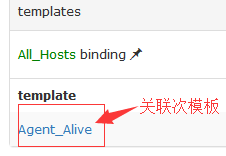
#这样只要是All_Hosts里面的主机都可以用这个客户端宕机报警功能了。

#通过关闭agent客户端再启动agent客户端,可以看到报警和恢复邮件都有了。
