ELK高级补充(十六)
#这里也不知道标题怎么写,主要是对前面的一个梳理外加整体流程的一个补充吧。
一、还是跟着官网补充几个插件
1.1 mutate filter plugin插件
官网链接:https://www.elastic.co/guide/en/logstash/current/plugins-filters-mutate.html
mutate筛选器允许您在字段上执行常规突变。 您可以重命名,删除,替换和修改事件中的字段。下面是mutate过滤器配置选项:
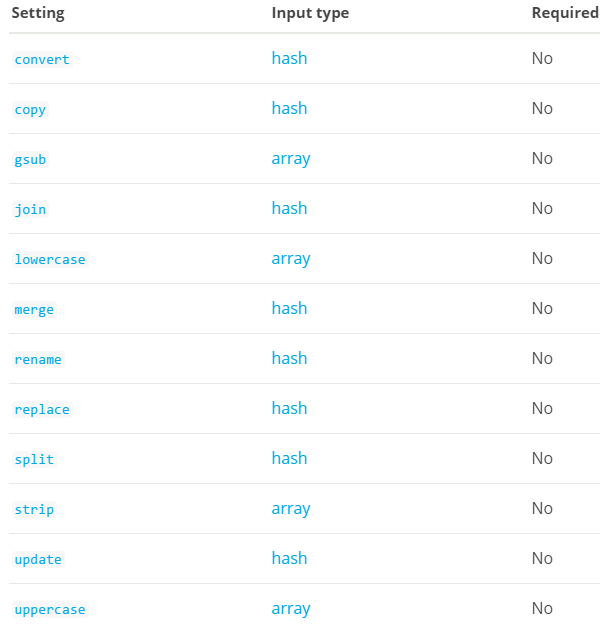
convert :
值类型是hash,这个设置没有默认值。将字段的值转换为不同的类型,如将字符串转换为整数。 如果字段值是一个数组,所有的成员将被转换。如果该字段是散列,则不会采取任何行动。如果转换类型是布尔值,那么可接受的值是:
True: true, t, yes, y, and 1 False: false, f, no, n, and 0
如果提供了这些值以外的值,则会直接通过并记录警告消息。如果转换类型是整数,值是一个布尔值,它将被转换为:* True: 1 * False: 0。
有效的转换目标是:整数,浮点数,字符串和布尔值。例:
filter {
mutate {
convert => { "fieldname" => "integer" }
}
}copy:
值类型是hash,这个设置没有默认值。将现有字段复制到另一个字段。 现有的目标字段将被覆盖。例:
filter {
mutate {
copy => { "source_field" => "dest_field" }
}
}gsub :
值类型是数组,这个设置没有默认值。匹配字段值的正则表达式,并用替换字符串替换所有匹配。 仅支持字符串或字符串数组的字段。 对于其他类型的领域,不会采取任何行动。这个配置需要一个由每个字段/替换3个元素组成的数组。注意在配置文件中转义任何反斜杠。例:
filter {
mutate {
gsub => [
# replace all forward slashes with underscore
"fieldname", "/", "_",
# replace backslashes, question marks, hashes, and minuses
# with a dot "."
"fieldname2", "[\\?#-]", "."
]
}
}join :
值类型是hash,这个设置没有默认值。加入一个分隔符的数组。 对非数组字段没有任何作用。例:
filter {
mutate {
join => { "fieldname" => "," }
}
}lowercase :
值类型是array,这个设置没有默认值。将字符串转换为小写的等价物。例:
filter {
mutate {
lowercase => [ "fieldname" ]
}
}merge:
值类型是hash,这个设置没有默认值。合并数组或哈希的两个字段。字符串字段将被自动转换为数组,所以:
`array` + `string` will work `string` + `string` will result in an 2 entry array in `dest_field` `array` and `hash` will not work
例:
filter {
mutate {
merge => { "dest_field" => "added_field" }
}
}rename :
值类型是hash,这个设置没有默认值。重命名一个或多个字段。例:
filter {
mutate {
# Renames the 'HOSTORIP' field to 'client_ip'
rename => { "HOSTORIP" => "client_ip" }
}
}replace:
值类型是hash,这个设置没有默认值。用新值替换一个字段。 新值可以包含%{foo}字符串,以帮助您从事件的其他部分构建新值。例如:
filter {
mutate {
replace => { "message" => "%{source_host}: My new message" }
}
}split:
值类型是hash,这个设置没有默认值。使用分隔符将字段拆分为数组。 只适用于字符串字段。例:
filter {
mutate {
split => { "fieldname" => "," }
}
}strip :
值类型是数组,这个设置没有默认值。从filed剥离空白。 注意:这只适用于前导和尾随的空白。例:
filter {
mutate {
strip => ["field1", "field2"]
}
}update :
值类型是hash,这个设置没有默认值。使用新值更新现有字段。 如果该字段不存在,则不采取任何行动。例:
filter {
mutate {
update => { "sample" => "My new message" }
}
}uppercase :
值类型是数组,这个设置没有默认值。将字符串转换为大写字母。例:
filter {
mutate {
uppercase => [ "fieldname" ]
}
}#常规选项还是哪些就不截图了。
1.2 Urldecode filter plugin
urldecode过滤器用于解码urlencoded的字段。该插件支持以下配置选项和稍后介绍的通用选项。
all_fields:
值类型是布尔值,默认值是false。对所有字段进行Url解码。
charset :
值可以是以下任何一个:
ASCII-8BIT, UTF-8, US-ASCII, Big5, Big5-HKSCS, Big5-UAO, CP949, Emacs-Mule, EUC-JP, EUC-KR, EUC-TW, GB2312, GB18030, GBK, ISO-8859-1, ISO-8859-2, ISO-8859-3,ISO-8859-4, ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-10, ISO-8859-11, ISO-8859-13, ISO-8859-14, ISO-8859-15, ISO-8859-16, KOI8-R, KOI8-U, Shift_JIS,UTF-16BE, UTF-16LE, UTF-32BE, UTF-32LE, Windows-31J, Windows-1250, Windows-1251, Windows-1252, IBM437, IBM737, IBM775, CP850, IBM852, CP852, IBM855, CP855, IBM857, IBM860, IBM861,IBM862, IBM863, IBM864, IBM865, IBM866, IBM869, Windows-1258, GB1988, macCentEuro,macCroatian, macCyrillic, macGreek, macIceland, macRoman, macRomania, macThai,macTurkish, macUkraine, CP950, CP951, IBM037, stateless-ISO-2022-JP, eucJP-ms, CP51932,EUC-JIS-2004, GB12345, ISO-2022-JP, ISO-2022-JP-2, CP50220, CP50221, Windows-1256,Windows-1253, Windows-1255, Windows-1254, TIS-620, Windows-874, Windows-1257, MacJapanese, UTF-7, UTF8-MAC, UTF-16, UTF-32, UTF8-DoCoMo, SJIS-DoCoMo, UTF8-KDDI, SJIS-KDDI, ISO-2022-JP-KDDI, stateless-ISO-2022-JP-KDDI, UTF8-SoftBank, SJIS-SoftBank, BINARY,CP437, CP737, CP775, IBM850, CP857, CP860, CP861, CP862, CP863, CP864, CP865, CP866, CP869,CP1258, Big5-HKSCS:2008, ebcdic-cp-us, eucJP, euc-jp-ms, EUC-JISX0213, eucKR, eucTW, EUC-CN, eucCN, CP936, ISO2022-JP, ISO2022-JP2, ISO8859-1, ISO8859-2, ISO8859-3, ISO8859-4,ISO8859-5, ISO8859-6, CP1256, ISO8859-7, CP1253, ISO8859-8, CP1255, ISO8859-9, CP1254,ISO8859-10, ISO8859-11, CP874, ISO8859-13, CP1257, ISO8859-14, ISO8859-15, ISO8859-16,CP878, MacJapan, ASCII, ANSI_X3.4-1968, 646, CP65000, CP65001, UTF-8-MAC, UTF-8-HFS, UCS-2BE, UCS-4BE, UCS-4LE, CP932, csWindows31J, SJIS, PCK, CP1250, CP1251, CP1252, external,locale
默认值是“UTF-8"。该过滤器中使用的字符编码。 例子包括UTF-8和cp1252如果您的url解码的字符串是Latin-1(又名cp1252)或UTF-8以外的其他字符集,则此设置很有用。
field:
值类型是字符串,默认值是“message”。值是urldecoded的字段
tag_on_failure :
值类型是数组,默认值是[“_urldecodefailure”]。当抛出异常时,将值追加到tags字段
1.3 Ruby filter plugin
官网链接:https://www.elastic.co/guide/en/logstash/current/plugins-filters-ruby.html
执行ruby代码。 这个过滤器接受内联ruby代码或ruby文件。 这两个选项是相互排斥的,而且工作方式略有不同,下面将对此进行介绍。
Inline ruby code :
要在过滤器中内联ruby,请将所有代码放在code选项中。该代码将针对过滤器收到的每个事件执行。 你也可以把ruby代码放在init选项中 - 在插件的注册阶段,它只会被执行一次。例如,要取消90%的事件,可以这样做:
filter {
ruby {
# Cancel 90% of events
code => "event.cancel if rand <= 0.90"
}
}如果您需要创建其他事件,则必须使用特定语法new_event_block.call(event),如本例中的复制输入事件
filter {
ruby {
code => "new_event_block.call(event.clone)"
}
}使用Ruby脚本文件:
由于内联代码可能变得复杂并且难以在code中的文本字符串内部进行构造,因此最好使用path选项将Ruby代码置于.rb文件中。
filter {
ruby {
# Cancel 90% of events
path => "/etc/logstash/drop_percentage.rb"
script_params => { "percentage" => 0.9 }
}
}ruby脚本文件应该定义下列方法:
register(params):一个可选的注册方法,它接收script_params配置选项中传递的键/值散列值 filter(event) : 接受Logstash事件的强制性Ruby方法,必须返回一组事件
下面是drop_percentage.rb ruby脚本的一个示例实现,用于删除可配置的事件百分比:
# the value of `params` is the value of the hash passed to `script_params` # in the logstash configuration def register(params) @drop_percentage = params["percentage"] end # the filter method receives an event and must return a list of events. # Dropping an event means not including it in the return array, # while creating new ones only requires you to add a new instance of # LogStash::Event to the returned array def filter(event) if rand >= @drop_percentage return [event] else return [] # return empty array to cancel event end end
测试ruby脚本:
为了验证实现的过滤器方法的行为,Ruby过滤器插件提供了一个内联测试框架,可以在其中声明期望值。定义的测试将在创建管道时运行,并在测试失败时阻止它启动。还可以使用logstash -t标志验证测试是否通过。比如上面的例子,可以在drop_percentage.rb ruby脚本的底部写下如下的测试:
def register(params)
# ..
end
def filter(event)
# ..
end
test "drop percentage 100%" do
parameters do
{ "percentage" => 1 }
end
in_event { { "message" => "hello" } }
expect("drops the event") do |events|
events.size == 0
end
end我们现在可以测试我们正在使用的ruby脚本是否正确实现:
% bin/logstash -e "filter { ruby { path => '/etc/logstash/drop_percentage.rb' script_params => { 'drop_percentage' => 0.5 } } }" -t
[2017-10-13T13:44:29,723][INFO ][logstash.filters.ruby.script] Test run complete {:script_path=>"/etc/logstash/drop_percentage.rb", :results=>{:passed=>1, :failed=>0, :errored=>0}}
Configuration OK
[2017-10-13T13:44:29,887][INFO ][logstash.runner ] Using config.test_and_exit mode. Config Validation Result: OK. Exiting LogstashRuby过滤器配置选项:

code:
值类型是字符串,这个设置没有默认值。此设置不能与路径一起使用。
为每个事件执行的代码。 你将有一个事件变量可用,这是事件本身。 有关更多信息,请参阅Event API(https://www.elastic.co/guide/en/logstash/current/event-api.html)。
init :
值类型是字符串,这个设置没有默认值。在logstash启动时执行的任何代码。
path:
值类型是字符串,这个设置没有默认值。此设置不能与代码一起使用。实现filter方法的ruby脚本文件的路径。
script_params:
值类型是散列,默认值是{}。一个 key/value散列,参数被传递给路径中定义的Ruby脚本文件的注册方法。
tag_on_exception:
值类型是字符串,默认值是_rubyexception。添加到事件的标记,以防止ruby代码(内联或基于文件)导致异常。
1.4 Split filter plugin
官网链接:https://www.elastic.co/guide/en/logstash/current/plugins-filters-split.html
拆分过滤器通过拆分其中一个字段来克隆事件,并将拆分后的每个值放入原始事件的克隆中。 被分割的字段可以是字符串或数组。这个过滤器的一个用例是从exec input plugin(https://www.elastic.co/guide/en/logstash/current/plugins-inputs-exec.html)获取输出,这个插件为一个命令的整个输出发出一个事件,并用newline分隔输出 -----使每一行成为一个事件。
拆分过滤器也可用于将事件中的数组字段拆分为单个事件。 JSON和XML中一个非常常见的模式是利用列表将数据分组在一起。例如,像这样的json结构:
{ field1: ...,
results: [
{ result ... },
{ result ... },
{ result ... },
...
] }可以在上述数据上使用拆分过滤器为结果字段的每个值创建单独的事件
filter {
split {
field => "results"
}
}每个拆分的最终结果是事件的完整副本,只更改给定字段的当前拆分部分。
拆分过滤器配置选项:
该插件支持以下配置选项和稍后介绍的通用选项。
field :
值类型是字符串,默认值是“message"。值由终止符分割的字段。 可以是多行消息或数组的ID。 嵌套数组的引用如下所示:"[object_id][array_id]"
target:
值类型是字符串,此设置没有默认值。新事件中值被分割的字段。如果未设置,则目标字段默认为拆分字段名称。
terminator :
值类型是字符串,默认值是“\ n”。要分割的字符串。 这通常是一个行终止符,但可以是任何字符串。如果要将JSON数组分成多个事件,则可以忽略此字段。
博文来自:www.51niux.com
二、再说nginx日志采集
2.1 被采集日志客户端的设置
nginx日志的设置:
如果是nginx后端的设置:
log_format log_main_json
'{"timestamp":"$time_iso8601",'
'"request_addr":"$remote_addr",'
'"request_domain":"$server_name",'
'"request_uri":"$document_uri",'
'"request_url":"$request_uri",'
'"request_method":"$request_method",'
'"request_protocol":"$server_protocol",'
'"request_length": $request_length,'
'"response_status": $status,'
'"response_size": $body_bytes_sent,'
'"response_time": $request_time,'
'"request_user_agent":"$http_user_agent",'
'}';
access_log logs/access.json.log log_main_json;如果是nginx前端的设置:
log_format log_vvlive_json
'{"timestamp":"$time_iso8601",'
'"request_addr":"$remote_addr",'
'"request_domain":"$server_name",'
'"request_uri":"$document_uri",'
'"request_url":"$request_uri",'
'"request_method":"$request_method",'
'"request_protocol":"$server_protocol",'
'"request_length": $request_length,'
'"response_status": $status,'
'"response_size": $body_bytes_sent,'
'"response_time": $request_time,'
'"upstream_addr":"$upstream_addr",'
'"upstream_status":"$upstream_status",'
'"upstream_size":"$upstream_response_length",'
'"upstream_response_time":"$upstream_response_time",'
'"request_user_agent":"$http_user_agent",'
'}';#当然你可能自己的app也会采集一些信息,那么就是自定义字段了,比如:
'"http_token":"$http_token",' '"cookie_token":"$cookie_token",'
#上面是一个相对来说还算标准的线上nginx日志的json格式,request开头的呢就是客户端的请求信息,response开头的呢就是此服务器返回给客户端的一些信息,upstream开头的呢就是后端返回给本服务器的一些信息,然后自定义的一些信息呢可以照着上面这个意思继续往下写,然后呢就是重点是测试好日志输出是json格式,然后就是"timestamp":"$time_iso8601",这样是为了方便logstash来实现timestamp替换。注意我例如$response_size没有用""包起来那么它的类型就不是str而是一个int,也就是是数字为了方便数字排序。
filebeat的设置:
#跟前面设置一样,没什么差别,就是简单阐述一下。
#首先你可能得想如果nginx日志切割了,那么filebeat采集怎么处理,前面翻译官网的时候已经记录了,filebeat并非是根据文件名称来采集的,而是根据文件的inode号来采集的,所以如果你nginx轮询切割了,filebeat呢会继续连接一段时间然后多长时间以后日志文件不再变动了就会将旧的日志释放不再占用了。旧版本还有两个参数来设置这个文件关闭时间什么的,但是新版本已经废弃了我就不记录了。当然如果es写入性能有问题你会导致filebeat有很多信息无法写入es中结果导致filebeat还继续占用轮询切割的旧日志导致你系统空间不足。
#然后就是想在这里记录一下旧版filebeat和新版filebeat的一个显著区别,当然还有很多区别。
如果是filebeat-5系列的客户端:
#cat data/registry |grep -o "2018"|wc -l
42
如果是filebeat-6系列的客户端:
#cat data/registry
[{"source":"/usr/local/nginx/logs/access.json.log","offset":1178725046,"timestamp":"2018-02-27T11:19:44.481513711+08:00","ttl":-1,"type":"log","FileStateOS":{"inode":786236,"device":64768}}]#阐述一下啥意思,就是旧版的filebeat就算你旧的日志关闭了,不在从日志里面采集日志了,依旧会在registry里面记录,但是如果新版呢旧日志关闭了不再采集了就不记录了,就只记录当前采集的日志文件信息。
#注意filebeat7系列字段发生了很大的变化:https://www.elastic.co/guide/en/beats/libbeat/7.2/breaking-changes-7.0.html
2.2 logstash的设置
input {
beats {
host => "192.168.14.49"
port => 5066
codec => "json"
}
}
filter {
date {
match => ["timestamp", "ISO8601"]
}
if "-" == [upstream_response_time] {
mutate {
remove_field => [upstream_response_time]
}
} else {
mutate {
convert => { "upstream_response_time" => "float"}
}
}
if "-" == [upstream_size] {
mutate {
remove_field => [upstream_size]
}
} else {
mutate {
convert => { "upstream_size" => "integer"}
}
}
}#上面只是部分配置,output那里就不写了。可以看到timestamp替换掉了,然后又几个转换,就是因为nginx作为负载均衡器嘛,并不是所有的操作都会有upstream,所以upstream_size这些可能就不是int型而是-,而-并非int型,那么这段日志格式就不是json格式了,也就不能往es里面插了,所以要判断一下,当然很多细节都是生产中测试改进的。
2.3 elasticsearch
#前面的设置不变,就是记录两个问题。
#首先第一个问题呢,打个比方说如果你的es版本是2版本的,就要用对应版本的kibana,如果比如想用6版本的kibana是不行的会提示你版本不匹配,所以也就是说升级是挺麻烦的,对应的组件都要升级除了filebeat。
#第二个问题呢就是es的索引写入问题,当然一开始你的配置可能想其他分布式存储的配置一样,一个机器上面多盘的形式:
path.data: /data1/es/data,/data2/es/data,/data3/es/data,/data4/es/data,/data5/es/data,/data6/es/data
#这种单盘的形式呢在es的2系列版本中存在一个问题,就是集中某块盘写入问题,就是因为是索引会分成几个分片落在某几块盘上,但是这个落盘你是不能控制的,这就可能会造成某个时间段某个索引的写入非常大,然后你就看到12块盘只有两三块盘写非常猛然后另外N块盘静静的在那看着,因为它们上面的索引分片写入不猛啊,这就造成了写入不均衡的问题。所以可以采取几块盘做成一个raid0卷组,一个多盘的机器存在几个三四个raid0卷组的形式,这样可以缓解写入不均衡的问题。当然如果日志量不大又可以定时清理旧索引的话,可以用1U机器节点等等,还是根据实际情况来,监控做好。
再考虑增加硬盘的问题:
#可以再es服务启动状态,比如原来是path.data: /data1/es/data然后变成了path.data: /data1/es/data,/data2/es/data,然后再不重启服务的情况下可以看到数据还是在原来的磁盘上面写,新加的硬盘是不会写的,所以要重启es服务,这样新添加的硬盘才会被es识别到。
博文来自:www.51niux.com
三、再说kibana搜索框
3.1 过滤条件保存
创建搜索条件:
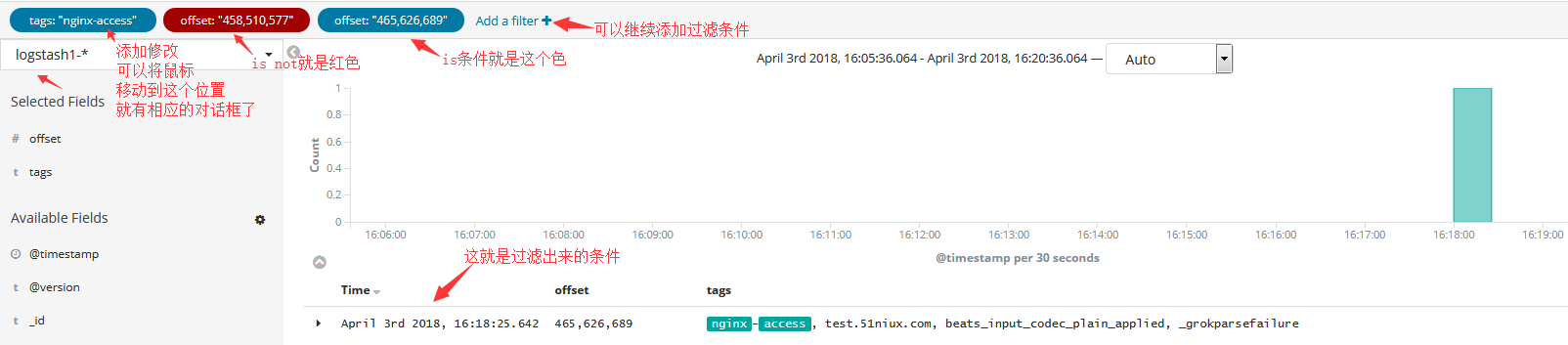
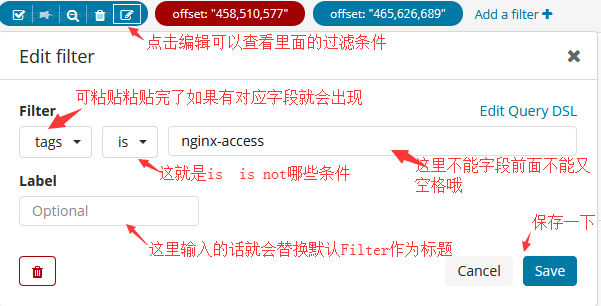
查看搜索条件:

#这样就可以进入到我们刚才设置的搜索条件,这也是生产中经常会用到的,因为你不能每次访问都写你的匹配条件。
#不过在kibana旧版本里面没有这种方式,还是要用传统的筛选框的方式,如下图:

3.2 kibana做一个曲线
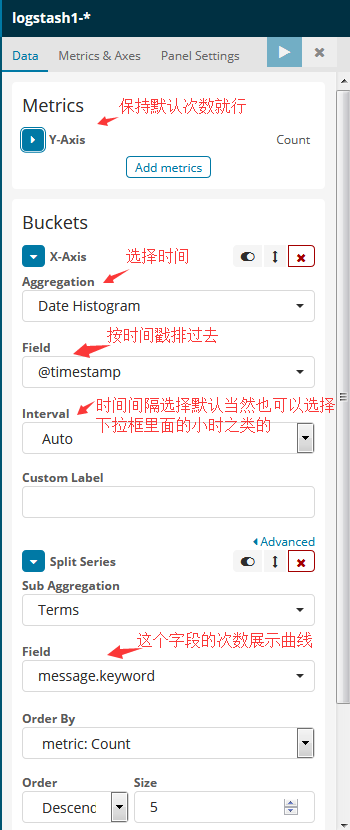

博文来自:www.51niux.com
四、再说Logstash采集
3.1 Logstash重新采集的问题
#首先我们要知道logstash跟filebeat的采集起始点是不一样的,filebeat是从一个文件的起始部分开始采集的,但是logstash不是,logstash是从文件的最新写入开始采集的,这一点跟阿里云的iotail客户端一样。
#还有一点也要了解,当启动logstash input插件的时候和filebeat都有偏移量记录的,所以logstash采集过的日志就算重新启动也是不会再重复采集的(不过据说是貌日志采集完之后才会记录偏移量)。那么是记录在哪呢,我记得旧版貌似是记录在运行目录的家目录下面,新版的是记录在logstash目录下的data/plugins/inputs/file下的.sincedb_(类似于md5值的一串字符串)。
#好了回到正题,有的时候kafka出问题了或者什么出问题了,日志丢失了一部分要重新开始采集,那要怎么采集呢?
input {
file{
type => "type"
path => ["/mnt/logs/nginx/main.*.log"]
start_position => "beginning" #让其从文件的起始位置开始读取而不是从新写入的位置开始读取
sincedb_path => "/dev/null" #该参数用来指定 sincedb 文件名,但是如果我们设置为 /dev/null这个 Linux 系统上特殊的空洞文件,那么 logstash 每次重启进程的时候,尝试读取 sincedb 内容,都只会读到空白内容,也就会理解成之前没有过运行记录,自然就从初始位置开始读取了!
}
}3.2 Logstash从kafka采集信息的问题
#本来想开个单张说一下logstash与kafka之间的调用,毕竟kafka作为中间缓存层也是我们消息生产和消费重要的中转站,我们的采集架构也是围绕着kafka集群采集的,这样在整个集群的耦合度不会那么强,客户端只要把信息采集到kafka,logstash可以有多台同时从kafka去采集。
#那么其实是有两个问题的,第一个问题就是直接从kafka集群采集出来的信息跟filebeat直接发过来的日志信息是不一样的,它会在整个消息的最外层又包一层message:{filebeat上传的日志},我擦这时你会发现你的哪些if tags判断啥的全白扯了,所有标志都被包起来了。
#那么第二个问题是一个小问题,如果想要多个logstash进程配置成相同的group_id和topic,前提要把相应的topic分成多个patitions(区)一般kafka集群都会将一个topic设置程多分区的。多个消费者是无法保证消息的消息顺序性。kafka的消息模型是对topic分区达到分布式的效果的,每个topic下的不同的partitions只能有一个Owner去消费。所以只有多个分区后才能启动多个消费者,对应不同的区去消费。其中协调消费部分是由server端协调而成。不必使用考虑太多。只是消息的消费则是无序的。
#如果要保证消息的顺序,那就只用一个partitions。kafka的每个parititions只能同时被同一个group中的一个consumer消费。
下面是配置:
input {
kafka {
client_id => "logstash_51niux"
codec => plain{charset=>"UTF-8"}
topics => ["Data_Nginx_Access"]
group_id => "business-security-cluster"
bootstrap_servers => "192.168.1.141:9092,192.168.1.142:9092,192.168.1.143:9092,192.168.1.144:9092,192.168.1.145:9092"
type => "51niux_access"
#codec => "plain" #与Shipper端output配置项一致,即logstash 采用转发的形式,不会对原有信息进行编码转换。
consumer_threads => 5
auto_commit_interval_ms => "1000"
#codec => json { #或者在input这里进行将数据转换成json格式,就可以解析kafka中json字符串json解析,那么最外层的message{}就没了
# charset => "UTF-8"
#}
}
}
filter {
if "51niux_access" == [type]{
json {
source => "message" #json数据在message字段中,将会从message字段中解析json数据
}
grok { #这里就又恢复到以前filebeat采集上来的那种信息格式了
patterns_dir => "/home/work/elk/logstash/patterns"
match => {
"message" => "%{HTTP_ACCESS}"
}
}
}3.3 Logstash往kafka插入信息
#logstash-kafka 插件输入和输出默认codec 为 json 格式。在输入和输出的时候注意下编码格式。消息传递过程中 logstash 默认会为消息编码内加入相应的时间戳和 hostname 等信息。如果不想要以上信息(一般做消息转发的情况下),可以使用以下配置
output {
if [type] == "51niux" {
kafka{
codec => plain {
format => "%{message}"
}
bootstrap_servers => "192.168.1.141:9092,192.168.1.142:9092,192.168.1.143:9092"
topic_id => "Input_Nginx_Access"
}
}
}3.4 Logstash同时启动多端口引用多配置文件
#Logstash可以同时启动多个端口:
input {
beats {
id => "51niux_resin_log"
port => 6043
}
beats{
port => 6044
}
beats {
type => 51niux_nginx_log
id => "v3"
port => 6045
}
}#Logstash可以同时引用多个配置文件,这样没必要将所有的配置都记录到一个配置文件中
#mkdir /home/work/elk/logstash/conf.d #这样配置文件都放到这个目录下面就可以了
$ cat /home/work/scripts/logstash/run.sh
#!/bin/bash if [ `ps -ef|grep logstash|grep -v grep|wc -l` -eq 0 ];then cd /home/work/scripts/logstash nohup ./setup.py /home/work/elk/logstash/bin/logstash -f /home/work/elk/logstash/conf.d/ --config.reload.automatic >/dev/null 2>&1 & fi
#--config.reload.automatic #为了可以自动检测配置文件的变动和自动重新加载配置文件,需要在启动的时候使用这个命令,默认是3秒检测一次,可以通过以下命令改变--config.reload.interval <second>如果已经运行了没有提供自动重启的logstash,可以发送一个挂起命令给logstash重新加载配置文件:kill -1 <pid>。
#配置文件自动重载工作原理 检测到配置文件变化 通过停止所有输入停止当前pipline 用新的配置创建一个新的管道 检查配置文件语法是否正确检查所有的输入和输出是否可以初始化 检查成功使用新的pipeline替换当前的pipeline, 检查失败,使用旧的继续工作.在重载过程中,jvm没有重启. 注意事项 stdin输入插件不支持自动重启. syslog作为输入源,当重载配置文件时,会崩溃
filebeat如何向Kafka插入呢?
filebeat.prospectors: - input_type: log paths: - /mnt/logs/access*.log tags: ["nginx-access","51niux"] scan_frequency: 30s #Filebeat每隔scan_frequency时间读取一次文件内容。对于关闭的文件,如果后续有更新,则经过 scan_frequency 时间后,Filebeat 将重新打开该文件,读取新增加的内容,默认是10秒钟 ignore_older: 48h #默认值为0,禁用该设置。注释掉配置与将其设置为0具有相同的效果。这里的意思是早于48小时以上的文件不采集,当一个目录下面有多个文件的时候这个参数非常有效。 clean_inactive: 72h #还是针对目录里面有多日志文件这里很有效,清理72小时之前日志在data/registry里的记录,这样可以防止Registry file 过大里面的记录越来越多。 exclude_lines: ['ua=\[-\]','GET /health'] #这里是在忽略一些带有类似关键字的字段,我这里就是忽略一些探测URL是否正常的日志记录,减少无用日志的采集。 output.kafka: hosts: ["192.168.1.1441:9092","192.168.1.142:9092","192.168.1.143:9092","192.168.1.144:9092","192.168.1.145:9092"] topic: Input_Nginx_Access compression_level: 6 name: "192.168.1.151"
